Wir haben Chat GPT für die Übersetzung getestet – hier sind die Daten


Alle reden darüber, wie KI die Übersetzung verändert – aber kann sie wirklich mit den Nuancen der menschlichen Sprache umgehen?
Kürzliche Untersuchungen von Bureau Works haben dies auf die Probe gestellt, indem sie GPT-3 mit den großen maschinellen Übersetzungsmaschinen von Google, Amazon und Microsoft verglichen haben. Die Studie konzentrierte sich auf eine der größten Herausforderungen bei der Lokalisierung: idiomatische Ausdrücke. Warum? Weil wörtliche Übersetzungen nicht ausreichen, wenn man es mit Ausdrücken wie „Die CAT ist aus dem Sack“ oder „Lassen Sie uns Schluss machen“ zu tun hat.
Die Ergebnisse waren überraschend. GPT-3 lieferte in bis zu 90% der Fälle genaue, natürlich klingende Übersetzungen, während traditionelle Engines zwischen 20% und 50% lagen – und oft peinliche Ergebnisse produzierten, die von einheimischen Linguists als „Ich möchte weinen“ bewertet wurden.
In einer Welt, in der sprachliche Nuancen Ihre Botschaft ausmachen oder zerstören können, heben diese findings sowohl das Versprechen als auch die aktuellen Einschränkungen der KI in der professionellen Übersetzung hervor.
Hier ist eine Zusammenfassung unserer Schlüsselergebnisse:
- GPT-3 übertraf herkömmliche MT-Engines (Google, Amazon, Microsoft) bei der Verarbeitung idiomatischer Ausdrücke durchweg und erreichte eine Genauigkeit von bis zu 90% in Sprachen wie Portugiesisch und Chinesisch.
- Herkömmliche Engines hatten Probleme mit Metaphern und bildlicher Sprache und lieferten oft wörtliche Übersetzungen, die grammatikalisch korrekt, aber semantisch falsch waren – einige erhielten sogar "Ich möchte weinen"-Bewertungen von muttersprachlichen Prüfern.
- Microsoft ging mehr Risiken ein, indem es mutigere Übersetzungen anbot, die manchmal vom Original abwichen, sich aber natürlicher anfühlten – obwohl GPT es schwerer hatte, diese kreativen Entscheidungen zu bewerten.
- Die qualitative Analyse von GPT war stark, aber es hatte Schwierigkeiten, konsistente numerische Bewertungen zuzuweisen, insbesondere bei der Unterscheidung zwischen mittleren Bewertungen wie 3 vs. 4.
- In fast allen Sprachen verbesserte die zweite Iteration von GPT – als sie nach einer bildlicheren Version gefragt wurde – die Klarheit, den Ton und die kulturelle Anpassung.
- Koreanisch war die anspruchsvollste Sprache, sowohl für traditionelle MTs als auch für GPT-3, und zeigte auf breiter Front eine deutlich geringere Leistung.
- GPT-3 erwies sich nicht nur als wertvoller Übersetzer, sondern auch als Werkzeug für die Bewertung und Überarbeitung, indem es ungeschickte oder ungenaue Formulierungen kennzeichnete und Alternativen anbot.
GPT erreichte 90% Genauigkeit bei chinesischen Idiomen—MTs hatten Schwierigkeiten
Die folgende Analyse wurde von unserem Englisch/Chinesisch-Linguist James Hou verfasst.

Insgesamt hatten alle Engines mit der metaphorischen Natur der Sprache zu kämpfen und irrten sich oft in übertriebener Wörtlichkeit. Zum Beispiel, die Übersetzung „Lassen Sie uns den Tag beenden.“" ist eine wörtlichere und etwas unbeholfene Übersetzung von „Lass es uns für heute gut sein lassen“. Es vermittelt die Bedeutung des ursprünglichen Satzes, aber die Formulierung ist etwas umständlich und für chinesische Muttersprachler möglicherweise nicht so leicht zu verstehen.
Obwohl es die Bedeutung des ursprünglichen Satzes genau wiedergibt, ist die Formulierung etwas umständlich und für Muttersprachler möglicherweise weniger klar.
Ausgabe aus einer qualitativen Perspektive
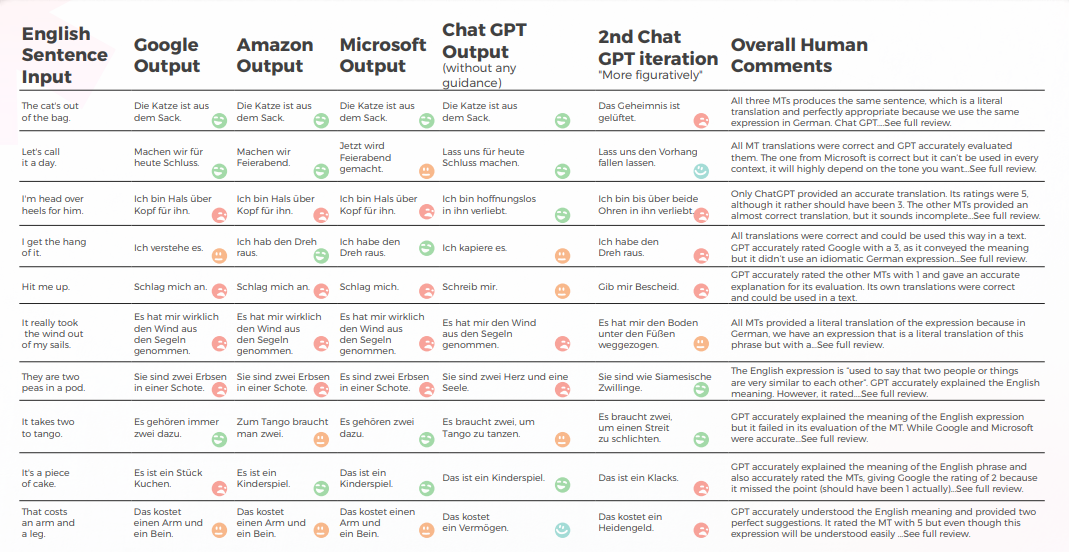
Die folgende Tabelle präsentiert eine synthetische Analyse von 10 englischen Idiomsätzen, die von unserem Team von Linguists ins Chinesische übersetzt wurden.
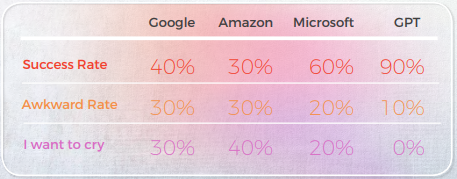
Was die Übersetzungsqualität betrifft, hat GPT einen großartigen Auftrag bei der Kontextualisierung geleistet. Beispielsweise: „秘密被揭露了。“„Die CAT ist aus dem Sack“ ist eine genaue und klare Übersetzung für „The cat’s out of the bag“. In 9 von 10 Sätzen war der Inhalt gut angepasst, verständlich und vermittelte die angemessene Bedeutung. Im Gegensatz zu den drei maschinellen Übersetzungs-Engines hatte GPT keine peinlichen „Ich möchte weinen“-Fehler.
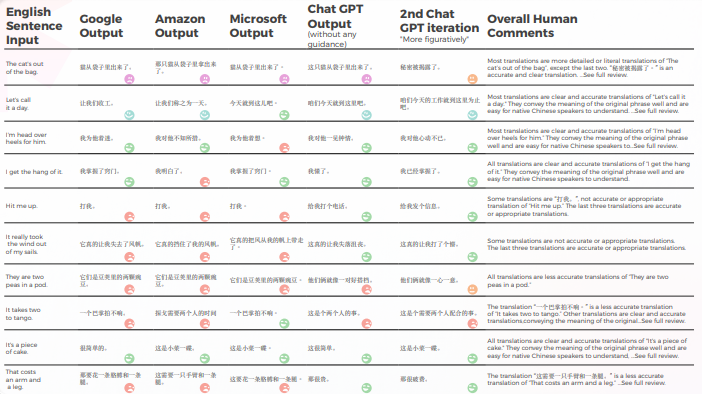
Die folgende Tabelle enthält die Rohdatenanalyse.
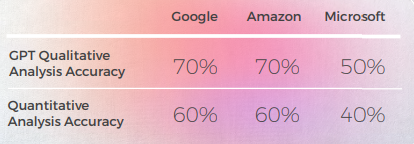
Bewertung von GPTs Bewertung
Analyse und Schlüssel Ergebnisse
- Google und Amazon hatten extrem ähnliche Ergebnisse, die nur geringfügig voneinander abwichen und einander in ihren Fehlern und metaphorischen Entscheidungen spiegelten. Zum Beispiel die Übersetzung „打我”。" ist keine genaue oder angemessene Übersetzung von "Hit me up". Der Ausdruck „Hit me up“ bedeutet, jemanden zu kontaktieren oder sich mit jemandem in Verbindung zu setzen, typischerweise per Telefon oder Textnachricht. Die chinesische Phrase „打我“ bedeutet „Schlag mich“ und vermittelt nicht die Bedeutung der ursprünglichen Phrase.
- Microsoft traf mutigere Entscheidungen, wenn es um die linguistische Anpassung der Redewendungen geht.
- GPT fiel es schwerer, die metaphorischen Entscheidungen von Microsoft zu bewerten, je mehr sie sich entfernten.
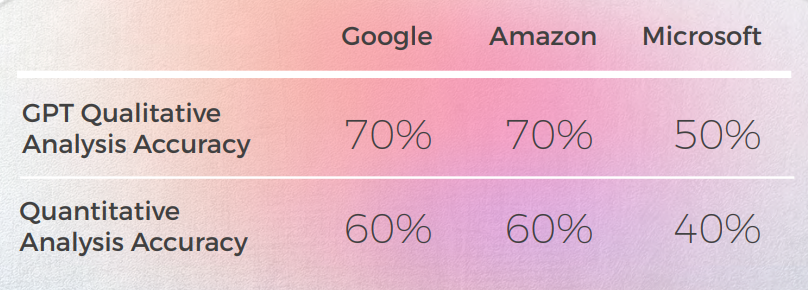
- GPT-3 hatte es leichter, mit der qualitativen Analyse eine überzeugende Textanalyse zu erstellen (wenn auch mit nur 70 % Genauigkeit).
- Obwohl verständlich, konnte die Analyse von GPT in 30 % der Fälle nicht identifizieren. Dies fiel mit metaphorischen Entscheidungen zusammen, die wörtlich und verständlich waren, aber vom alltäglichen Diskurs abwichen.
- GPT-3 hatte es schwerer, die qualitative Analyse in eine Punktzahl zu übersetzen. Obwohl die Ergebnisse im Großen und Ganzen zu 60 % genau waren, war es schwierig, zwischen ähnlichen Ergebnissen wie einer 3 und einer 4 zu unterscheiden.
- Die extreme Abweichung der Punktzahl von 1 bis 5 war leichter zu verstehen und stimmte besser mit den allgemeinen Kommentaren überein, die darauf hindeuten, dass:
- Möglicherweise wurden die Scoring-Kriterien mit GPT-3 nicht ausreichend kalibriert
- Vielleicht könnte das binäre Scoring relevanter sein als das Gradienten-Scoring
- • Auch wenn Microsoft quantitativ ähnlich wie Google und Amazon abschnitt, traf Microsoft bei genauerer Betrachtung der Sprache mutigere Entscheidungen und lieferte aus qualitativer Sicht bessere Ergebnisse, lag jedoch in Bezug auf Genauigkeit und kulturelle Anpassung immer noch weit hinter GPT-3 zurück. Zum Beispiel: Die Übersetzung „Ich habe den Dreh raus.“" ist eine klare und genaue Übersetzung von "Ich bekomme den Dreh raus". Es vermittelt die Bedeutung des ursprünglichen Satzes gut und ist für chinesische Muttersprachler leicht zu verstehen. Es ist auch eine bildlichere und idiomatischere Art, die Idee des Verstehens oder Beherrschens von etwas auszudrücken, verglichen mit anderen möglichen Übersetzungen.
Praktische Anwendungen und Einschränkungen
In dieser Analyse bot GPT-3 eine überlegene Kontextualisierung und Anpassung im Vergleich zu früheren Modellen der maschinellen Übersetzung.
Obwohl keiner der Engines zuverlässig genug ist, um Menschen zu ersetzen (zumindest im Kontext dieser Studie), zeigt GPT-3 eine klare Fähigkeit, menschliche Übersetzer und Gutachter beim Übersetzungs- und Bewertungsprozess zu unterstützen.
Französisch: MT-Engines versagten bei 60 % der Idiome – GPT fiel auf
Die folgende Analyse wurde von unserer Englisch/Französisch-Linguist Laurène Bérard verfasst.

Insgesamt hatten alle Engines mit der metaphorischen Natur der Sprache zu kämpfen und irrten sich oft in übertriebener Wörtlichkeit.
Aus einer qualitativen Perspektive
Die folgende Tabelle präsentiert eine synthetische Analyse von 10 englischen Idiomsätzen, die von unserem Team von Linguisten ins Französische übersetzt wurden.

Was die Übersetzungsqualität betrifft, hat GPT einen großartigen Auftrag bei der Kontextualisierung geleistet. Ohne jegliche Anleitung lag GPT völlig falsch bei „The cat’s out of the bag“, aber war mit mehr Anleitung richtig, und seine 3 Übersetzungen waren grammatisch unvollständig, daher ziemlich schwer zu verstehen für „It takes two to tango“.
Der Inhalt war allgemein gut angepasst, verständlich und vermittelte die angemessene Bedeutung. Die drei maschinellen Übersetzungs-Engines hatten eine hohe „Ich möchte weinen“-Rate, während selbst ohne Kontext ein Übersetzer erraten hätte, dass es nicht wörtlich gemeint war (z. B. „Lassen wir es gut sein“, was ziemlich offensichtlich ist, aber von der Google-Engine völlig missverstanden wurde.
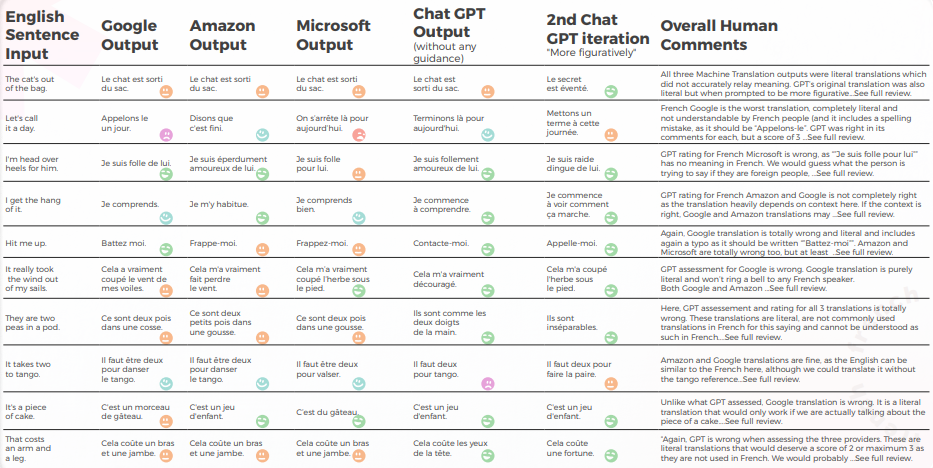
Die folgende Tabelle enthält die Rohdatenanalyse.
Bewertung von GPTs Bewertung
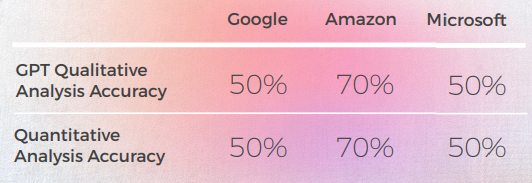
Analyse und Schlüssel-Ergebnisse
- Trotz korrekter Übersetzung in 8 von 10 Fällen war die GPT-Analyse der 3 Engines oft falsch, da in fast 50% der Fälle angegeben wurde, dass ihre Übersetzung in Ordnung sei, obwohl dies nicht der Fall war.
- Obwohl die Analyse von intelligible GPT in 30 bis 50 % der Fälle keine Probleme erkennen konnte, fiel dies mit Entscheidungen zusammen, die wörtlich waren und richtig gewesen wären, wenn es sich nicht um idiomatische Ausdrücke gehandelt hätte.
- GPT konnte die beiden Rechtschreibprobleme von Google ("Appelons le" und "Battez moi") nicht erkennen.
- Die qualitativen und quantitativen Analysen von GPT waren global konsistent miteinander.
- GPT hatte es schwerer, die Übersetzungen von Microsoft und Google zu bewerten.
- Microsoft hat bessere Entscheidungen bei der linguistischen Anpassung der Redewendungen getroffen.
- Google und Amazon hatten sehr ähnliche Ergebnisse, die nur geringfügig voneinander abwichen. Microsoft hob sich von den beiden ab.
- In einem Fall (dem Tango-Ausdruck) bewertete GPT eine gute Übersetzung von Microsoft als falsch (Punktzahl von 2), obwohl sie verständlich und genauso gut war wie die Übersetzungen von Google und Amazon, die GPT positiv bewertete (Punktzahl von 5). Dies könnte jedoch dadurch erklärt werden, dass Microsoft nicht so wörtlich war wie die anderen beiden Engines, da es sich dafür entschied, Walzer anstelle von Tango zu erwähnen.
- Microsoft traf mutigere Entscheidungen und lieferte aus qualitativer Sicht bessere Ergebnisse, lag aber in Bezug auf Genauigkeit und kulturelle Anpassung immer noch weit hinter GPT zurück.
Praktische Anwendungen und Einschränkungen
In dieser Analyse bot GPT eine weitaus bessere Kontextualisierung und Anpassung als die maschinellen Übersetzungsmaschinen von Amazon, Google und Microsoft. Obwohl es nicht praktisch ist, traditionelle maschinelle Übersetzungsmodelle durch größere Modelle wie GPT-3 zu ersetzen, aufgrund der hohen Rechenkosten und abnehmender Grenzerträge bei nicht-metaphorischen Diskursen, kann GPT-3 ein leistungsstarker menschlicher Verbündeter sein, wenn es darum geht, Vorschläge zu machen und potenzielle Fehler sowie Verbesserungsmöglichkeiten zu identifizieren.
Auch wenn maschinelle Übersetzungssysteme „fast“ soweit sind, wird dieses „fast“ zunehmend schwieriger zu bewältigen, wie GPT hier beweist.
Obwohl keine der Engines zuverlässig genug ist, um Menschen zu ersetzen (zumindest im Kontext dieser Studie), zeigt GPT eine klare Fähigkeit, menschliche Übersetzer und Prüfer beim Übersetzungs- und Bewertungsprozess zu unterstützen.
GPT übertraf alle MT-Engines bei deutschen Redewendungen um 30%
Die folgende Analyse wurde von unserer Englisch/Deutsch-Linguist Olga Schneider verfasst.

Insgesamt erzeugte GPT die genaueste Übersetzung. Es analysierte den englischen Satz immer genau und konnte normalerweise erkennen, ob es sich um eine maschinelle Übersetzung handelte, die wörtlich oder idiomatisch war, aber es gelang ihm nicht, in 50 % der Fälle eine Fehlübersetzung zu erkennen.
Ausgabe aus einer qualitativen Perspektive
Die folgende Tabelle präsentiert eine synthetische Analyse von 10 englischen Idiomsätzen, die von unserem Team von Linguisten ins Deutsche übersetzt wurden.

GPT liefert in 8 von 10 Fällen beim ersten Versuch und in 7 von 10 Fällen beim zweiten Versuch gute Ergebnisse. Zum Beispiel war nur GPT in der Lage, genaue idiomatische Übersetzungen für „Ich bin bis über beide Ohren in ihn verliebt“ und „Meld dich bei mir“ zu liefern.
Die letzte, bildlichste Ausgabe produzierte 4 gute Sätze, wobei die anderen entweder alle richtig oder „Ich möchte weinen“ waren. Insgesamt haben Amazon und Microsoft etwas bessere Übersetzungen abgeliefert als Google.
Die folgende Tabelle enthält die Rohdatenanalyse.
Bewertung der GPTs Bewertung
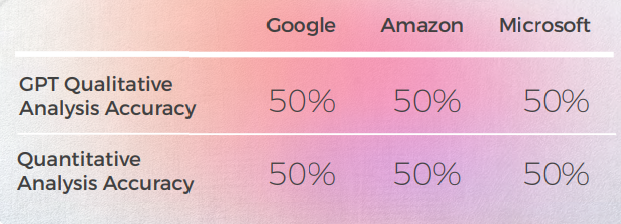
Analyse und Schlüssel Ergebnisse
- GPT hat ein ziemlich gutes Wissen über deutsche idiomatische Ausdrücke, selbst die, die nicht ganz dem englischen Satz entsprachen, waren idiomatische Ausdrücke einer ähnlichen Kategorie. Zum Beispiel: „Lassen wir den Stecker ziehen“ und „Lassen wir den Vorhang fallen“ für „Lassen wir es für heute gut sein“. Es versteht die allgemeine Bedeutung dieser Phrasen in Bezug auf "Ende" und könnte eine nützliche Inspirationsquelle sein.
- Wenn es um kreative Ausdrucksformen geht, scheint sich GPT von englischen Phrasen inspirieren zu lassen und schlägt die wörtliche deutsche Übersetzung von „Ich bin von Kopf bis Fuß in ihn verliebt“ als kreative Alternative zu „Ich bin bis über beide Ohren in ihn verliebt“ vor.
- Die Bewertungen der GPT-Übersetzungen waren ein Hit oder Miss und erwiesen sich als unzuverlässig. In einem Fall wurde eine Google-Übersetzung mit 2 bewertet, und es war nicht klar, warum es nicht die 1 war, die es hätte sein sollen.
- Deutsch und Englisch haben viele Redewendungen gemeinsam, was die Übersetzung erleichtert. Aber Ausdrücke, die dem Deutschen fremd sind (z. „Sie sind wie ein Herz und eine Seele“ oder „Es ist ein Kinderspiel“) werden schließlich wörtlich übersetzt. Im Fall der Erbsen verstand GPT im Gegensatz zu den Übersetzungsmaschinen, dass es Ausdrücke über "Zweien" bereitstellen musste. Die Ausdrücke, die es bereitstellte, waren zwar zutreffend und wurden häufig verwendet, vermittelten jedoch nicht die richtige Bedeutung.
Praktische Anwendungen und Einschränkungen
GPT lieferte bessere Übersetzungen als Google, Amazon und Microsoft. Auch wenn es nicht zu 100% zuverlässig ist, kann es einen besseren Ausgangspunkt für die Bearbeitung der maschinellen Übersetzung bieten als die anderen drei Engines. Während idiomatische Ausdrücke wichtig sind, gibt es ein weiteres Problem, das häufig bei der maschinellen Übersetzung von englischem zu deutschem Text auftritt: eine umständliche Satzstruktur, die dem Originaltext zu nahe kommt. Es wäre wichtig zu sehen, wie GPT dieses Problem löst.
Wenn es um die Bewertung geht, ist GPT kein gutes Werkzeug, da die Bewertung deutscher Übersetzungen nur zu 50 % genau ist.
Drei weitere Dinge wären interessant zu sehen gewesen:
- Kann GPT mit DeepL für Deutsch konkurrieren? Obwohl GPT möglicherweise gute Übersetzungen liefert, produziert DeepL gute deutsche Übersetzungen und bietet auch eine Reihe von Funktionen, die den Übersetzungsprozess vereinfachen (Glossarbegriffe werden korrekt mit dem richtigen Plural und Fall übersetzt, Ein-Klick-Bearbeitung, automatische Vervollständigung von Sätzen nach Eingabe eines oder zweier Wörter zur Beschleunigung der Umformulierung). Die Übersetzung von GPT muss deutlich besser sein als die von DeepL, um den Mangel an Funktionen auszugleichen.
- Könnte die Genauigkeit von GPT durch mehr Kontext verbessert werden, z. B. durch einen Absatz, der den Satz enthält?
- Wenn Google in der Lage ist, KI-generierten Text zu erkennen, wie wird es dann mit GPT-Übersetzungen umgehen, die nur minimal oder gar nicht bearbeitet werden? Kann es den „GPT-Stil“ erkennen und einen Text in seinen Suchergebnissen abstrafen?
Zusammenfassend lässt sich sagen, dass GPT in seinem derzeitigen Zustand eine Inspirationsquelle für unser begrenztes menschliches Gehirn sein kann. Es kann anständige Übersetzungen liefern. Mehr als das, es kann uns helfen, überstrapazierte Ausdrücke umzuformulieren, Metaphern zu finden und außerhalb der gewohnten Denkmuster zu denken.
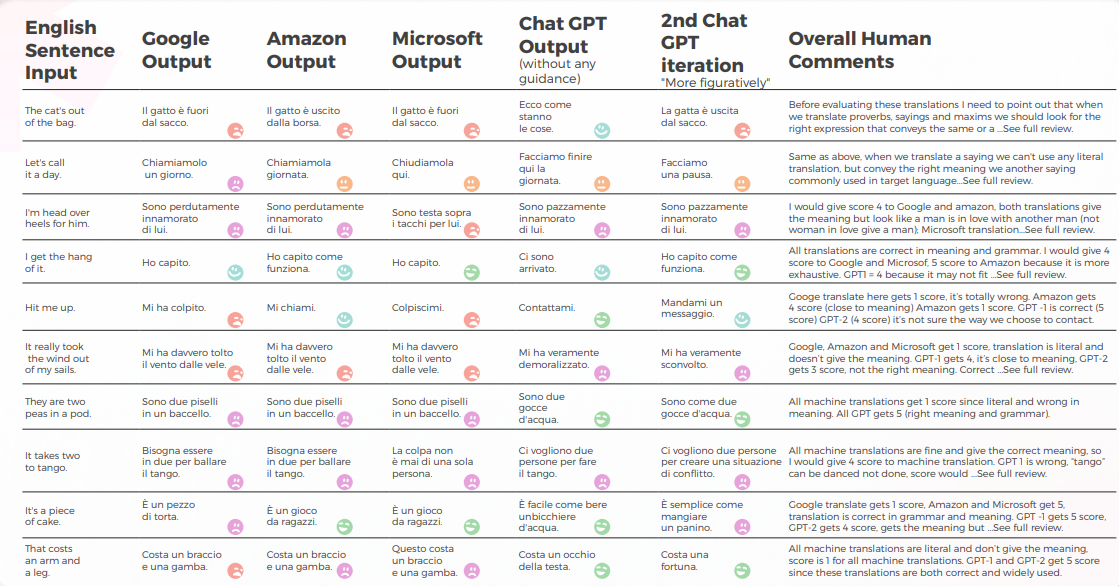
Italienisch: MT-Engines lieferten in 70 % der Fälle wörtliche Übersetzungen
Die folgende Analyse wurde von unserer Englisch/Italienisch-Linguist Elvira Bianco verfasst.

Insgesamt hatten alle Engines mit der metaphorischen Natur der Sprache zu kämpfen und irrten sich oft in übertriebener Wörtlichkeit.
Ausgabe aus einer qualitativen Perspektive
Die folgende Tabelle präsentiert eine synthetische Analyse von 10 englischen Idiomsätzen, die von unserem Team von Linguisten ins Italienische übersetzt wurden.
Maschinelle Übersetzung lieferte eine wörtliche Übersetzung, die sehr weit von der korrekten Bedeutung entfernt war. GPT vermittelte zu 70 % die korrekte Bedeutung und den richtigen Ausdruck, für die restlichen 30 % wurden akzeptable Ausdrücke verwendet, die nicht weit verbreitet sind oder als natürliche Muttersprache wahrgenommen werden.
Die folgende Tabelle enthält die Rohdatenanalyse.
Bewertung von GPTs Bewertung

Analyse und Schlüssel-Ergebnisse
- Google Translate erhält nur eine richtige Übersetzung und kommt in 2 Sätzen der Bedeutung nahe.
- Amazon gab 50% richtig Bedeutung, selbst wenn nicht die gebräuchlichste Art und Weise verwendet wird, um das englische Sprichwort in der italienischen Sprache zu vermitteln.
- Microsoft gab 3 richtige Antworten, die den italienischen ähnlichen Sprichwörtern näher kommen.
- Während 1st Chat GPT normalerweise maschinelle Übersetzungen genehmigt, geben 2nd und 3rd Chat GPT normalerweise die korrekte Bedeutung und fügen wertvolle Übersetzungsvorschläge hinzu.
Praktische Anwendungen und Einschränkungen
Wie von https://it.wiktionary.org/wiki/espressione_idiomatica definiert, kann ein idiomatischer Ausdruck, der für eine Sprache typisch ist, normalerweise nicht wörtlich in andere Sprachen übersetzt werden. Dies ist nur möglich, indem auf idiomatische Ausdrücke der Zielsprache zurückgegriffen wird, die ähnliche Bedeutungen wie die idiomatischen Ausdrücke der Ausgangssprache haben. Offensichtlich war die mechanische Übersetzung, die von den heute am häufigsten verwendeten Übersetzungsmaschinen (Google, Amazon, Microsoft) produziert wurde, unzuverlässig, dennoch erwies sich GPT-3 als fähig, in 70% der Fälle die richtige Bedeutung zu liefern und gute Vorschläge zur Anpassung des Inhalts zu machen.
Es ist nicht unwahrscheinlich, dass in naher Zukunft Maschinen auch idiomatische Ausdrücke speichern werden, aber richtig jetzt brauchen wir Menschen, um die gleiche Bedeutung von einer Sprache in eine andere zu übersetzen.
Sprachen sind voller Nuancen, Doppeldeutigkeiten, Anspielungen, Redewendungen, Metaphern, die nur ein Mensch wahrnehmen kann.
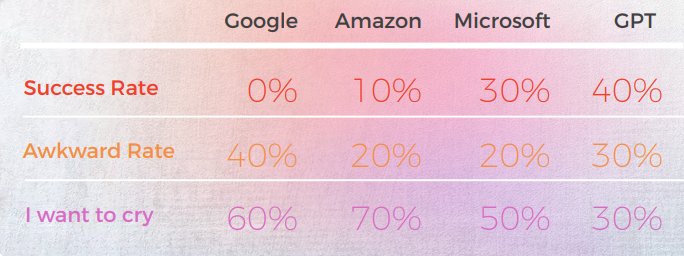
Koreanisch hatte die niedrigste Genauigkeit bei allen getesteten Engines
Die folgende Analyse wurde von unserem Englisch/Koreanisch-Linguist Sun Min Kim verfasst.

Ausgabe aus einer qualitativen Perspektive
Die folgende Tabelle präsentiert eine synthetische Analyse von 10 englischen Idiomsätzen, die von unserem Team von Linguisten ins Koreanische übersetzt wurden.
Die meisten Engines übersetzen die idiomatischen Ausdrücke wörtlich, während GPT versucht, so beschreibend wie möglich zu übersetzen, ohne eine Metapher zu verwenden (z. B. Stück Kuchen = einfach), während wir in Korea einen ähnlichen idiomatischen Ausdruck haben, der die gleiche Bedeutung vermittelt wie Microsoft.
Die drei Übersetzungen von GPT sind nicht konsistent. Einige werden mit der Iteration schlimmer.
Die folgende Tabelle enthält die Rohdatenanalyse.
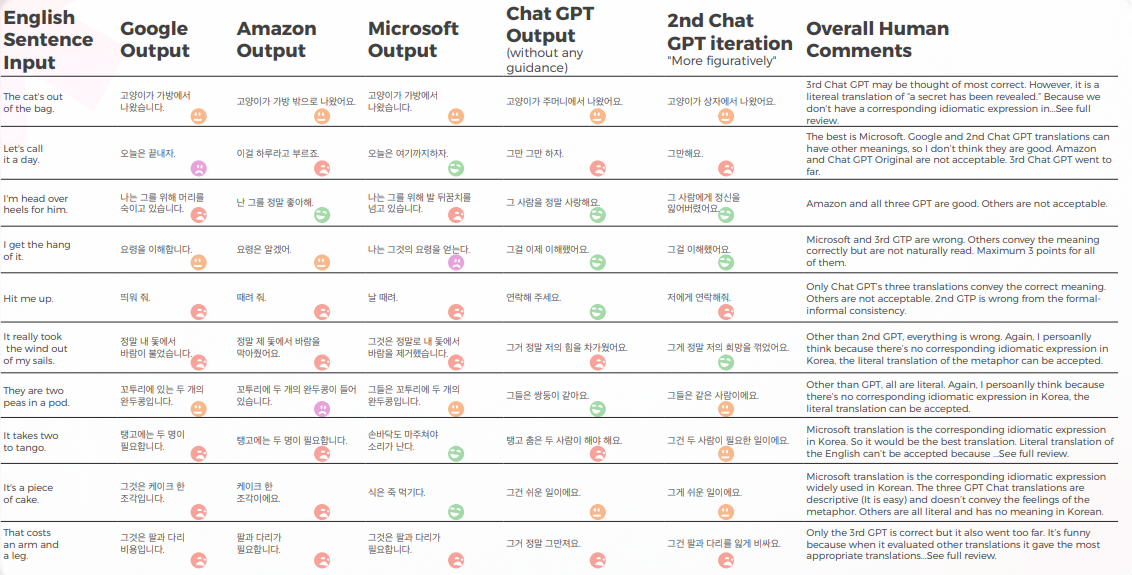
GPT kennt die Probleme, wenn die Übersetzungen schief gehen. Aber es wird nicht als richtig angesehen, den besten zu beurteilen.
GPT selbst hat Probleme mit der formellen – informellen Behandlung und so weiter, und es kann dieses Problem bewerten.
Bewertung von GPTs Bewertung

Analyse und Schlüssel Ergebnisse
Da die englischen Originale in dieser Studie idiomatische Ausdrücke sind, ist es ein wenig knifflig, weil man zwischen der Metapher oder der direkten Beschreibung wählen muss. Aber bei einigen idiomatischen Ausdrücken, bei denen die koreanische Sprache ähnliche idiomatische Ausdrücke mit derselben Bedeutung hat, haben die meisten Maschinen es versäumt, diese Ausdrücke zu finden, mit nur wenigen Ausnahmen (bitte sehen Sie sich das Arbeitsblatt an und finden Sie diejenigen mit der Bewertung 5 von mir).
Für andere ist mein persönlicher Gedanke, dass, wenn die Metapher selbst die Bedeutung vermitteln kann, eine wörtliche Übersetzung in Betracht gezogen werden kann und es vielleicht besser ist, ein beschreibendes Wort zu verwenden. Natürlich, wenn die Metapher in Korea keinen kulturellen Kontext hat, sollte sie nicht wörtlich übersetzt werden. Aber es ist ein subtiles Thema und vielleicht abhängig von der Vorliebe oder den menschlichen Emotionen des Übersetzers. Ich glaube nicht, dass irgendein Motor bisher dieses Maß an menschenähnlichem Denken hat.
Praktische Anwendungen und Einschränkungen
Ich denke, dass die meisten Engines für Vorübersetzungszwecke verwendet werden können. Aber in Anbetracht der Qualität sollte es in erster Linie nur für den Effizienzzweck sein (das heißt, nicht von Grund auf neu tippen). Bei beschreibenderen Texten, wie z.B. Handbüchern, sehe ich, dass MTPE viel fortschrittlicher ist als diese idiomatischen Ausdrücke. Es gibt also noch Raum für Verbesserungen.
GPT erreichte eine Erfolgsquote von 90 % bei brasilianischen portugiesischen Redewendungen
Die folgende Analyse wurde von unserem Englisch/Portugiesisch-Linguist Gabriel Fairman verfasst.

Insgesamt hatten alle Engines mit der metaphorischen Natur der Sprache zu kämpfen und irrten sich oft in übertriebener Wörtlichkeit.
Ausgabe aus einer qualitativen Perspektive
Die folgende Tabelle präsentiert eine synthetische Analyse von 10 englischen Idiomsätzen, die von unserem Team von Linguisten ins Portugiesische übersetzt wurden.
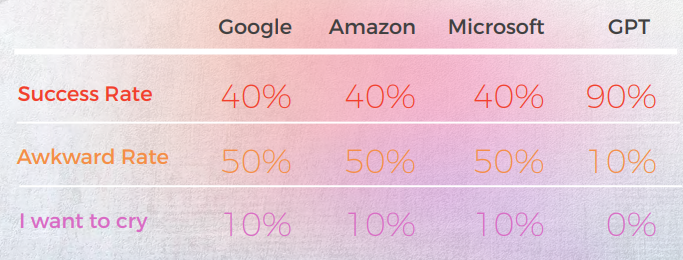
Die meisten Engines übersetzen die idiomatischen Ausdrücke wörtlich, während GPT versucht, so beschreibend wie möglich zu übersetzen, ohne eine Metapher zu verwenden (z. B. Stück Kuchen = einfach), während wir in Korea einen ähnlichen idiomatischen Ausdruck haben, der die gleiche Bedeutung vermittelt wie Microsoft.
Die drei Übersetzungen von GPT sind nicht konsistent. Einige werden mit der Iteration schlimmer.
Die folgende Tabelle enthält die Rohdatenanalyse.
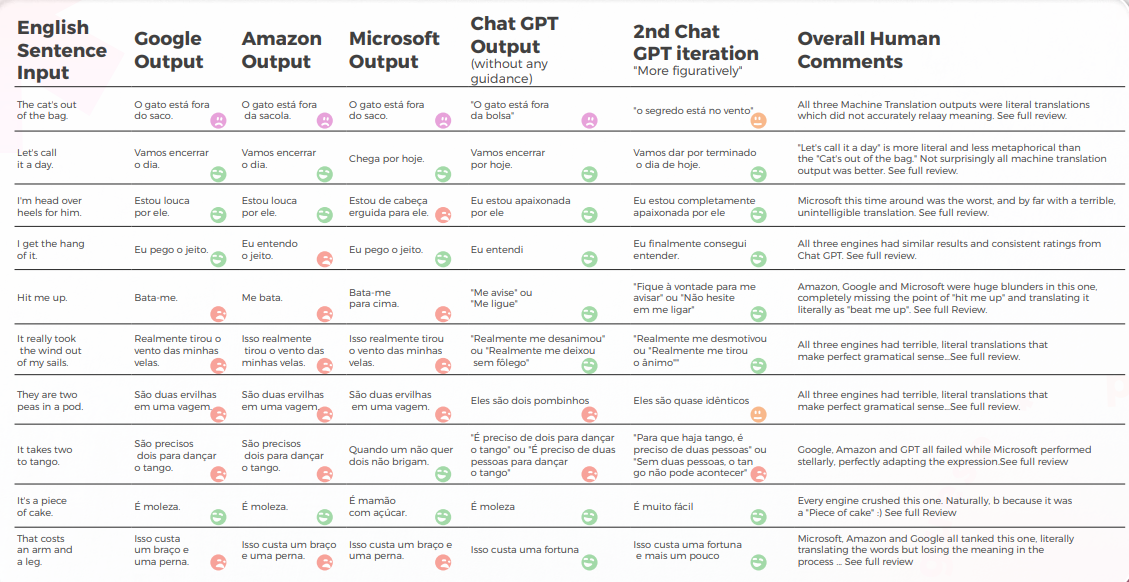
Was die Übersetzungsqualität betrifft, hat GPT einen großartigen Auftrag bei der Kontextualisierung geleistet. In 9 von 10 Sätzen war der Inhalt gut angepasst, verständlich und vermittelte die angemessene Bedeutung. Im Gegensatz zu den drei maschinellen Übersetzungs-Engines hatte GPT keine peinlichen „Ich möchte weinen“-Fehler.
Die anfängliche Hypothese war, dass es einen großen Unterschied in der Qualität zwischen der ersten und zweiten Iteration von GPT geben würde, aber die Übersetzungsqualität war in beiden ähnlich.
Bewertung von GPTs Bewertung
Analyse und Schlüssel-Ergebnisse
- Microsoft traf mutigere Entscheidungen, wenn es um die linguistische Anpassung der Redewendungen geht.
- GPT fiel es schwerer, die metaphorischen Entscheidungen von Microsoft zu bewerten, je mehr sie sich entfernten.
- Google und Amazon hatten extrem ähnliche Ergebnisse, die nur geringfügig voneinander abwichen und die Fehler und metaphorischen Entscheidungen des jeweils anderen widerspiegelten. Microsoft hob sich deutlich von den beiden ab.
- GPT-3 hatte es leichter, mit der qualitativen Analyse eine überzeugende Textanalyse zu erstellen (wenn auch mit nur 70 % Genauigkeit).
- Obwohl verständlich, konnte die Analyse von GPT in 30 % der Fälle nicht identifizieren. Dies fiel mit metaphorischen Entscheidungen zusammen, die wörtlich und verständlich waren, aber vom alltäglichen Diskurs abwichen.
- GPT-3 hatte es schwerer, die qualitative Analyse in eine Punktzahl zu übersetzen.
- Obwohl die Ergebnisse im Großen und Ganzen zu 60 % genau waren, war es schwierig, zwischen ähnlichen Ergebnissen wie einer 3 und einer 4 zu unterscheiden.
- Die extreme Abweichung der Punktzahl von 1 bis 5 war leichter zu verstehen und stimmte besser mit den allgemeinen Kommentaren überein, die darauf hindeuten, dass:
- Vielleicht waren die Bewertungskriterien mit GPT-3 nicht ausreichend kalibriert
- Vielleicht könnte eine binäre Bewertung relevanter sein als eine Gradientenbewertung. In einem anomalen Fall bewertete Chat GPT-3 zwei ähnliche Übersetzungen auf radikal unterschiedliche Weise, wobei die eine eine 1 und die andere eine 5 erhielt, obwohl beide eine 1 hätten sein sollen.
- Auch wenn Microsoft quantitativ ähnlich wie Google und Amazon abschnitt, traf Microsoft bei genauerer Betrachtung der Sprache mutigere Entscheidungen und lieferte aus qualitativer Sicht bessere Ergebnisse, lag jedoch in Bezug auf Genauigkeit und kulturelle Anpassung immer noch weit hinter GPT-3 zurück.
Praktische Anwendungen und Einschränkungen
In dieser Analyse bot GPT-3 eine überlegene Kontextualisierung und Anpassung im Vergleich zu früheren
maschinellen Übersetzungsmodellen im brasilianischen Portugiesisch. Obwohl es nicht praktisch ist, traditionelle maschinelle Übersetzungsmodelle durch größere Modelle wie GPT-3 zu ersetzen, aufgrund der hohen Rechenkosten und abnehmender Grenzerträge bei nicht-metaphorischen Diskursen, kann GPT-3 ein leistungsstarker menschlicher Verbündeter sein, wenn es darum geht, Vorschläge zu machen und potenzielle Fehler sowie Verbesserungsmöglichkeiten zu identifizieren.
Linguistische Sonderfälle sind erstaunlich, weil sie so deutlich zeigen, wie viel in so wenig übrig bleibt, wenn es um Sprachmodelle geht. Obwohl sie "fast" da sind, wird dieses "fast" immer schwieriger zu bewältigen und wenn nicht schwieriger, dann aus rechnerischer Sicht definitiv teurer.
Obwohl keiner der Engines zuverlässig genug ist, um Menschen zu ersetzen (zumindest im Kontext dieser Studie), zeigt GPT-3 eine klare Fähigkeit, menschliche Übersetzer und Gutachter im Prozess des Übersetzens und Bewertens von Sprache zu unterstützen.
Spanische MTs erzielten unter 30 %—GPT war der klare Gewinner
Die folgende Analyse wurde von unserem Englisch/Spanisch-Linguist Nicolas Davila verfasst.

Insgesamt hatten alle Engines mit der metaphorischen Natur der Sprache zu kämpfen und irrten sich oft in übertriebener Wörtlichkeit.
Ausgabe aus einer qualitativen Perspektive
Die folgende Tabelle präsentiert eine synthetische Analyse von 10 englischen Idiomsätzen, die von unserem Team von Linguisten ins Spanische übersetzt wurden.

Was die Übersetzungsqualität betrifft, hat GPT einen akzeptablen Auftrag gemacht und war besser als die anderen bei der Kontextualisierung. In 7 von 10 Sätzen war der Inhalt verständlich, gut formuliert und vermittelte die passende Bedeutung, mit geringer Unbeholfenheit und „Ich möchte weinen“-Raten.
Obwohl die anfängliche Hypothese war, dass es einen großen Unterschied in der Qualität zwischen der ersten und den nachfolgenden Iterationen von GPT geben würde, ist die Übersetzungsqualität in allen ähnlich. Die 2. und 3. Iteration fügen manchmal unnötige Dinge hinzu, was die Unbeholfenheitsrate etwas erhöht.
Die folgende Tabelle enthält die Rohdatenanalyse.
Bewertung von GPTs Bewertung

Analyse und Schlüssel-Ergebnisse
- MT-Übersetzungen waren zu wörtlich, wobei Amazon und Google in allgemeinen Begriffen sehr ähnlich waren und Microsoft die schlechteste war.
- Google und Amazon hatten extrem ähnliche Ergebnisse, die nur geringfügig voneinander abwichen und die Fehler und metaphorischen Entscheidungen des jeweils anderen widerspiegelten. Microsoft schnitt schlecht ab, produzierte manchmal schlecht geformte Sätze und es fehlten einige Teile der grammatikalischen Konstruktion.
- GPT-3 hatte es leichter, mit der qualitativen Analyse eine kohärente Textanalyse zu erstellen, auch wenn die Genauigkeit nur 50% betrug.
- Häufig war die qualitative Analyse von GPT-3 zu allgemein und beschränkte sich mehr auf die Haupt- und wörtliche Bedeutung des Satzes, ohne subtile Details der Konstruktion und Bedeutungsänderung zu berücksichtigen. Es scheint, dass GPT nicht in der Lage ist, solche Unterschiede zu erfassen und in quantitative Bewertungen zu übersetzen.
- Außerdem wies GPT Sätzen, die grammatikalisch schlecht konstruiert waren, häufig die gleiche qualitative Analyse und die gleiche hohe quantitative Punktzahl zu, was eine Einschränkung des GPT-Modells zu sein scheint.
- GPT-3 hatte es schwerer, die qualitative Analyse in eine Punktzahl zu übersetzen.
- Dabei ist es nur 50% genau für Google und Amazon und nur 30% genau für Microsoft. Es scheint, dass GPT nur gemessen hat, ob der Satz die Bedeutung vermittelt, aber keine Unterschiede in der Konstruktion oder guten Formulierung.
- Die Abweichung der Punktzahl von 1 bis 5 war leichter zu verstehen und stimmte besser mit den allgemeinen Kommentaren überein, die darauf hindeuten, dass: Vielleicht waren die Bewertungskriterien für GPT-3 nicht ausreichend kalibriert. Vielleicht könnte die binäre Bewertung relevanter sein als die Gradientenbewertung. Vielleicht berücksichtigten die Bewertungskriterien oder das GPT-Modell keine grammatikalischen Probleme, sondern vermittelten nur die Bedeutung.
Praktische Anwendungen und Einschränkungen
In dieser Analyse bot GPT-3 eine überlegene Kontextualisierung und Anpassung im Vergleich zu früheren Modellen der maschinellen Übersetzung im lateinamerikanischen Spanisch.
GPT-3 könnte ein leistungsstarkes Werkzeug sein, um Menschen dabei zu helfen, Übersetzungen zu verbessern, wenn es darum geht, nützliche Vorschläge und Verbesserungsmöglichkeiten bereitzustellen. Aber soweit ich sehen kann, hat es immer noch gewisse Einschränkungen.
Obwohl größere Modelle wie GPT-3 hilfreich sein könnten, ist es nicht praktisch, traditionelle maschinelle Übersetzungsmodelle durch sie zu ersetzen, da die höheren Rechenkosten bei nicht-metaphorischen Texten die marginalen Gewinne schmälern könnten.
Während GPT-3 eine klare Fähigkeit zeigt, menschliche Übersetzer und Gutachter beim Übersetzen und Bewerten von Sprache zu unterstützen, sollten Kostenüberlegungen berücksichtigt werden, wenn seine Verwendung für nicht-metaphorische Texte bewertet wird.
Schlussfolgerungen
Obwohl die Leistung von ChatGPT je nach Eingabeaufforderung und spezifischer Sprache variieren kann, legt unsere Studie nahe, dass ChatGPT das Potenzial hat, Übersetzungen von höherer Qualität als traditionelle MT-Engines zu erzeugen, insbesondere wenn es um den Umgang mit idiomatischen Ausdrücken und nuanciertem Sprachgebrauch geht.
Es ist jedoch wichtig zu beachten, dass ChatGPT weit davon entfernt ist, keine Fehler zu machen, und noch immensen Raum für Verbesserungen hat, insbesondere wenn es um komplexere Eingabeaufforderungen oder Sprachdomänen geht.
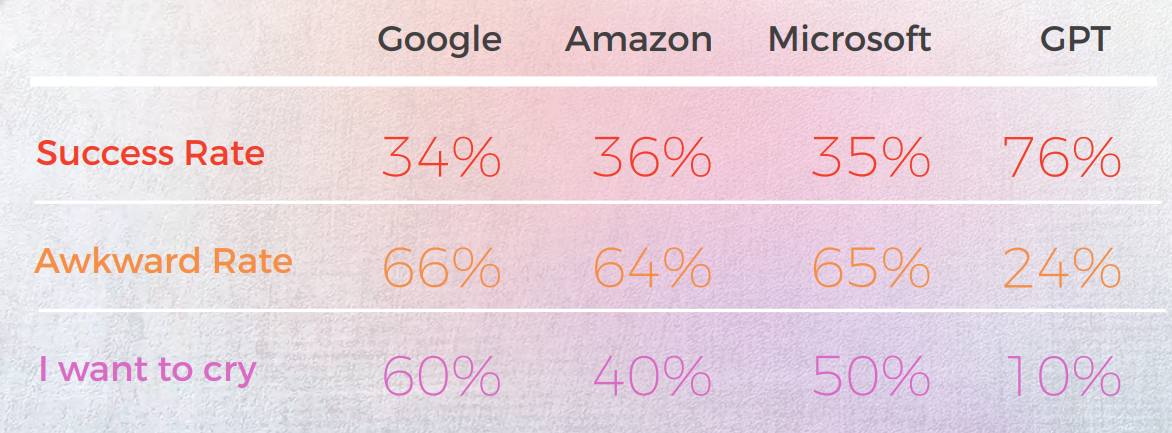
Als Übersetzer war ChatGPT erfolgreicher als alle getesteten maschinellen Übersetzungs-Engines. Während die Sprachen unterschiedliche Ergebnisse zeigten, war Koreanisch eindeutig der Ausreißer, da die MT-Qualität und die GPT-Qualität deutlich niedriger waren als bei anderen Sprachen.
In allen Sprachen außer Koreanisch hatte ChatGPT eine Erfolgsquote von mindestens 70 % und höchstens 90 % und schnitt damit besser ab als herkömmliches MT. Und selbst im Koreanischen waren die Ergebnisse zwar niedrig, aber immer noch besser als die Ausgabe der MT-Engine.
Im Gegensatz zur maschinellen Übersetzung kann mit einem LLM die Qualität des gleichen Inhalts durch Iterationen verbessert werden. Dies ist der Schlüssel, wenn man über Integrationen nachdenkt, denn während bei traditionellem MT Ihr Output immer gleich Ihrem Input sein wird (es sei denn, die Engine erhält weitere Daten oder Training), kann man mit einem LLM mehrere Interaktionen über die API erkunden, um die Feed-Qualität zu optimieren.
Ein Vorteil von ChatGPT gegenüber herkömmlichen MT-Engines ist seine Fähigkeit, im Laufe der Zeit zu lernen und sich zu verbessern, auch ohne zusätzliche Trainingsdaten. Dies liegt in der Natur von LLMs, die darauf ausgelegt sind, ihre Sprachmodelle auf der Grundlage neuer Eingaben kontinuierlich zu verfeinern. Daher kann ChatGPT potenziell anpassungsfähigere und dynamischere Übersetzungsfähigkeiten bieten, was besonders nützlich in Szenarien sein könnte, in denen die Sprache oder der Inhalt sich ständig weiterentwickelt oder verändert.
Ein weiterer Vorteil von ChatGPT ist die niedrige Cringe-Rate, die eine deutliche Verbesserung gegenüber herkömmlichen MÜ-Engines darstellt, die oft ungeschickte oder unangemessene Übersetzungen produzieren. Dies könnte ChatGPT für nicht-expertisierte Benutzer, die möglicherweise nicht über das gleiche Maß an sprachlichem oder kulturellem Wissen wie professionelle Übersetzer verfügen, akzeptabler und benutzerfreundlicher machen.
Es ist jedoch wichtig zu beachten, dass ChatGPT kein Ersatz für menschliche Übersetzer ist und es eine Vielzahl von Fällen gibt, in denen die Expertise und das Urteilsvermögen eines menschlichen Übersetzers benötigt werden. Aber die deutlich niedrigeren Cringe-Raten von ChatGPT öffnen die Tür für eine breitere Akzeptanz von nicht-menschengesteuerten Übersetzungen.
Als Evaluator war die Leistung von ChatGPT gemischter, mit Genauigkeitsraten zwischen 30 % und 70 %. Während dies darauf hindeutet, dass ChatGPT möglicherweise nicht so effektiv bei der Bewertung anderer Übersetzungsmaschinen ist, wie es bei der Vorschlagserstellung von Übersetzungen ist, könnte dies auf die Komplexität und Qualität der Bewertungsaufforderungen zurückzuführen sein, die möglicherweise mehr spezialisiertes oder kontextuelles Wissen erfordern, als ChatGPT derzeit besitzt. Weitere Forschung ist erforderlich, um das Potenzial von ChatGPT als Evaluator sowie seine Grenzen und Herausforderungen zu untersuchen.Insgesamt deutet unsere Studie darauf hin, dass ChatGPT über vielversprechende Übersetzungsfähigkeiten verfügt, die es wert sind, weiter untersucht zu werden. Obwohl es möglicherweise nicht in der Lage ist, menschliche Übersetzer vollständig zu ersetzen oder zu umgehen, könnte es potenziell erhebliche Vorteile als Hilfsmittel oder Vorübersetzungswerkzeug bieten, insbesondere in Szenarien, in denen Zeit, Ressourcen oder Fachwissen begrenzt sind.
Wie bei jeder aufstrebenden Technologie gibt es noch viele Herausforderungen und Möglichkeiten zur Verbesserung, und weitere Forschung und Experimente werden erforderlich sein, um das volle Potenzial auszuschöpfen.
Methodik
Um zu untersuchen, wie Sprachmodelle wie GPT-3 mit idiomatischer Übersetzung im Vergleich zu traditionellen maschinellen Übersetzungsmaschinen umgehen, führten wir ein Experiment durch, das sich auf linguistische Grenzfälle mit Metaphern und idiomatischen Ausdrücken konzentrierte.
Auswahl von idiomatischen Ausdrücken
Wir haben 10 häufig verwendete englische Redewendungen ausgewählt, wie „Lassen Sie uns Schluss machen“, „Melde dich bei mir“ und „Die CAT ist aus dem Sack.“ Diese Ausdrücke sind bekannt dafür, Übersetzungs-Systeme herauszufordern, da sie kulturelle und kontextuelle Anpassung erfordern, anstatt wörtliche Entsprechung.
Getestete Übersetzungsmaschinen und -modelle
Jedes Idiom wurde übersetzt mit:
- Google Translate
- Amazon Translate
- Microsoft Übersetzer
- GPT-3 (ChatGPT) – using two approaches:
- Eine direkte Übersetzung ohne jegliche Anleitung
- Eine zweite Version, die dazu angeregt wurde, bildhafter und idiomatischer zu sein

Bewertungsprozess
Die übersetzten Ergebnisse wurden von muttersprachlichen Linguists in sieben Zielsprache überprüft: Brasilianisches Portugiesisch, Spanisch, Französisch, Deutsch, Italienisch, Chinesisch und Koreanisch. Für jeden Satz bewerteten die Gutachter:
- Ob die Bedeutung der ursprünglichen Redewendung beibehalten wurde
- Die Natürlichkeit des Ausdrucks in der Zielsprache
- Grammatik, Syntax und semantische Genauigkeit
Jede Übersetzung wurde auf einer Skala von 1 bis 5 bewertet:
- 5: Korrekte Bedeutung und natürlich klingende Sprache
- 1: Falsche, verwirrende oder unnatürliche Übersetzung ("I want to cry"-Level)
Zusätzlich haben wir ChatGPT gebeten, die Übersetzungen der anderen Engines zu bewerten, sowohl durch qualitatives Textfeedback als auch durch numerische Bewertungen. Dies ermöglichte es uns, seine Fähigkeiten als Evaluator und nicht nur als Übersetzungsgenerator zu bewerten.
Einschränkungen der Studie
Es ist wichtig zu beachten, dass es sich um eine explorative Studie handelte:
- Die Stichprobe war auf 10 Redewendungen mit einem menschlichen Prüfer pro Sprache beschränkt.
- Alle Bewertungen tragen ein gewisses Maß an Subjektivität und individueller Präferenz in sich.
- Die Leistung von GPT-3 spiegelt eine spezifische Version des Modells wider und kann sich mit Aktualisierungen weiterentwickeln.
Trotz dieser Einschränkungen bieten die Ergebnisse wertvolle Einblicke in die Fähigkeiten und Grenzen aktueller Modelle, insbesondere in sprachlich nuancierten und kulturell abhängigen Szenarien.
Haftungsausschlüsse
(Echte Forschungsausschlüsse, die nicht auf die leichte Schulter genommen werden sollten)
Während wir versuchten, das Potenzial der Sprachfähigkeiten von ChatGPT zu erkunden, ist es wichtig zu beachten, dass diese Studie nur einen Aspekt der Übersetzung bewertet hat, nämlich die Fähigkeit, mit linguistischen idiomatischen hochmetaphorischen Grenzfällen umzugehen. Andere Aspekte der Übersetzung, wie kulturelles und kontextuelles Verständnis, können andere Bewertungsmethoden und -kriterien erfordern.
Die Stichprobengröße dieser Studie ist auf 10 Redewendungen und einen Gutachter pro Sprache beschränkt, was möglicherweise nicht repräsentativ für die gesamte Bandbreite der idiomatischen Ausdrücke in der englischen Sprache oder die Vielfalt der Perspektiven und Fachkenntnisse professioneller Übersetzer ist. Daher sollten die Ergebnisse dieser Studie mit Vorsicht interpretiert werden und können nicht auf andere Kontexte oder Domänen verallgemeinert werden.
Darüber hinaus sind die Meinungen und Bewertungen des einzelnen Rezensenten pro Sprache subjektiv und können durch persönliche Vorurteile, Erfahrungen oder Vorlieben beeinflusst werden. Wie bei jeder subjektiven Bewertung gibt es ein gewisses Maß an Variabilität und Unsicherheit in den Ergebnissen. Um die Zuverlässigkeit und Gültigkeit unserer findings zu erhöhen, könnten zukünftige Studien mehrere Gutachter, Blindbewertungen oder Maßnahmen zur Interrater-Reliabilität einbeziehen.
Es ist auch erwähnenswert, dass die Sprachfähigkeiten von ChatGPT nicht statisch sind und sich im Laufe der Zeit ändern können, wenn das Modell weiter trainiert und fein abgestimmt wird. Daher sollten die Ergebnisse dieser Studie als Momentaufnahme der Leistung des Modells zu einem bestimmten Zeitpunkt betrachtet werden und möglicherweise nicht seine aktuellen oder zukünftigen Fähigkeiten widerspiegeln.
Schließlich soll diese Studie keine endgültigen oder kategorischen Aussagen über den Nutzen oder die Grenzen von ChatGPT für die Übersetzung treffen. Vielmehr soll es als vorläufige Untersuchung und Ausgangspunkt für zukünftige Forschung und Entwicklung im Bereich der Verarbeitung natürlicher Sprache und maschinellen Übersetzung dienen. Wie bei jeder aufstrebenden Technologie gibt es noch viele Herausforderungen und Möglichkeiten zur Verbesserung, und weitere Experimente und Zusammenarbeit werden erforderlich sein, um ihr Potenzial vollständig zu erkunden.
Nutzen Sie das Potenzial der Glokalisierung mit unserem Translation-Management-System.
Nutzen Sie das Potenzial der
mit unserem Translation-Management-System.








