Probamos Chat GPT para la traducción: estos son los datos


Todo el mundo habla de cómo la IA está transformando la traducción, pero ¿puede realmente manejar los matices del lenguaje humano?
Una investigación reciente de Bureau Works puso esto a prueba, comparando GPT-3 con los principales motores de Traducción automática de Google, Amazon y Microsoft. El estudio se centró en uno de los retos más difíciles de la localización: las expresiones idiomáticas. ¿Por qué? Porque las traducciones literales no son suficientes cuando se trata de frases como "El secreto se ha revelado" o "Vamos a dar por terminado el día".
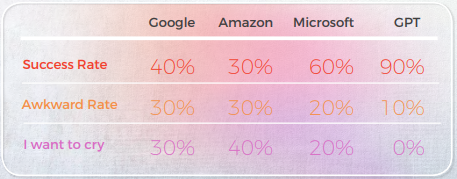
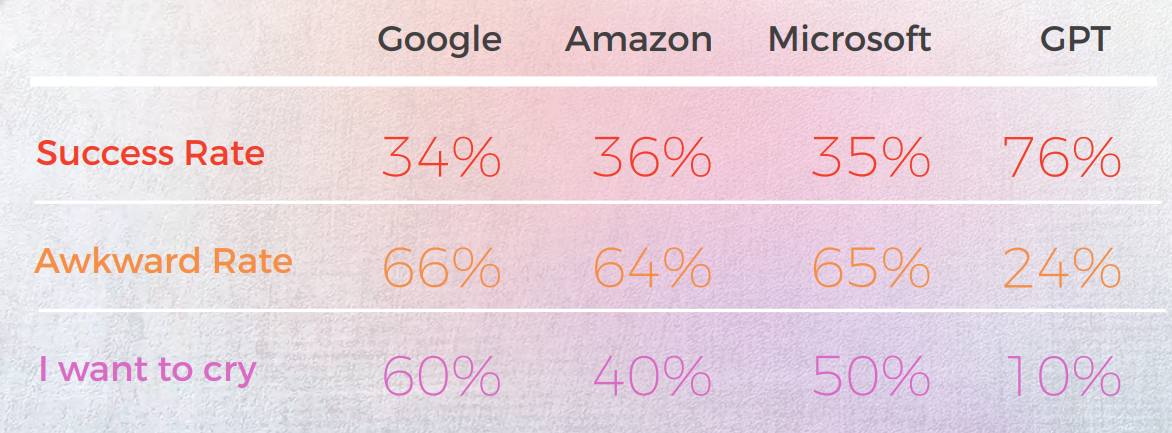
Los resultados fueron sorprendentes. GPT-3 ofreció traducciones precisas y que sonaban naturales hasta el 90% de las veces, mientras que los motores tradicionales oscilaban entre el 20% y el 50%, y a menudo producían resultados vergonzosos calificados como "Quiero llorar" por los lingüistas nativos.
En un mundo en el que los matices lingüísticos pueden hacer o deshacer su mensaje, estos hallazgos destacan tanto la promesa como las limitaciones actuales de la IA en la traducción profesional.
Aquí hay un resumen de nuestros hallazgos clave:
- GPT-3 superó sistemáticamente a los motores de traducción automática tradicionales (Google, Amazon, Microsoft) en el manejo de expresiones idiomáticas, alcanzando una precisión de hasta el 90% en idiomas como el portugués y el chino.
- Los motores tradicionales luchaban con la metáfora y el lenguaje figurado, a menudo entregando traducciones literales que eran gramaticalmente correctas pero semánticamente incorrectas, algunas incluso obteniendo calificaciones de "Quiero llorar" de los revisores nativos.
- Microsoft asumió más riesgos, ofreciendo traducciones más audaces que a veces se desviaban del original pero se sentían más naturales, aunque GPT tuvo más dificultades para evaluar estas opciones creativas.
- El análisis cualitativo de GPT fue sólido, pero tuvo dificultades para asignar puntuaciones numéricas consistentes, especialmente al diferenciar entre calificaciones de rango medio como 3 frente a. 4.
- En casi todos los idiomas, la segunda iteración de GPT, cuando se le pidió una versión más figurativa, mejoró la claridad, el tono y el ajuste cultural.
- El coreano fue el idioma más desafiante, tanto para los MT tradicionales como para GPT-3, mostrando un rendimiento significativamente menor en todos los ámbitos.
- GPT-3 demostró ser valioso no solo como traductor sino también como herramienta para evaluación y revisión, ayudando a señalar frases incómodas o inexactas y ofreciendo alternativas.
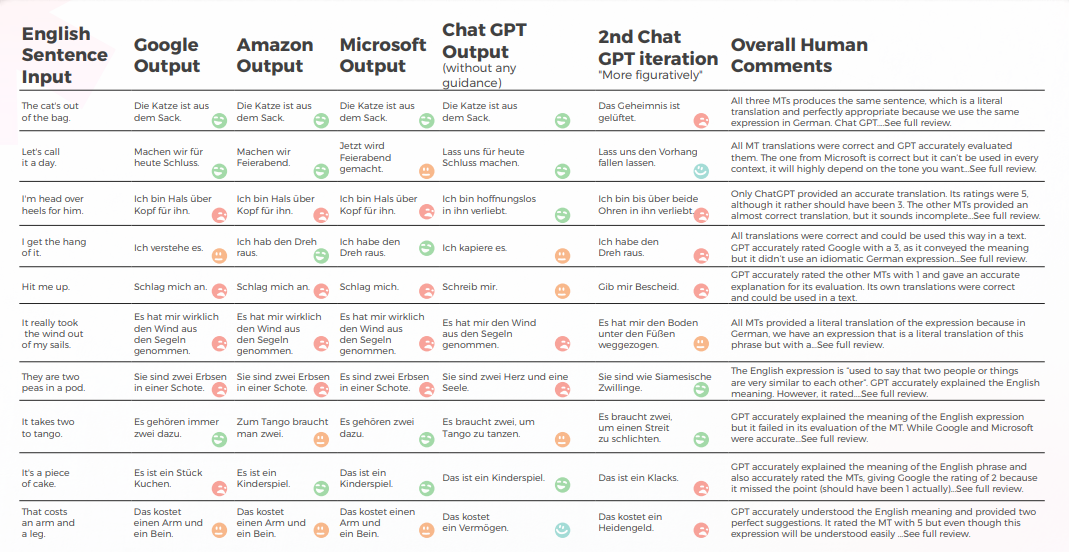
GPT logró un 90% de precisión en modismos chinos—los MTs tuvieron dificultades
El siguiente análisis fue escrito por nuestro lingüista de inglés/chino James Hou.

En general, todos los motores luchaban con la naturaleza metafórica del lenguaje, a menudo pecando de excesiva literalidad. Por ejemplo, la traducción "llamémoslo un día"." es una traducción más literal y algo incómoda de "Let's call it a day". Transmite el significado de la frase original, pero la redacción es algo incómoda y puede que no sea tan fácil de entender para los hablantes nativos de chino.
Si bien transmite con precisión el significado de la frase original, la redacción es algo incómoda y puede ser menos clara para los hablantes nativos.
Salida desde una Perspectiva Cualitativa
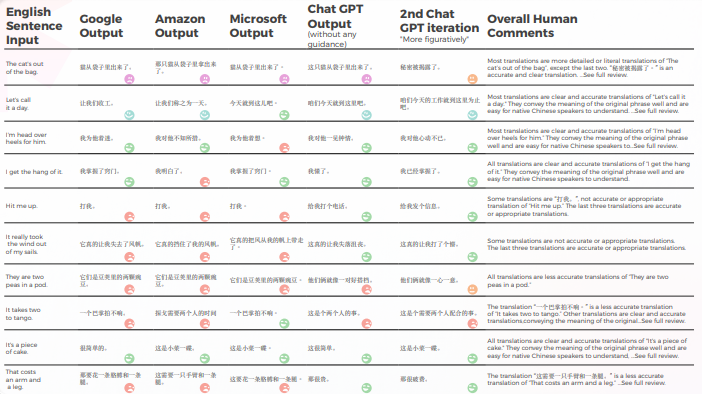
La tabla a continuación presenta un análisis sintético de 10 oraciones con modismos en inglés traducidas al chino, realizado por nuestro equipo de lingüistas.
En cuanto a la calidad de la traducción, GPT hizo un gran trabajo con la contextualización. Por ejemplo, "秘密被揭露了"."Es un secreto a voces" es una traducción precisa y clara de "The cat’s out of the bag". En 9 de cada 10 oraciones, el contenido estaba bien adaptado, era inteligible y transmitía el significado apropiado. Contrario a los tres motores de Traducción automática, GPT no tuvo errores embarazosos de “quiero llorar”.
La tabla a continuación contiene el análisis de los datos brutos.
Evaluación de GPTs Evaluación
Análisis y Clave Hallazgos
- Google y Amazon tuvieron resultados extremadamente similares, solo desviándose ligeramente entre sí, reflejando los errores y elecciones metafóricas del otro. Por ejemplo, la traducción "打我"." no es una traducción precisa o apropiada de "Hit me up". La frase “Hit me up” significa Contacto o ponerse en contacto con alguien, típicamente por teléfono o mensaje de texto. La frase china "打我" significa "golpéame" y no transmite el significado de la frase original.
- Microsoft tomó decisiones más audaces en lo que respecta a la adaptación lingüística de los modismos.
- GPT tuvo más dificultades para evaluar las elecciones metafóricas de Microsoft a medida que se alejaban más.
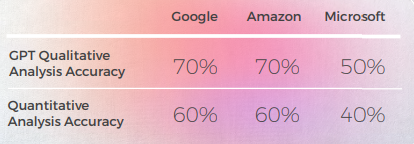
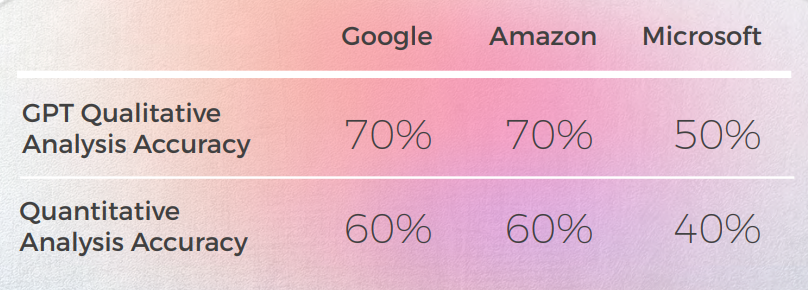
- GPT-3 lo tuvo más fácil con el análisis cualitativo, produciendo un análisis textual convincente (aunque con solo un 70% de precisión).
- Aunque comprensible, el análisis de GPT no logró identificar en el 30% de los casos. Esto coincidió con elecciones metafóricas que eran literales y comprensibles, pero que se desviaban del discurso cotidiano.
- GPT-3 tuvo más dificultades para traducir el análisis cualitativo en una puntuación. Aunque en términos generales las puntuaciones tuvieron una precisión del 60%, fue difícil diferenciar entre puntuaciones similares, como un 3 frente a un 4.
- La divergencia extrema de la puntuación de 1 a 5 fue más fácil de entender y más compatible con los comentarios generales que sugerían que:
- Tal vez los criterios de puntuación no estaban suficientemente calibrados con GPT-3
- Quizás la puntuación binaria podría ser más relevante que la puntuación de gradiente
- Aunque cuantitativamente Microsoft tuvo un rendimiento similar al de Google y Amazon, cuando se entra en el meollo del lenguaje, Microsoft tomó decisiones más audaces y proporcionó mejores resultados desde una perspectiva cualitativa, pero aún así estaba muy por detrás de GPT-3 en lo que respecta a la precisión y la adaptación cultural. Por ejemplo, la traducción "He dominado el truco"." es una traducción clara y precisa de "Le cojo el tranquillo". Transmite bien el significado de la frase original y es fácil de entender para los hablantes nativos de chino. También es una forma más figurativa e idiomática de expresar la idea de comprender o dominar algo en comparación con otras traducciones posibles.
Aplicaciones prácticas y limitaciones
En este análisis, GPT-3 proporcionó una contextualización y adaptación superior a los modelos de Traducción automática anteriores.
Aunque ninguno de los motores es lo suficientemente confiable como para reemplazar a los humanos (al menos en el contexto de este estudio), GPT-3 muestra una clara capacidad para ayudar a los traductores y revisores humanos en el proceso de traducir y evaluar el idioma.
Francés: Los motores de traducción fallaron en el 60% de los modismos—GPT se destacó
El siguiente análisis fue escrito por nuestra lingüista de inglés/francés Laurène Bérard.

En general, todos los motores luchaban con la naturaleza metafórica del lenguaje, a menudo pecando de excesiva literalidad.
Salida desde una Perspectiva Cualitativa
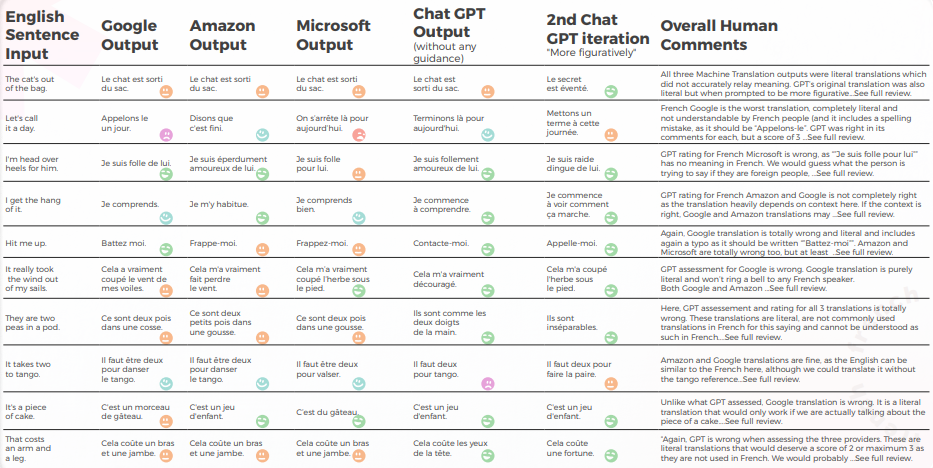
La tabla a continuación presenta un análisis sintético de 10 oraciones con modismos en inglés traducidas al francés, realizado por nuestro equipo de lingüistas.

En cuanto a la calidad de la traducción, GPT hizo un gran trabajo con la contextualización. Sin ninguna orientación, GPT estaba totalmente equivocado con "El gato está fuera de la bolsa", pero tenía razón con más orientación, y sus 3 traducciones estaban gramaticalmente incompletas, por lo que eran bastante difíciles de entender para "Se necesitan dos para bailar el tango".
El contenido estaba generalmente bien adaptado, inteligible y transmitía el significado apropiado. Los tres motores de Traducción automática tenían una alta tasa de "quiero llorar", mientras que incluso sin contexto un traductor habría adivinado que no se pretendía de manera literal (por ejemplo. "Vamos a dar por terminado el día", lo cual es bastante obvio pero fue totalmente malinterpretado por el motor de Google).
La tabla a continuación contiene el análisis de los datos brutos.
Evaluación de la Evaluación de GPTs
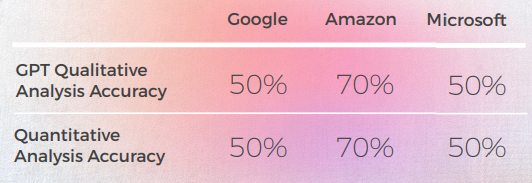
Análisis y Clave Hallazgos
- A pesar de traducir correctamente 8 veces de cada 10, el análisis de GPT de los 3 motores a menudo estaba equivocado, ya que en casi el 50% de los casos se afirmaba que su traducción estaba bien cuando no lo estaba.
- Aunque el análisis de Inteligible GPT no identificó problemas en el 30 al 50% de los casos, esto coincidió con elecciones que eran literales y habrían sido correctas si no se tratara de expresiones idiomáticas.
- GPT no detectó los dos problemas de ortografía de Google ("Appelons le" y "Battez moi").
- Los análisis cualitativos y cuantitativos de GPT fueron globalmente coherentes entre sí.
- GPT tuvo más dificultades para evaluar las traducciones de Microsoft y Google.
- Microsoft tomó mejores decisiones cuando se trata de la adaptación lingüística de los modismos.
- Google y Amazon tuvieron resultados muy similares, solo diferenciándose ligeramente entre sí. Microsoft se destacó de los dos.
- En un caso (la expresión tango), GPT evaluó una buena traducción de Microsoft como incorrecta (puntuación de 2), aunque era comprensible e igualmente buena que las traducciones de Google y Amazon, que GPT evaluó positivamente (puntuación de 5). Esto puede explicarse por el hecho de que Microsoft no fue tan literal como los otros dos motores, ya que eligió mencionar el vals en lugar del tango.
- Microsoft tomó decisiones más audaces y proporcionó mejores resultados desde una perspectiva cualitativa, pero aún estaba muy por detrás de GPT en lo que respecta a la precisión y la adaptación cultural.
Aplicaciones prácticas y limitaciones
En este análisis, GPT proporcionó una contextualización y adaptación mucho mejores que los motores de Traducción automática de Amazon, Google y Microsoft. Aunque no es conveniente reemplazar los modelos tradicionales de Traducción automática con modelos más grandes como GPT-3 debido a los altos costos computacionales y la disminución de los beneficios marginales en el discurso no metafórico, GPT-3 puede ser un poderoso aliado humano cuando se trata de proporcionar sugerencias e identificar posibles errores, así como oportunidades de mejora.
Aunque los motores de Traducción automática están “casi” allí, este “casi” se vuelve progresivamente más difícil de abordar, como lo demuestra GPT aquí.
Aunque ninguno de los motores es lo suficientemente confiable como para reemplazar a los humanos (al menos en el contexto de este estudio), GPT muestra una clara capacidad para ayudar a los traductores humanos y revisores en el proceso de traducir y evaluar el idioma.
GPT superó a todos los motores de traducción automática en modismos alemanes por un 30%
El siguiente análisis fue escrito por nuestra lingüista de inglés/alemán Olga Schneider.

En general, GPT produjo la traducción más precisa. Siempre analizaba la oración en inglés con precisión y generalmente podía decir si una Traducción automática era literal o idiomática, pero no lograba detectar una mala traducción el 50% del tiempo.
Salida desde una Perspectiva Cualitativa
La tabla a continuación presenta un análisis sintético de 10 oraciones con modismos en inglés traducidas al alemán, realizado por nuestro equipo de lingüistas.

GPT produce buenos resultados 8 de cada 10 veces en el primer intento y 7 de cada 10 veces en el segundo intento. Por ejemplo, solo GPT fue capaz de proporcionar traducciones idiomáticas precisas para "Estoy locamente enamorada de él" y "Contáctame".
La última producción, la más figurativa, produjo 4 buenas oraciones, y las otras fueron "todo bien" o "quiero llorar". En general, Amazon y Microsoft produjeron traducciones ligeramente mejores que Google.
La tabla a continuación contiene el análisis de los datos brutos.
Evaluación de la Evaluación de GPTs
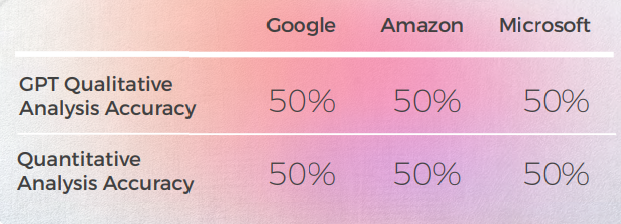
Análisis y Clave Hallazgos
- GPT tiene un conocimiento bastante bueno de las expresiones idiomáticas alemanas, incluso aquellas que no coincidían exactamente con la oración en inglés eran expresiones idiomáticas de una categoría similar. Por ejemplo: "Vamos a desenchufar" y "Vamos a bajar el telón" por "Vamos a dar por terminado el día". Entiende el significado general de estas frases relacionadas con "final" y podría ser una fuente útil de inspiración.
- Cuando se trata de expresiones creativas, GPT parece inspirarse en frases en inglés, sugiriendo la traducción literal al alemán de "Estoy enamorado de él de la cabeza a los pies" como una alternativa creativa a "Estoy locamente enamorado de él".
- Las calificaciones de traducción de GPT fueron impredecibles y resultaron ser poco fiables. En un caso, calificó una traducción de Google con un 2, y no estaba claro por qué no era el 1 que debería haber sido.
- El alemán y el inglés comparten muchas expresiones idiomáticas, lo que facilita la traducción. Pero las expresiones que son extrañas al alemán (p. ej. "Son como dos gotas de agua" o "Es pan comido") se terminan traduciendo literalmente. En el caso de los guisantes, a diferencia de los motores de traducción, GPT entendió que necesitaba proporcionar expresiones sobre "pares". Sin embargo, las expresiones que proporcionó, aunque precisas y de uso común, no transmitían el significado correcto.
Aplicaciones prácticas y limitaciones
GPT proporcionó mejores traducciones que Google, Amazon y Microsoft. Aunque no es 100% confiable, puede proporcionar un mejor punto de partida para la edición de Traducción automática que los otros tres motores. Aunque las expresiones idiomáticas son importantes, hay otro problema que a menudo se encuentra en la Traducción automática de texto del inglés al alemán: una estructura de oración engorrosa que está demasiado cerca del texto original. Sería importante ver cómo GPT resuelve este problema.
Cuando se trata de evaluación, GPT no es una buena herramienta, ya que su evaluación de las traducciones al alemán solo tiene una precisión del 50%.
Tres cosas más habrían sido interesantes de ver:
- ¿Puede GPT competir con DeepL por el alemán? Aunque GPT puede proporcionar buenas traducciones, DeepL produce buenas traducciones al alemán y también ofrece una variedad de funciones que simplifican el proceso de traducción (términos de glosario traducidos correctamente con el plural y caso correctos, edición con un solo clic, autocompletar oraciones después de escribir una o dos palabras para acelerar la reformulación). La traducción de GPT necesita ser significativamente mejor que la de DeepL para compensar la falta de funciones.
- ¿Podría mejorarse la precisión de GPT con más contexto, como un párrafo que contenga la frase?
- Si Google es capaz de reconocer el texto generado por la IA, ¿cómo gestionará las traducciones de GPT con una edición mínima o nula? ¿Puede detectar el "estilo GPT" y penalizar un texto en sus resultados de búsqueda?
En resumen, en su estado actual, GPT puede ser una fuente de inspiración para nuestros limitados cerebros humanos. Puede proporcionar traducciones decentes. Más que eso, puede ayudarnos a reformular expresiones usadas en exceso, encontrar metáforas y pensar fuera de la caja.
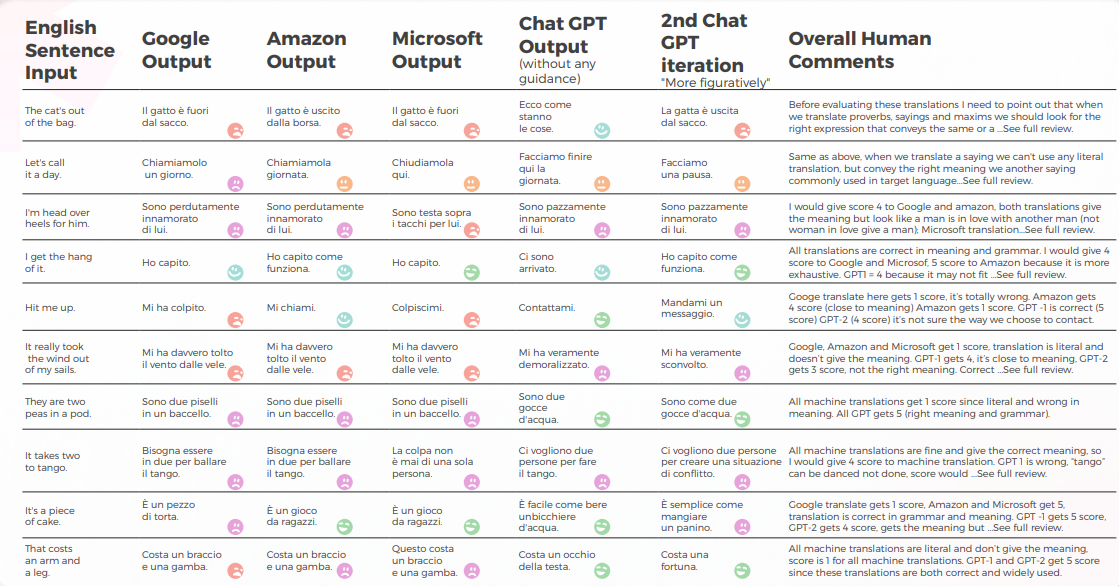
Italiano: Los motores de traducción automática devolvieron traducciones literales en el 70% de los casos
El siguiente análisis fue escrito por nuestra lingüista de inglés/italiano Elvira Bianco.

En general, todos los motores luchaban con la naturaleza metafórica del lenguaje, a menudo pecando de excesiva literalidad.
Salida desde una Perspectiva Cualitativa
La tabla a continuación presenta un análisis sintético de 10 oraciones con modismos en inglés traducidas al italiano, realizado por nuestro equipo de lingüistas.
La Traducción automática dio una traducción literal muy alejada del significado correcto. GPT transmitió el significado y la expresión correctos en un 70%, mientras que el 30% restante utilizó expresiones aceptables que no se utilizan ampliamente ni se perciben como el habla nativa natural.
La tabla a continuación contiene el análisis de los datos brutos.
Evaluación de GPTs Evaluación

Análisis y Clave Hallazgos
- Google Translate obtiene solo una traducción correcta y se acerca al significado en 2 oraciones.
- Amazon dio el 50% del significado correcto, incluso si no utilizó la forma más común de transmitir el dicho inglés en el idioma italiano.
- Microsoft dio 3 respuestas correctas acercándose a dichos similares italianos.
- Aunque el 1er Chat GPT generalmente aprueba las Traducción automática, el 2do y 3er Chat GPT generalmente dan el significado correcto y añaden valiosas sugerencias de traducción.
Aplicaciones prácticas y limitaciones
Según la definición de https://it.wiktionary.org/wiki/espressione_idiomatica, una expresión idiomática típica de un idioma generalmente no se puede traducir literalmente a otros idiomas, excepto recurriendo a expresiones idiomáticas del idioma al que se traduce, con significados similares a las expresiones idiomáticas del idioma del que se traduce. Claramente, la traducción mecánica producida por las máquinas de traducción más utilizadas hoy en día (Google, Amazon, Microsoft) era poco fiable, sin embargo, GPT-3 demostró ser capaz en un 70% de dar el significado correcto y proporcionar buenas sugerencias en la adaptación de contenido.
No es improbable que en un futuro próximo las máquinas también memoricen expresiones idiomáticas, pero en este momento necesitamos que los humanos traduzcan, transmitiendo el mismo significado de un idioma a otro.
Los idiomas están llenos de matices, dobles sentidos, alusiones, modismos, metáforas que solo un humano puede percibir.
El coreano tuvo la precisión más baja entre todos los motores probados
El siguiente análisis fue escrito por nuestros lingüistas de inglés/coreano Sun Min Kim.

Salida desde una Perspectiva Cualitativa
La tabla a continuación presenta un análisis sintético de 10 oraciones con modismos en inglés traducidas al coreano, realizado por nuestro equipo de lingüistas.
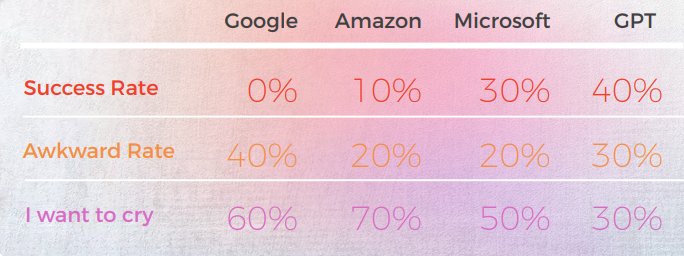
La mayoría de los motores traducen literalmente las expresiones idiomáticas, mientras que GPT intenta traducir de manera lo más descriptiva posible sin usar metáforas (por ejemplo, pedazo de pastel = fácil, mientras que en Corea, tenemos una expresión idiomática similar que transmite el mismo significado que Microsoft.
Las tres traducciones de GPT no son coherentes. Algunos están empeorando con la iteración.
La tabla a continuación contiene el análisis de los datos brutos.
GPT conoce los problemas cuando las traducciones salen mal. Pero no se considera correcto al juzgar al mejor.
El propio GPT tiene problemas con el tratamiento formal-informal, etc.) y puede evaluar este problema.
Evaluación de la Evaluación de GPTs

Análisis y Clave Hallazgos
Debido a que los originales en inglés de este estudio son expresiones idiomáticas, es un poco complicado porque tienes que elegir entre la metáfora o la descripción directa. Pero para algunas expresiones idiomáticas en las que el idioma coreano tiene una expresión idiomática similar que transmite el mismo significado, la mayoría de los motores no lograron encontrar esas expresiones con solo unas pocas excepciones (consulte la hoja de trabajo y encuentre las que tienen una puntuación de 5 por mí).
Para otras, mi pensamiento personal es que si la metáfora en sí misma puede transmitir el significado, se puede considerar una traducción literal de la misma y tal vez sea mejor usar una palabra descriptiva. Por supuesto, si la metáfora no tiene contexto cultural en Corea, no debería traducirse literalmente. Pero es un tema sutil y tal vez dependa de la preferencia o las emociones humanas del traductor. No creo que ningún motor tenga ese nivel de pensamiento similar al humano todavía.
Aplicaciones prácticas y limitaciones
Creo que la mayoría de los motores se pueden utilizar con fines de pretraducción. Pero considerando la calidad, debería ser principalmente para el propósito de eficiencia solamente (es decir, no escribir desde cero). Para textos más descriptivos, como manuales, veo que MTPE es mucho más avanzado que estas expresiones idiomáticas. Por lo tanto, todavía hay margen para mejorar.
GPT alcanzó una tasa de éxito del 90% en modismos del portugués brasileño
El siguiente análisis fue escrito por nuestro lingüista de inglés/portugués Gabriel Fairman.

En general, todos los motores luchaban con la naturaleza metafórica del lenguaje, a menudo pecando de excesiva literalidad.
Salida desde una Perspectiva Cualitativa
La tabla a continuación presenta un análisis sintético de 10 oraciones con modismos en inglés traducidas al portugués, realizado por nuestro equipo de lingüistas.
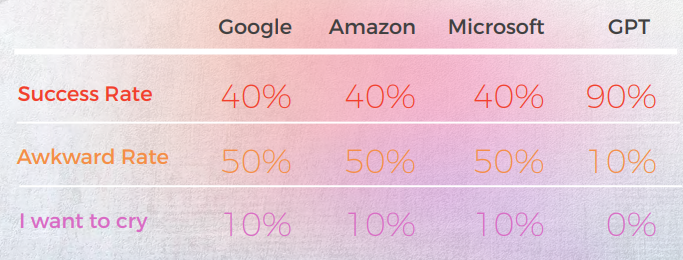
La mayoría de los motores traducen literalmente las expresiones idiomáticas, mientras que GPT intenta traducir de manera lo más descriptiva posible sin usar metáforas (por ejemplo, pedazo de pastel = fácil, mientras que en Corea, tenemos una expresión idiomática similar que transmite el mismo significado que Microsoft.
Las tres traducciones de GPT no son coherentes. Algunos están empeorando con la iteración.
La tabla a continuación contiene el análisis de los datos brutos.
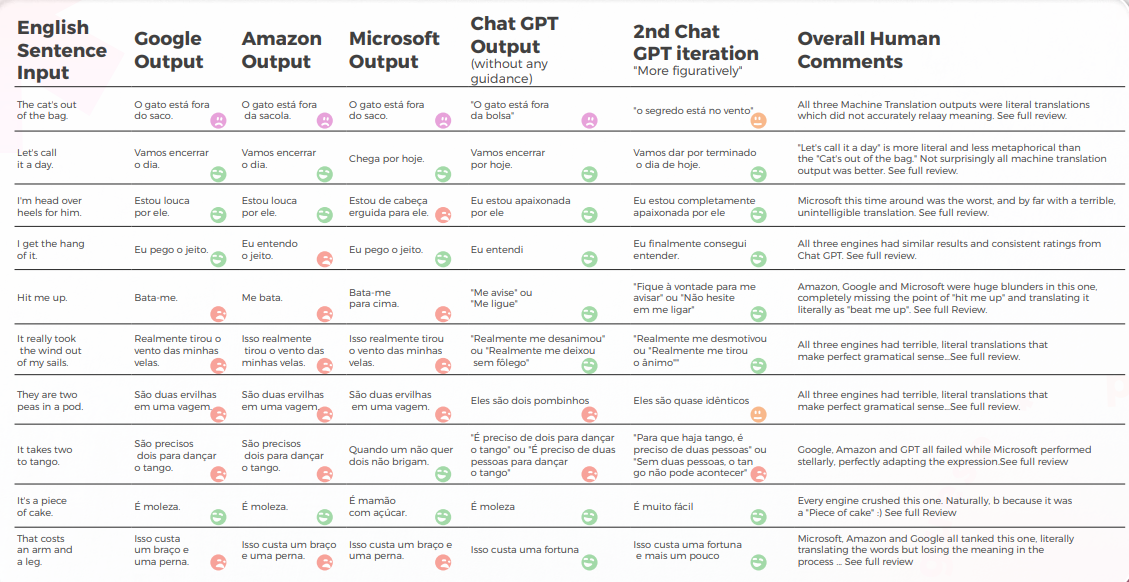
En cuanto a la calidad de la traducción, GPT hizo un gran trabajo con la contextualización. En 9 de cada 10 oraciones, el contenido estaba bien adaptado, era inteligible y transmitía el significado apropiado. Contrario a los tres motores de Traducción automática, GPT no tuvo errores embarazosos de “quiero llorar”.
La hipótesis inicial era que habría una gran diferencia en calidad entre la primera y la segunda iteración de GPT, pero la calidad de la traducción fue similar en ambas.
Evaluación de la Evaluación de GPTs
Análisis y Clave Hallazgos
- Microsoft hizo elecciones más audaces en lo que respecta a la adaptación lingüística de los modismos.
- GPT tuvo más dificultades para evaluar las elecciones metafóricas de Microsoft a medida que se alejaban más.
- Google y Amazon tuvieron resultados extremadamente similares, solo se desviaron ligeramente el uno del otro, reflejando los errores y las elecciones metafóricas del otro. Microsoft se destacó claramente de los dos.
- GPT-3 lo tuvo más fácil con el análisis cualitativo, produciendo un análisis textual convincente (aunque con solo un 70% de precisión).
- Aunque comprensible, el análisis de GPT no logró identificar en el 30% de los casos. Esto coincidió con elecciones metafóricas que eran literales y comprensibles, pero que se desviaban del discurso cotidiano.
- GPT-3 tuvo más dificultades para traducir el análisis cualitativo en una puntuación.
- Aunque en términos generales las puntuaciones tuvieron una precisión del 60%, fue difícil diferenciar entre puntuaciones similares, como un 3 frente a un 4.
- La divergencia extrema de la puntuación de 1 a 5 fue más fácil de entender y más compatible con los comentarios generales que sugerían que:
- Quizás los criterios de puntuación no estaban suficientemente calibrados con GPT-3
- Quizás la puntuación binaria podría ser más relevante que la puntuación de gradiente. En un caso anómalo, Cchat GPT-3 evaluó dos traducciones similares de maneras radicalmente diferentes, dando a una un 1 y a la otra un 5, cuando ambas deberían haber sido 1.
- Aunque cuantitativamente Microsoft tuvo un rendimiento similar al de Google y Amazon, cuando se entra en el meollo del lenguaje, Microsoft tomó decisiones más audaces y proporcionó mejores resultados desde una perspectiva cualitativa, pero aún así estaba muy por detrás de GPT-3 en lo que respecta a la precisión y la adaptación cultural.
Aplicaciones prácticas y limitaciones
En este análisis, GPT-3 proporcionó una contextualización y adaptación superior a los modelos anteriores de
Traducción automática en portugués brasileño. Aunque no es conveniente reemplazar los modelos tradicionales de Traducción automática con modelos más grandes como GPT-3 debido a los altos costos computacionales y la disminución de los rendimientos marginales cuando se trata de discursos no metafóricos, GPT-3 puede ser un poderoso aliado humano al proporcionar sugerencias e identificar posibles errores, así como oportunidades de mejora.
Los casos lingüísticos extremos son sorprendentes porque ilustran claramente cuánto queda en tan poco cuando se trata de modelos lingüísticos. A pesar de que están "casi" allí, este "casi" se vuelve progresivamente más difícil de abordar y, si no más difícil, definitivamente más costoso desde una perspectiva computacional.
Aunque ninguno de los motores es lo suficientemente confiable como para reemplazar a los humanos (al menos en el contexto de este estudio), GPT-3 muestra una clara capacidad para ayudar a los traductores y revisores humanos en el proceso de traducir y evaluar el idioma.
Los MTs de español obtuvieron menos del 30%—GPT fue el claro ganador
El siguiente análisis fue escrito por nuestros lingüistas de inglés/español, Nicolas Davila.

En general, todos los motores luchaban con la naturaleza metafórica del lenguaje, a menudo pecando de excesiva literalidad.
Salida desde una Perspectiva Cualitativa
La tabla a continuación presenta un análisis sintético de 10 oraciones con modismos en inglés traducidas al español, realizado por nuestro equipo de lingüistas.

En lo que respecta a la calidad de la traducción, GPT hizo un trabajo aceptable y mejor que los demás en cuanto a contextualización. En 7 de cada 10 oraciones, el contenido era inteligible, bien formado y transmitía el significado apropiado, con baja incomodidad y tasas de "quiero llorar".
Aunque la hipótesis inicial era que habría una gran diferencia en calidad entre la primera y las siguientes iteraciones de GPT, la calidad de la traducción es similar en todas ellas, las iteraciones 2ª y 3ª a veces añaden cosas innecesarias, aumentando un poco la tasa de incomodidad.
La tabla a continuación contiene el análisis de los datos brutos.
Evaluación de la Evaluación de GPTs

Análisis y Clave Hallazgos
- Las traducciones automáticas fueron demasiado literales, siendo Amazon y Google muy similares en términos generales, y Microsoft siendo el peor.
- Google y Amazon tuvieron resultados extremadamente similares, solo se desviaron ligeramente el uno del otro, reflejando los errores y las elecciones metafóricas del otro. Microsoft tuvo un desempeño deficiente, a veces produciendo oraciones mal formadas y faltando algunas partes de la construcción gramatical.
- A GPT-3 le resultó más fácil con el análisis cualitativo producir un análisis textual coherente, aunque con sólo un 50% de precisión.
- Con frecuencia, el análisis cualitativo de GPT-3 era demasiado general y más restringido al significado principal y literal de la oración, sin considerar los detalles sutiles de la construcción y el cambio en el significado. Parece que GPT no es capaz de detectar estas diferencias y traducirlas en puntuaciones cuantitativas.
- Además, GPT asignó con frecuencia el mismo análisis cualitativo y una puntuación cuantitativa alta a las oraciones que estaban gramaticalmente mal construidas, lo que parece ser una limitación del modelo de GPT.
- GPT-3 tuvo más dificultades para traducir el análisis cualitativo en una puntuación.
- Siendo solo un 50% de precisión para Google y Amazon y solo un 30% de precisión para Microsoft. Parece que GPT solo estaba midiendo si la oración transmitía el significado, pero no había diferencias en la construcción o en la buena formación.
- La divergencia de la puntuación de 1 a 5 fue más fácil de entender y más compatible con los comentarios generales que sugerían que: Quizás los criterios de puntuación no estaban suficientemente calibrados para GPT-3. Quizás la puntuación binaria podría ser más relevante que la puntuación de gradiente. Quizás los criterios de puntuación o el modelo GPT no estaban considerando las cuestiones gramaticales, sino solo transmitiendo el significado.
Aplicaciones prácticas y limitaciones
En este análisis, GPT-3 proporcionó una contextualización y adaptación superior a los modelos de Traducción automática anteriores en español de Latam.
GPT-3 podría ser una herramienta poderosa para ayudar a los humanos a mejorar las traducciones cuando se refiere a proporcionar sugerencias útiles y oportunidades de mejora. Pero, por lo que puedo ver, todavía tiene ciertas limitaciones.
Aunque modelos más grandes como GPT-3 podrían ser útiles, no es conveniente reemplazar los modelos tradicionales de Traducción automática con ellos, debido a los mayores costos computacionales, ya que cuando se trata de texto no metafórico podría disminuir las ganancias marginales.
Aunque GPT-3 muestra una clara capacidad para ayudar a los traductores humanos y revisores en el proceso de traducir y evaluar el lenguaje, se deben incluir consideraciones de costo al evaluar su uso para textos no metafóricos.
Conclusiones
Aunque el rendimiento de ChatGPT puede variar según el aviso y el idioma específico, nuestro estudio sugiere que ChatGPT tiene el potencial de producir traducciones de mayor calidad que los motores de traducción automática tradicionales, especialmente cuando se trata de manejar expresiones idiomáticas y el uso matizado del lenguaje.
Sin embargo, es importante tener en cuenta que ChatGPT está lejos de no cometer errores y todavía tiene un inmenso margen de mejora, especialmente cuando se trata de indicaciones o dominios lingüísticos más complejos.
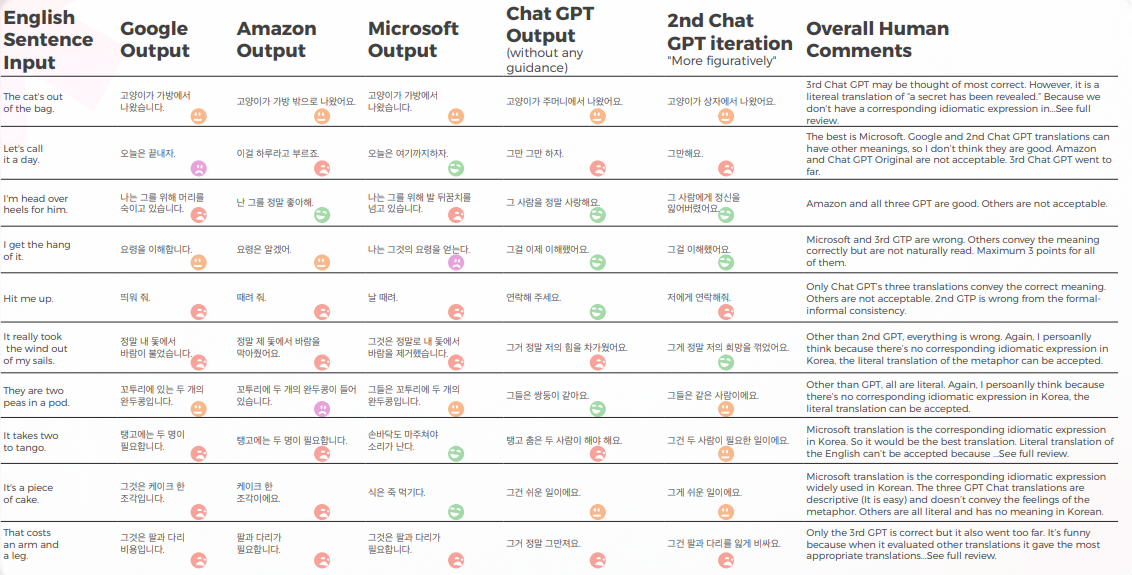
Como traductor, ChatGPT tuvo más éxito que todos los motores de Traducción automática probados. Aunque los idiomas mostraron resultados diferentes, el coreano fue claramente el caso atípico con la calidad de MT y la calidad de GPT significativamente más baja que otros idiomas.
En todos los idiomas, excepto en coreano, ChatGPT tuvo al menos una tasa de éxito del 70% y como máximo una tasa de éxito del 90%, con un rendimiento mejor que la traducción automática tradicional. E incluso en coreano, aunque las puntuaciones eran bajas, seguían siendo mejores que la salida del motor de traducción automática.
Contrario a la Traducción automática, con un LLM, las iteraciones del mismo contenido pueden mejorar la calidad del resultado. Esto es clave al pensar en integraciones porque, mientras que con la MT tradicional tu salida siempre será la misma que tu entrada (a menos que el motor reciba más datos o entrenamiento), con un LLM se pueden explorar varias interacciones a través de la API para optimizar la calidad del feed.
Una ventaja de ChatGPT sobre los motores tradicionales de MT es su capacidad para aprender y mejorar con el tiempo, incluso sin datos de entrenamiento adicionales. Esto se debe a la naturaleza de los LLM, que están diseñados para refinar continuamente sus modelos de lenguaje en función de nuevas entradas. De este modo, ChatGPT puede ofrecer potencialmente capacidades de traducción más adaptativas y dinámicas, lo que podría ser especialmente útil en escenarios donde el idioma o contenido está en constante evolución o cambio.Otra ventaja de ChatGPT es su baja tasa de vergüenza, lo que supone una mejora significativa con respecto a los motores de traducción automática tradicionales que suelen producir traducciones incómodas o inapropiadas. Esto podría hacer que ChatGPT sea más aceptable y fácil de usar para usuarios no expertos que pueden no tener el mismo nivel de conocimiento lingüístico o cultural que los traductores profesionales.
Sin embargo, es importante señalar que ChatGPT no es un sustituto de los traductores humanos, y hay una miríada de casos donde se necesita la experiencia y el juicio de un traductor humano. Pero las tasas de vergüenza significativamente más bajas de ChatGPT abren la puerta a una adopción más amplia de traducciones impulsadas por no humanos.
Como evaluador, el rendimiento de ChatGPT fue más mixto, con tasas de precisión que oscilaron entre el 30% y el 70%. Aunque esto sugiere que ChatGPT puede no ser tan efectivo al evaluar otros motores de traducción como lo es al sugerir traducciones, es posible que esto se deba a la complejidad y calidad de los mensajes de evaluación, que pueden requerir un conocimiento más especializado o contextual del que ChatGPT posee actualmente. Se necesita más investigación para explorar el potencial de ChatGPT como evaluador, así como sus limitaciones y desafíos.
En general, nuestro estudio sugiere que ChatGPT tiene capacidades de traducción prometedoras que vale la pena explorar más a fondo. Si bien puede que no sea capaz de reemplazar o eludir por completo a los traductores humanos, podría ofrecer beneficios significativos como una ayuda o herramienta de pretraducción, especialmente en escenarios donde el tiempo, los recursos o la experiencia son limitados.
Como con cualquier tecnología emergente, todavía hay muchos desafíos y oportunidades de mejora, y se necesitará más investigación y experimentación para desbloquear completamente su potencial.
Metodología
Para explorar cómo los modelos de lenguaje como GPT-3 manejan la traducción idiomática en comparación con los motores de Traducción automática tradicionales, realizamos un experimento centrado en casos límite lingüísticos que involucran metáforas y expresiones idiomáticas.
Selección de expresiones idiomáticas
Seleccionamos 10 modismos ingleses de uso común, como "Let's call it a day", "Hit me up" y "The cat's out of the bag". Estas expresiones son bien conocidas por desafiar a los sistemas de traducción, ya que requieren adaptación cultural y contextual en lugar de equivalencia literal.
Motores y modelos de traducción probados
Cada modismo se tradujo usando:
- Google Translate
- Amazon Translate
- Microsoft traductor
- GPT-3 (ChatGPT) – usando dos enfoques:
- Una traducción directa sin ninguna orientación
- Una segunda versión instó a ser más figurativa e idiomática

Proceso de evaluación
Los resultados traducidos fueron revisados por lingüistas nativos en siete idiomas de destino: Portugués brasileño, español, francés, alemán, italiano, chino y coreano. Para cada oración, los revisores evaluaron:
- Si se conservó el significado de la expresión original
- La naturalidad de la expresión en el idioma de destino
- Gramática, sintaxis y precisión semántica
Cada traducción se calificó en una escala de 1 a 5:
- 5: Significado correcto y lenguaje que suene natural
- 1: Traducción incorrecta, confusa o poco natural (nivel "Quiero llorar")
Además, le pedimos a ChatGPT que evaluara las traducciones de los otros motores, tanto proporcionando comentarios textuales cualitativos como puntuaciones numéricas. Esto nos permitió evaluar su capacidad como evaluador, no solo como generador de traducciones.
Limitaciones del estudio
Es importante tener en cuenta que este fue un estudio exploratorio:
- La muestra se limitó a 10 modismos con un revisor humano por idioma.
- Todas las evaluaciones conllevan un grado de subjetividad y preferencia individual.
- El rendimiento de GPT-3 refleja una versión específica del modelo y puede evolucionar con las actualizaciones.
A pesar de estas limitaciones, los hallazgos proporcionan información valiosa sobre las capacidades y limitaciones de los modelos actuales, especialmente en escenarios lingüísticamente matizados y culturalmente dependientes.
Descargos de responsabilidad
(Los descargos de responsabilidad de la investigación real no deben tomarse a la ligera)
Si bien nuestro objetivo era explorar el potencial de las capacidades lingüísticas de ChatGPT, es importante tener en cuenta que este estudio solo evaluó un aspecto de la traducción, a saber, la capacidad de manejar casos extremos lingüísticos idiomáticos altamente metafóricos. Otros aspectos de la traducción, como la comprensión cultural y contextual, pueden requerir diferentes métodos y criterios de evaluación.
El tamaño de la muestra de este estudio está limitado a 10 modismos y un revisor por idioma, lo cual puede no ser representativo de la gama completa de expresiones idiomáticas en el idioma inglés, o de la variedad de perspectivas y experiencia de traductores profesionales. Como tal, los resultados de este estudio deben interpretarse con cautela y no pueden generalizarse a otros contextos o dominios.
Además, las opiniones y evaluaciones del revisor único por idioma son subjetivas y pueden estar influenciadas por sesgos, experiencias o preferencias personales. Al igual que con cualquier evaluación subjetiva, existe un grado de variabilidad e incertidumbre en los resultados. Para aumentar la confiabilidad y validez de nuestros hallazgos, los estudios futuros podrían incluir múltiples revisores, evaluaciones ciegas o medidas de confiabilidad entre evaluadores.
También vale la pena señalar que las capacidades lingüísticas de ChatGPT no son estáticas y pueden cambiar con el tiempo a medida que el modelo se entrena y ajusta más. Por lo tanto, los resultados de este estudio deben considerarse como una instantánea del rendimiento del modelo en un momento específico y es posible que no reflejen sus capacidades actuales o futuras.
Por último, este estudio no pretende hacer afirmaciones definitivas o categóricas sobre la utilidad o las limitaciones de ChatGPT para la traducción. Más bien, está destinado a servir como una investigación preliminar y punto de partida para futuras investigaciones y desarrollos en el campo del procesamiento del lenguaje natural y la Traducción automática. Como con cualquier tecnología emergente, todavía hay muchos desafíos y oportunidades de mejora, y se necesitarán más experimentación y colaboración para explorar completamente su potencial.
Libere el poder de la glocalización con nuestro Sistema de Gestión de Traducciones.
Libere el poder de la
con nuestro Sistema de Gestión de Traducciones.








