Chat GPTの翻訳をテストしました - データは次のとおりです


AIが翻訳をどのように変革しているかについて誰もが話していますが、AIは本当に人間の言語のニュアンスを処理できるのでしょうか?
Bureau Worksによる最近の研究では、これをテストし、Google、Amazon、Microsoftの主要な機械翻訳エンジンとGPT-3を比較しました。 この研究では、ローカリゼーションにおける最も困難な課題の1つである慣用表現に焦点を当てました。 なぜですか。 文字通りの翻訳では、「The CAT’s out of the bag」や「Let’s call it a day」のようなフレーズには対応できません。
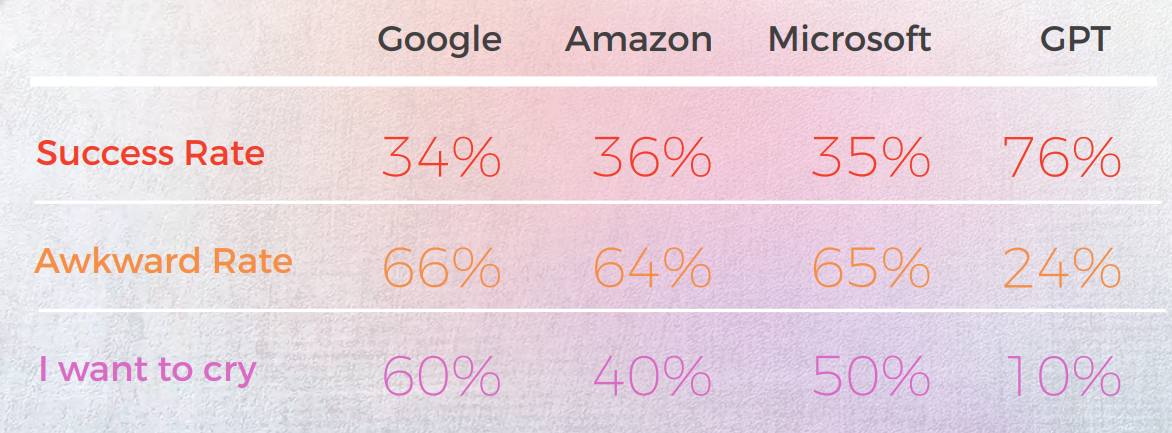
その結果は驚くべきものでした。 GPT-3は、90%の確率で正確で自然な響きの翻訳を提供しましたが、従来のエンジンは20%から50%の間で推移し、しばしばネイティブの翻訳者によって「泣きたい」と評価されるような恥ずかしい出力を生み出しました。
言語の微妙な違いがメッセージの成否を左右する世界で、これらの見つけるは、プロの翻訳におけるAIの可能性と現在の限界の両方を浮き彫りにしています。
こちらが私たちの重要な見つけた内容の要約です:
- GPT-3は、従来のMTエンジン(Google、Amazon、Microsoft)よりも慣用表現の処理において一貫して優れており、ポルトガル語や中国語などの言語では最大90%の精度に達しました。
- 従来のエンジンは、比喩や比喩的な言葉に苦戦し、文法的には正しいが意味的にはずれた直訳を提供することがよくあり、中にはネイティブのレビュアーから「泣きたい」と評価されるものさえありました。
- マイクロソフトはより多くのリスクを冒し、オリジナルから逸脱することもあったが、より自然に感じられる大胆な翻訳を提供したが、GPTはこれらの創造的な選択を評価するのに苦労した。
- GPTの定性分析は強力でしたが、特に3対4のような中程度の評価を区別する場合に一貫した数値スコアを割り当てるのに苦労しました。 4.
- ほぼすべての言語で、「GPT」の 2 回目のイテレーションでは、より比喩的なバージョンを求められたとき、明瞭さ、トーン、文化的な適合性が向上し。
- 韓国語は、従来のMTとGPT-3の両方にとって最も難しい言語であり、全体的にパフォーマンスが大幅に低下しています。
- GPT-3は、翻訳者としてだけでなく、評価と修正のツールとしても価値があることが証明されました。不自然または不正確な表現を指摘し、代替案を提供するのに役立ちます。
GPTは中国の成語で90%の精度を達成—MTは苦戦
以下の分析は、私たちの英語/中国語の翻訳者ジェームズ・ホウによって書かれました。

全体として、すべてのエンジンは言語の隠喩的な性質に苦労し、しばしば過度の字義性で誤りを犯しました。 例えば、翻訳「今日はこれで終わりにしましょう」。」は、「Let's call it a day」のより直訳的で、ややぎこちない翻訳です。 元のフレーズの意味を伝えていますが、言い回しがやや不自然で、中国語のネイティブスピーカーには理解しにくいかもしれません。
元のフレーズの意味を正確に伝えていますが、言葉遣いはややぎこちなく、ネイティブスピーカーには明確でない場合があります。
定性的な視点からの出力
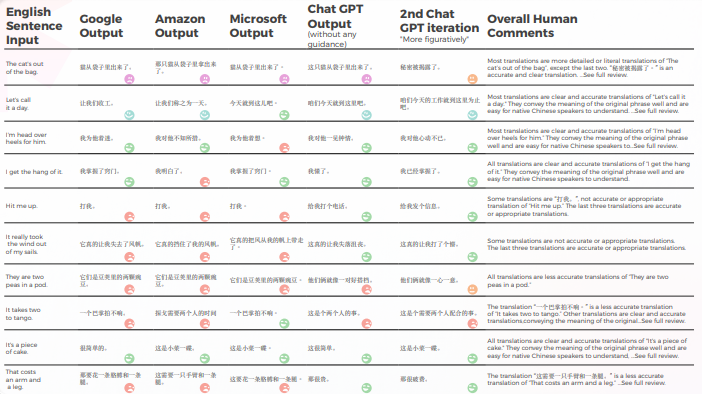
以下の表は、翻訳者のチームによって行われた、10の英語のイディオム文を中国語に翻訳した合成分析を示しています。
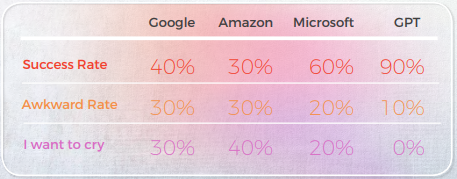
翻訳の品質に関しては、GPTは文脈化で素晴らしい案件をしました。 たとえば、「秘密が明らかになった」などです。「The CAT's out of the bag」の正確で明確な翻訳は「」です。 10文のうち9文で、コンテンツはよく適応され、理解可能で、適切な意味が伝えられていました。 3つの機械翻訳エンジンとは対照的に、GPTには「泣きたい」といった恥ずかしい間違いはありませんでした。
次の表には、生データ分析が含まれています。
GPTs評価の評価
分析と重要な見つけ
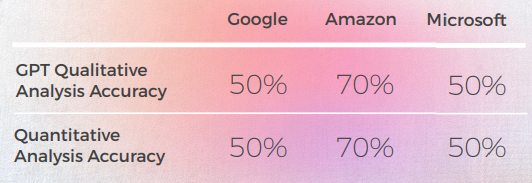
- GoogleとAmazonは非常に似た結果を出し、わずかに異なるだけで、お互いの間違いや比喩的な選択を反映していました。 たとえば、「打我」と訳されます。「」は「Hit me up」の正確または適切な翻訳ではありません。 「Hit me up」というフレーズは、通常電話やテキストメッセージで誰かに問い合わせ先する、または連絡を取ることを意味します。 中国語の「打我」は「私を打て」という意味で、元のフレーズの意味を伝えていません。
- Microsoftは、イディオムの言語的適応に関してより大胆な選択をしました。
- GPTは、Microsoftの比喩的な選択を評価するのに苦労しました。それらがより多く逸脱したためです。
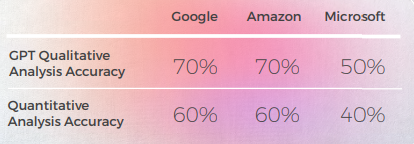
- GPT-3は、定性分析において説得力のあるテキスト分析を行うのが容易でした(精度はわずか70%ですが)。
- GPTの分析では、理解できるものの、30%のケースで特定できませんでした。 これは、文字通りで理解できるが、日常的な言説から逸脱した比喩的な選択と一致しました。
- GPT-3は、定性分析をスコアに変換するのに苦労しました。 大まかに言えば、スコアの精度は60%でしたが、3と4などの類似したスコアを区別することは困難でした。
- 1から5への極端なスコアの乖離は理解しやすく、全体的なコメントとより互換性があり、次のことを示唆しています。
- GPT-3では採点基準が十分に調整されていなかったのかもしれません
- もしかしたら、二項採点が勾配採点よりも関連性が高いかもしれません
- • 量的にはマイクロソフトはグーグルやアマゾンと同様のパフォーマンスを示しましたが、言語の細部に踏み込むと、マイクロソフトはより大胆な選択を行い、質的な観点からはより良い結果を提供しました。しかし、精度と文化的適応に関しては、依然としてGPT-3に大きく遅れをとっていました。 たとえば、翻訳「我掌握了窍门。」「私はコツをつかむ」は、「I get the hang of it」の明確で正確な翻訳です。 原文の意味がよく伝わり、中国語ネイティブの方にも理解しやすい内容となっています。 それは、他の可能な翻訳と比較して、何かを理解したり習得したりするアイデアを表現する、より比喩的で慣用的な方法でもあります。
実用的な応用と制限
この分析では、GPT-3は以前の機械翻訳モデルよりも優れた文脈化と適応を提供しました。
どのエンジンも人間を置き換えるほど信頼できるものではありません(少なくともこの研究の文脈では)、GPT-3は人間の翻訳者やレビュアーが言語を翻訳し評価する過程を支援する明確な能力を示しています。
フランス語: MTエンジンはイディオムの60%で失敗—GPTが際立った
以下の分析は、私たちの英語/フランス語の翻訳者Laurène Bérardによって書かれました。

全体として、すべてのエンジンは言語の隠喩的な性質に苦労し、しばしば過度の字義性で誤りを犯しました。
定性的な視点からの出力
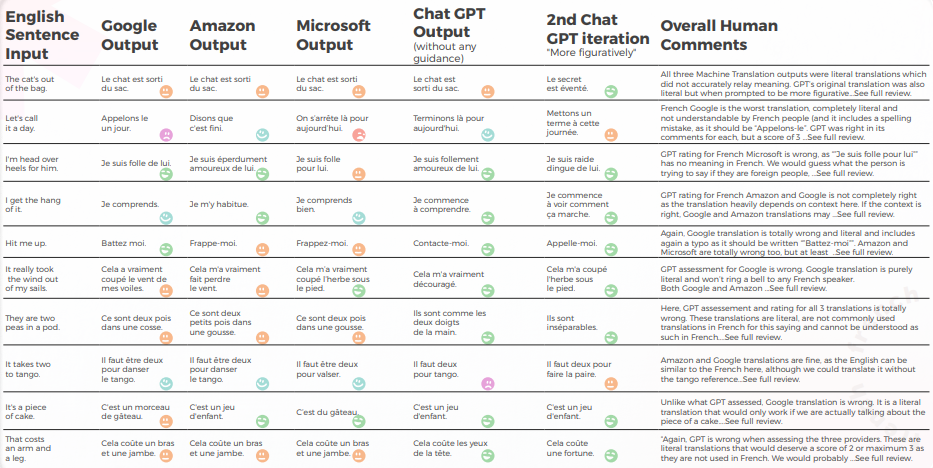
以下の表は、翻訳者のチームによって行われた、10の英語のイディオム文をフランス語に翻訳した合成分析を示しています。

翻訳の品質に関しては、GPTは文脈の把握において素晴らしい案件をしました。 ガイダンスがないと、GPTは「The cat’s out of the bag」に対して完全に間違っていましたが、より多くのガイダンスがあると正しいでした。また、「It takes two to tango」に対する3つの翻訳は文法的に不完全で、理解するのが非常に難しかったです。
コンテンツは一般的によく適応されており、理解可能で、適切な意味を伝えていました。 3つの機械翻訳エンジンは、「泣きたい」という率が高かったが、文脈がなくても翻訳者はそれが文字通りの意味ではないと推測しただろう(例: 「今日はこの辺で終わりにしよう」というのは当たり前のことですが、Googleエンジンには完全に誤解されていました)。
次の表には、生データ分析が含まれています。
GPTs評価の評価
分析と重要な見つけ
- 10回中8回正しく翻訳されているにもかかわらず、3つのエンジンに対するGPTの分析はしばしば間違っていました。ほぼ50%のケースで、翻訳が問題ないとされていましたが、実際にはそうではありませんでした。
- わかりやすいGPTの分析では、30〜50%のケースで問題を特定できませんでしたが、これは文字通りの選択と一致しており、慣用表現を扱わなければ正しかったでしょう。
- GPTは、Googleの2つのスペルの問題(「Appelons le」と「Battez moi」)を見つけることができませんでした。
- GPTの定性的分析と定量的分析は、グローバルに一貫していました。
- GPTは、MicrosoftとGoogleの翻訳を評価するのに苦労しました。
- Microsoftは、イディオムの翻訳に関してより良い選択をしました。
- GoogleとAmazonは非常に似たような結果をもたらしましたが、互いにわずかにずれているだけでした。 マイクロソフトは、その2つの中で際立っていました。
- あるケース(タンゴの表現)では、GPTはMicrosoftの優れた翻訳を誤りと評価しました(スコア2)が、それは理解可能で、GPTが高評価したGoogleやAmazonの翻訳と同等に良いものでした(スコア5)。しかし、Microsoftが他の2つのエンジンほど直訳的でなかったため、タンゴの代わりにワルツに言及することを選んだという事実によって説明できるかもしれません。
- マイクロソフトは、定性的な観点からより大胆な選択を行い、より良い結果を提供しましたが、精度と文化的適応に関しては依然としてGPTに大きく遅れをとっていました。
実用的な応用と制限
この分析では、GPTはAmazon、Google、Microsoftの機械翻訳エンジンよりもはるかに優れた文脈化と適応を提供しました。 従来の機械翻訳モデルをGPT-3のような大規模モデルに置き換えることは、高い計算コストや非比喩的な談話における限界利益の減少のため、便利ではありませんが、GPT-3は提案を提供し、潜在的なミスや改善の機会を特定する際に、パワフルな人間の味方となることができます。
機械翻訳エンジンは「ほぼ」そこにありますが、この「ほぼ」は、ここでGPTが証明しているように、次第に対処が難しくなります。
どのエンジンも人間を置き換えるほど信頼性が高いわけではありません(少なくともこの研究の文脈では)、GPTは人間の翻訳者やレビュアーが翻訳や言語の評価を行う過程で支援する明確な能力を示しています。
GPTはドイツ語のイディオムで全てのMTエンジンを30%上回った
以下の分析は、私たちの英語/ドイツ語の翻訳者オルガ・シュナイダーによって書かれました。

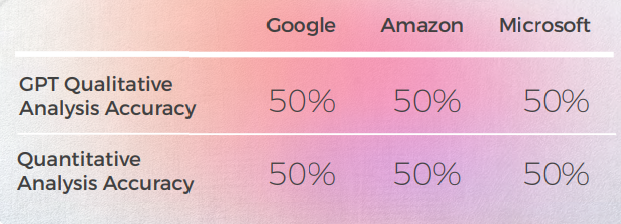
全体として、GPTは最も正確な翻訳を生成しました。 常に英語の文を正確に分析し、機械翻訳が直訳か慣用的かを通常判断できましたが、誤訳を50%の確率で検出できませんでした。
質的視点からの出力
以下の表は、翻訳者のチームによって行われた、10の英語のイディオム文をドイツ語に翻訳した合成分析を示しています。

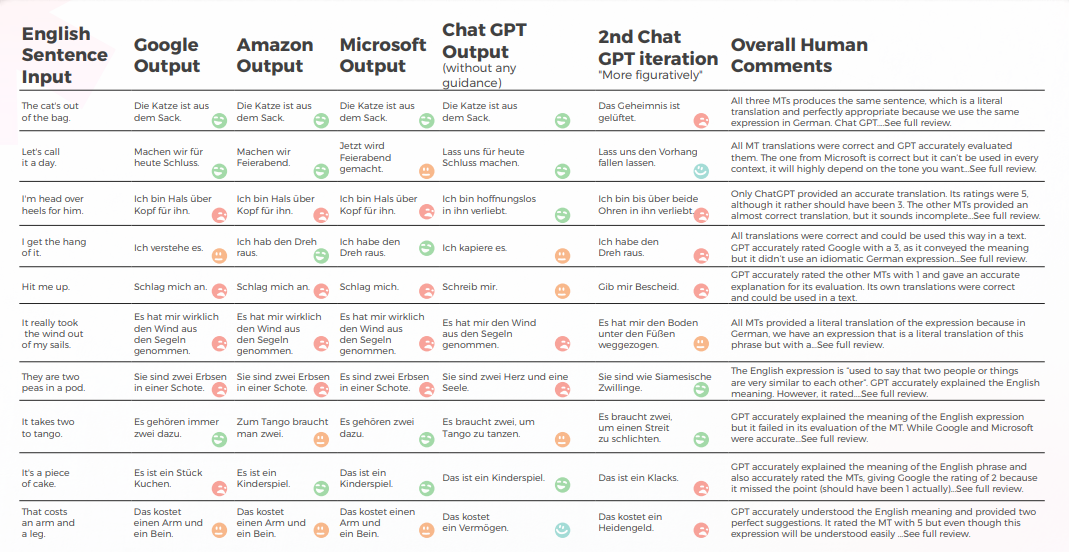
GPTは、最初の試行で10回中8回、2回目の試行で10回中7回良い結果を生み出します。 例えば、「I'm head over heels for him」や「Hit me up」の正確な慣用的な翻訳を提供できたのはGPTだけでした。
最後の、最も比喩的な出力は4つの良い文を生成し、他はすべて正しいか「泣きたい」ものでした。 全体として、AmazonとMicrosoftはGoogleよりもわずかに優れた翻訳を行いました。
次の表には、生データ分析が含まれています。
GPTs評価の評価
分析と重要な見つけたこと
- GPTはドイツ語の慣用表現についてかなり良い知識を持っており、英語の文と完全に一致しなかったものでも、同様のカテゴリの慣用表現でした。 例えば: 「プラグを抜こう」「幕を降ろそう」は「今日はここまでにしよう」という意味です。 「エンディング」に関連するこれらのフレーズの一般的な意味を理解しており、インスピレーションの有用な源となる可能性があります。
- クリエイティブな表現に関して、GPTは英語のフレーズからインスピレーションを得ており、「I’m head over heels for him」に対する創造的な代替案として、「I am in love with him from head to toe」のドイツ語の直訳を提案しています。
- GPTの翻訳評価は当たり外れがあり、信頼性が低いことが証明されました。 あるケースでは、Google翻訳を2と評価し、なぜそれが本来の1でなかったのかが明確ではありませんでした。
- ドイツ語と英語は多くの慣用表現を共有しているため、翻訳が容易になります。 しかし、ドイツ語とは異質な表現(例: 「彼らはさやの中の2つのエンドウ豆です」または「それは簡単です」)は、文字通りに翻訳されます。 エンドウ豆の場合、翻訳エンジンとは異なり、GPTは「2つ」についての表現を提供する必要があることを理解していました。 しかし、それが提供した表現は、正確で一般的に使用されているにもかかわらず、正しい意味を伝えていませんでした。
実用的なアプリケーションと制限
GPTは、Google、Amazon、Microsoftよりも優れた翻訳を提供しました。 完全に信頼できるわけではありませんが、他の3つのエンジンよりも機械翻訳編集のためのより良い出発点を提供することができます。 慣用表現は重要ですが、英語からドイツ語への機械翻訳でよく遭遇するもう一つの問題があります。それは、原文にあまりにも近い煩雑な文構造です。 GPTがこの問題をどのように解決するかを見ることが重要です。
評価に関しては、GPTはドイツ語翻訳の評価精度が50%しかないため、優れたツールではありません。
さらに3つの点が面白かったでしょう。
- GPTはドイツ語でDeepLと競争できますか? GPTは良い翻訳を提供するかもしれませんが、DeepLは優れたドイツ語翻訳を提供し、翻訳プロセスを簡素化するさまざまな機能も提供しています(用語集の用語が正しい複数形と格で翻訳され、ワンクリックで編集でき、1、2語入力するだけで文章を自動補完して言い換えを迅速化します)。 GPTの翻訳は、機能の不足を補うためにDeepLの翻訳よりも大幅に優れている必要があります。
- GPTの精度は、フレーズを含む段落など、より多くのコンテキストで向上させることができますか?
- もしGoogleがAIが生成したテキストを認識できるとしたら、最小限の編集でGPT翻訳をどのように処理するのでしょうか? 「GPTスタイル」を検出し、検索結果のテキストにペナルティを課すことはできますか?
要約すると、現在の状態では、GPTは私たちの限られた人間の脳のインスピレーションの源となることができます。 それはまともな翻訳を提供することができます。 それ以上に、それは私たちが使い古された表現を言い換え、メタファーを見つけることを助け、型にはまらない考え方をするのに役立ちます。
イタリア語: MTエンジンは70%のケースで直訳を返しました
以下の分析は、私たちの英語/イタリア語の翻訳者Elvira Biancoによって書かれました。

全体として、すべてのエンジンは言語の隠喩的な性質に苦労し、しばしば過度の字義性で誤りを犯しました。
質的視点からの出力
以下の表は、翻訳者のチームによって行われた、10の英語のイディオム文をイタリア語に翻訳した合成分析を示しています。
機械翻訳は、正しい意味から非常にかけ離れた直訳を提供しました。 GPTは70%の確率で正しい意味と表現を伝え、残りの30%では、自然なネイティブスピーチのように広く使用されていない、または認識されていない許容される表現を使用しました。
次の表には、生データ分析が含まれています。
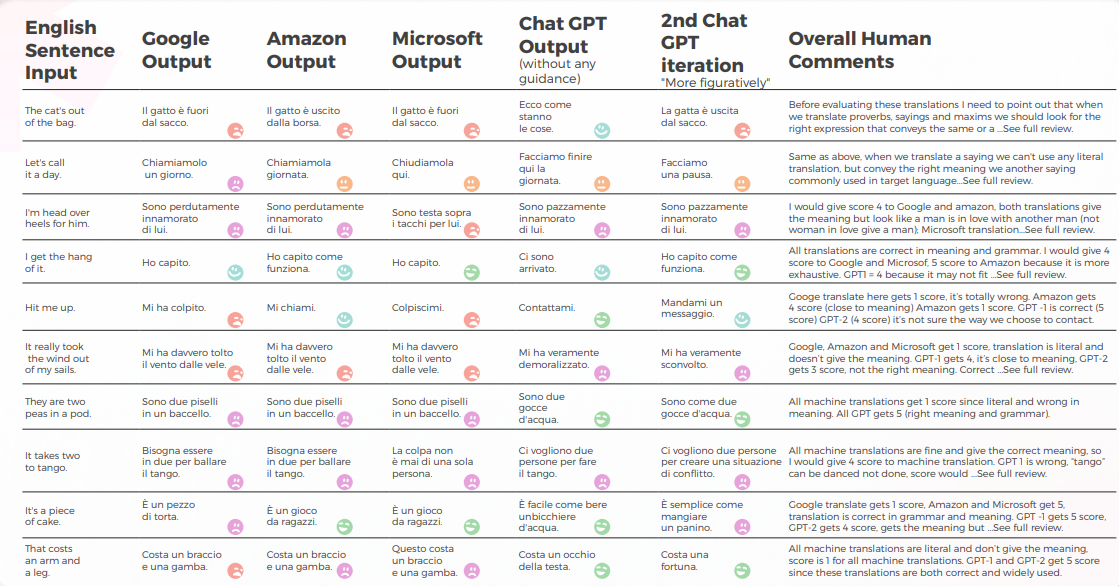
GPTsの評価

分析と重要な見つけ
- Google Translateは1つの正しい翻訳を得て、2つの文で意味に近づきます。
- Amazonは、イタリア語で英語の言い回しを伝える最も一般的な方法を使用していなくても、50%の正しい意味を与えました。
- Microsoftは3つの正しい答えを出し、イタリアの類似したことわざに近づきました。
- 通常、1st Chat GPTは機械翻訳を承認するが、2ndと3rd Chat GPTは通常、正しい意味を与え、貴重な翻訳の提案を追加する。
実用的なアプリケーションと制限
https://it.wiktionary.org/wiki/espressione_idiomatica によれば、ある言語の典型的な慣用表現は、翻訳元の言語の慣用表現に似た意味を持つ翻訳先の言語の慣用表現に頼る以外、通常は文字通り他の言語に翻訳することはできません。 今日最も使用されている翻訳機(Google、Amazon、Microsoft)によって生成された機械翻訳は明らかに信頼性が低く、GPT-3は70%の確率で正しい意味を提供し、コンテンツの適応において良い提案をすることができることが証明されました。
近い将来、機械が慣用表現を記憶することもあり得ないことではありませんが、正しい今は、人間がある言語から別の言語に同じ意味を伝える翻訳を行う必要があります。
言語は、ニュアンス、二重の意味、ほのめかし、イディオム、人間だけが知覚できる比喩でいっぱいです。
すべてのエンジンで韓国語の精度が最も低かった
以下の分析は、私たちの英語/韓国語の翻訳者であるSun Min Kimによって書かれました。

質的視点からの出力
以下の表は、翻訳者のチームによって行われた、10の英語のイディオム文を韓国語に翻訳した合成分析を示しています。
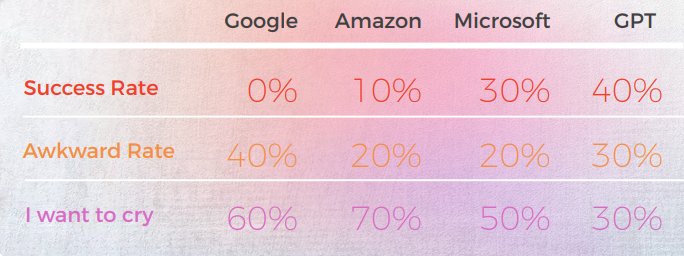
ほとんどのエンジンは慣用表現を文字通り翻訳しますが、GPTは比喩を使わずにできるだけ説明的に翻訳しようとします(例: piece of cake = 簡単、韓国では、Microsoftと同じ意味を伝える同様の慣用表現があります)。
GPTの3つの翻訳は一貫していません。 イテレーションによって悪化しているものもあります。
次の表には、生データ分析が含まれています。
GPTは、翻訳がうまくいかない場合の問題を認識しています。 しかし、それが最良のものを判断するのに正しいとは考えられていません。
GPT自体が公式・非公式の扱いなどに問題を抱えており、この問題を評価することができます。
GPTs評価の評価

分析と重要な見つけたこと
この研究の英語の原文は慣用表現であるため、比喩と直接的な説明のどちらを選ぶかで少し難しいです。 しかし、韓国語に同様の意味を持つ慣用表現がある場合を除いて、ほとんどのエンジンはそれらの表現を見つけることができませんでした。いくつかの例外を除いて(ワークシートを参照し、私が5のスコアを付けたものを見つけてください)。
他のケースについては、比喩自体が意味を伝えることができるなら、直訳を考慮することができ、説明的な言葉を使う方が良いかもしれないというのが私の個人的な考えです。 もちろん、その比喩が韓国に文化的な文脈を持たない場合、文字通りに翻訳すべきではありません。 しかし、それは微妙な問題であり、翻訳者の好みや人間の感情に委ねられるかもしれません。 まだそのレベルの人間のような思考力を持つエンジンはないと思います。
実用的なアプリケーションと制限
ほとんどのエンジンは、事前翻訳の目的で使用できると思います。 ただし、品質を考慮すると、それは主に効率性の目的のためだけであるべきです(つまり、最初から入力するのではありません)。 マニュアルのようなより説明的なテキストについては、MTPEはこれらの慣用表現よりもはるかに進んでいると見ています。 したがって、まだ改善の余地があります。
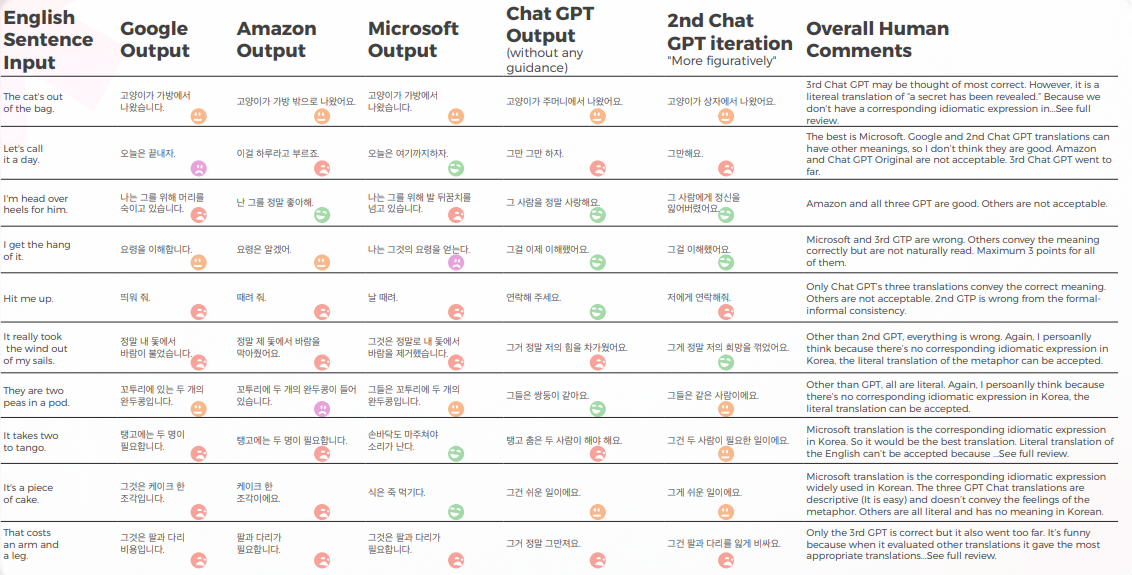
GPTはブラジルポルトガル語のイディオムで90%の成功率を達成
以下の分析は、私たちの英語/ポルトガル語の翻訳者Gabriel Fairmanによって書かれました。

全体として、すべてのエンジンは言語の隠喩的な性質に苦労し、しばしば過度の字義性で誤りを犯しました。
定性的な視点からの出力
以下の表は、翻訳者のチームによってポルトガル語に翻訳された10の英語のイディオム文の合成分析を示しています。ほとんどのエンジンは慣用表現を文字通り翻訳しますが、GPTは比喩を使わずにできるだけ説明的に翻訳しようとします(例: piece of cake = 簡単、韓国では、Microsoftと同じ意味を伝える同様の慣用表現があります)。
GPTの3つの翻訳は一貫していません。 イテレーションによって悪化しているものもあります。
次の表には、生データ分析が含まれています。
翻訳の品質に関しては、GPTは文脈の把握において素晴らしい案件をしました。 10文のうち9文で、コンテンツはよく適応され、理解可能で、適切な意味が伝えられていました。 3つの機械翻訳エンジンとは対照的に、GPTには「泣きたい」といった恥ずかしい間違いはありませんでした。
最初の仮説は、GPTの最初と2回目のイテレーションの間で品質に大きな違いがあるだろうというものでしたが、翻訳の品質はどちらも似ていました。
GPTs評価の評価
分析と重要な見つけたこと
- Microsoftは、慣用句の言語的適応に関してより大胆な選択をしました。
- GPTは、Microsoftの比喩的な選択を評価するのに苦労しました。それらがより多く逸脱したためです。
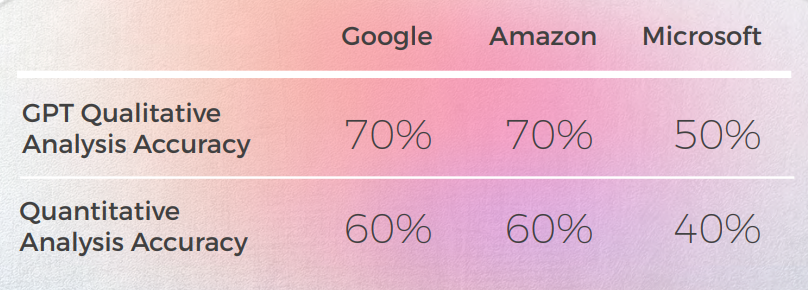
- グーグルとアマゾンは非常に似た結果を出し、わずかに異なるだけで、互いの間違いや比喩的な選択を反映していました。 Microsoftは明らかに2つの中で際立っていました。
- GPT-3は、定性分析において説得力のあるテキスト分析を行うのが容易でした(精度はわずか70%ですが)。
- GPTの分析では、理解できるものの、30%のケースで特定できませんでした。 これは、文字通りで理解できるが、日常的な言説から逸脱した比喩的な選択と一致しました。
- GPT-3は、定性分析をスコアに変換するのに苦労しました。
- 大まかに言えば、スコアの精度は60%でしたが、3と4などの類似したスコアを区別することは困難でした。
- 1から5への極端なスコアの乖離は理解しやすく、全体的なコメントとより互換性があり、次のことを示唆しています。
- GPT-3では採点基準が十分に調整されていなかったのかもしれません
- もしかしたら、二項採点が勾配採点よりも関連性が高いかもしれません。ある異常なケースでは、Cchat GPT-3は2つの類似した翻訳を根本的に異なる方法で評価し、どちらも1であるべきなのに1ともう1つに5を与えました。
- マイクロソフトは、量的にはグーグルやアマゾンと同様のパフォーマンスを示しましたが、言語の詳細に踏み込むと、マイクロソフトはより大胆な選択を行い、質的な観点からはより良い結果を提供しました。しかし、精度と文化的適応に関しては、依然としてGPT-3に大きく遅れをとっています。
実用的な応用と制限
この分析では、GPT-3は以前の
機械翻訳モデルよりもブラジルポルトガル語で優れた文脈化と適応を提供しました。 従来の機械翻訳モデルをGPT-3のような大規模モデルに置き換えることは、高い計算コストや非比喩的な談話における限界利益の減少のため、便利ではありませんが、GPT-3は提案を提供し、潜在的なミスや改善の機会を特定する際に、パワフルな人間の味方となることができます。
言語のエッジケースは驚くべきものであり、言語モデルに関して、どれだけ少ない中にどれだけ多くが残されているかを非常に明確に示しています。 彼らが「ほぼ」そこにいるにもかかわらず、この「ほぼ」に取り組むのは次第に難しくなり、難しくないにしても、計算の観点からは間違いなく高価になります。
どのエンジンも人間を置き換えるほど信頼できるものではありませんが(少なくともこの研究の文脈では)、GPT-3は人間の翻訳者やレビュアーが翻訳や言語の評価を行う過程で支援する明確な能力を示しています。
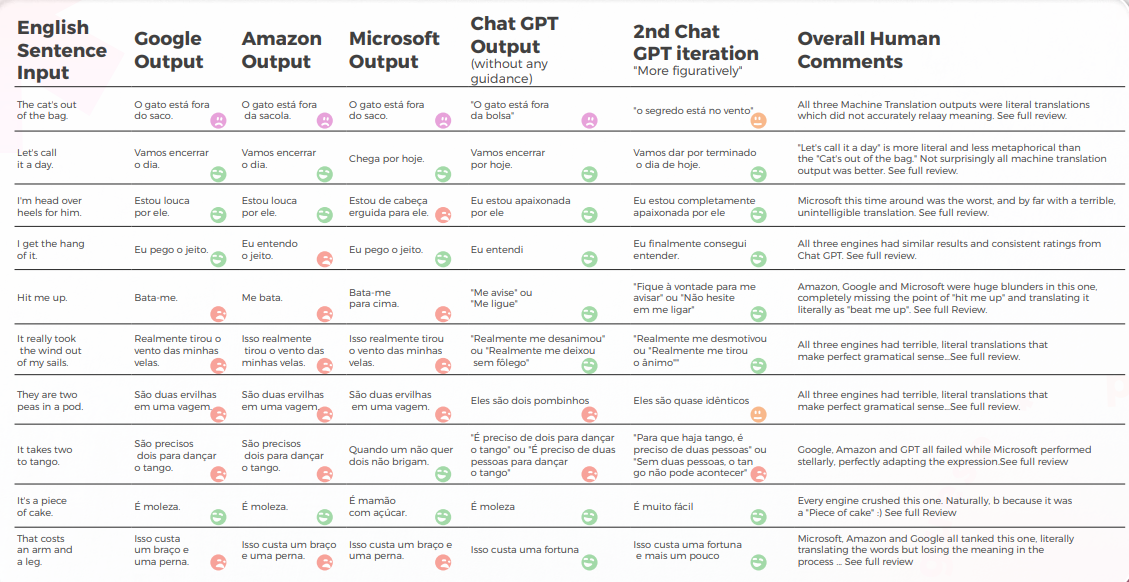
スペイン語MTのスコアは30%未満—GPTが明らかに勝者
以下の分析は、私たちの英語/スペイン語の翻訳者Nicolas Davilaによって書かれました。

全体として、すべてのエンジンは言語の隠喩的な性質に苦労し、しばしば過度の字義性で誤りを犯しました。
定性的な視点からの出力
以下の表は、翻訳者のチームによって行われた、10の英語のイディオム文をスペイン語に翻訳した合成分析を示しています。

翻訳の品質に関して言えば、GPTは許容できる案件を行い、文脈化において他よりも優れていました。 10文のうち7文では、コンテンツは理解可能で、よく構成されており、適切な意味を伝えていて、不自然さや「泣きたい」率が低かった。
最初の仮説では、GPTの最初の反復とその後の反復の間で品質に大きな違いがあるとされていましたが、翻訳の品質はすべての反復で似ています。2回目と3回目の反復では時々不要なものを追加することがあり、少し不自然さが増します。
次の表には、生データ分析が含まれています。
GPTsの評価

分析と重要な見つけ
- MT翻訳はあまりにも直訳的で、AmazonとGoogleは一般的に非常に似ており、Microsoftは最悪でした。
- グーグルとアマゾンは非常に似た結果を出し、わずかに異なるだけで、互いの間違いや比喩的な選択を反映していました。 マイクロソフトはパフォーマンスが悪く、時々形式が悪い文が生成され、文法構造の一部が欠落していました。
- GPT-3は、定性分析において、精度が50%しかないにもかかわらず、首尾一貫したテキスト分析を行うことがより簡単でした。
- GPT-3の定性分析は、しばしばあまりにも一般的で、文の主な意味や文字通りの意味に限定され、構成や意味の変化の微妙な詳細を考慮していませんでした。 GPTはそのような違いを捉えて、定量的なスコアに変換することができないようです。
- また、GPTは、文法的に構成が不十分な文に対して、同じ定性的分析と高い定量的スコアを頻繁に割り当てていましたが、これがGPTのモデルの限界であると思われます。
- GPT-3は、定性分析をスコアに変換するのに苦労しました。
- GoogleとAmazonではわずか50%、Microsoftではわずか30%の精度です。 GPTは、文が意味を伝えているかどうかのみを測定していたようで、構造や良い形成に違いはなかったようです。
- 1から5へのスコアの乖離は理解しやすく、全体的なコメントとより互換性があり、次のことを示唆しています。 GPT-3に対して採点基準が十分に調整されていなかったのかもしれません。もしかしたら、二項採点が勾配採点よりも関連性が高いかもしれません。 もしかしたら、採点基準やGPTモデルは文法的な問題を考慮せず、意味を伝えることだけを重視していたのかもしれません。
実用的な応用と制限
この分析では、GPT-3はラテンアメリカのスペイン語における以前の機械翻訳モデルよりも優れた文脈化と適応を提供しました。
GPT-3は、役立つ提案や改善の機会を提供することに関して、人間が翻訳を改善するのを助けるパワフルなツールとなり得ます。 しかし、私が見る限り、まだ一定の制限があります。
GPT-3のような大規模モデルは役立つかもしれませんが、従来の機械翻訳モデルをそれらに置き換えるのは、計算コストが高いため便利ではありません。非比喩的なテキストに関しては、限界利益が減少する可能性があります。
GPT-3は、人間の翻訳者やレビュアーが言語を翻訳および評価する過程で支援する明確な能力を示していますが、非比喩的なテキストに使用する際にはコストの考慮が含まれるべきです。
結論
ChatGPTの性能はプロンプトや特定の言語によって異なることがありますが、我々の研究は、特に慣用表現や微妙な言語の使い方を扱う際に、ChatGPTが従来のMTエンジンよりも高い品質の翻訳を生成する可能性があることを示唆しています。
ただし、ChatGPTは間違いを犯さないわけではなく、特により複雑なプロンプトや言語ドメインに関しては、まだ改善の余地が非常に大きいことに注意することが重要です。
翻訳者として、ChatGPTはテストされたすべての機械翻訳エンジンよりも成功しました。 言語によって異なる結果が示されましたが、韓国語は明らかに例外であり、MT品質とGPT品質が他の言語よりも著しく低かったです。
韓国語を除くすべての言語において、ChatGPTの成功率は少なくとも70%、最大で90%で、従来のMTよりも優れたパフォーマンスを発揮しました。 そして、韓国語でもスコアは低かったものの、MTエンジンの出力よりは良かったです。
機械翻訳とは異なり、LLMを使用すると、同じコンテンツの反復が出力の品質を向上させることができます。 統合を考える際には、これは重要なことです。従来のMTでは、エンジンがさらにデータやトレーニングを受けない限り、出力は常に入力と同じになりますが、LLMを使用すると、APIを介していくつかのインタラクションを探索し、フィード品質を最適化することができます。
従来の MT エンジンに対する ChatGPT の利点の 1 つは、追加のトレーニング データがなくても、時間の経過とともに学習し、改善する能力です。 これは、新しい入力に基づいて言語モデルを継続的に改良するように設計されたLLMの性質によるものです。 このように、ChatGPTは、言語やコンテンツが絶えず進化または変化しているシナリオで特に役立つ、より適応的で動的な翻訳機能を提供する可能性があります。
ChatGPTのもう一つの利点は、クリンジレートが低いことで、これは、しばしばぎこちないまたは不適切な翻訳を生成する従来のMTエンジンに比べて大幅に改善されています。 これは、専門的な翻訳者と同じレベルの言語的または文化的知識を持たない非専門的なユーザーにとって、ChatGPTをより受け入れやすく、ユーザーフレンドリーにする可能性があります。しかし、ChatGPTは人間の翻訳者の代わりにはならず、人間の翻訳者の専門知識と判断が必要な無数のケースがあることに注意することが重要です。 しかし、ChatGPTのクリンジ率が大幅に低いことは、人間が主導しない翻訳のより広範な採用への扉を開きます。
評価者として、ChatGPTのパフォーマンスはよりまちまちで、精度は30%から70%の範囲でした。 これは、ChatGPTが翻訳を提案するのと同じくらい他の翻訳エンジンを評価するのに効果的ではないことを示唆していますが、これは評価プロンプトの複雑さと品質による可能性があります。これには、ChatGPTが現在持っている以上の専門的または文脈的な知識が必要かもしれません。 ChatGPTの評価者としての可能性、その限界と課題を探るには、さらなる研究が必要です。
全体として、私たちの研究は、ChatGPTがさらに探求する価値のある有望な翻訳機能を持っていることを示唆しています。 人間の翻訳者を全体的に置き換えたり、迂回したりすることはできないかもしれませんが、特に時間、リソース、または専門知識が限られている状況では、支援や事前翻訳ツールとして大きな利益をもたらす可能性があります。新しい技術には常に多くの課題と改善の機会があり、その可能性を完全に引き出すためにはさらなる研究と実験が必要です。
方法論
GPT-3のような言語モデルが、比喩や慣用表現を含む言語の特殊なケースにおいて、従来の機械翻訳エンジンと比較してどのように慣用的な翻訳を処理するかを探るために、私たちは実験を行いました。
慣用表現の選択
「今日はここまでにしよう」「連絡してね」「The CAT’s out of the bag」など、よく使われる英語のイディオムを10個選びました。 これらの表現は、翻訳システムにとって難題として知られています。なぜなら、文字通りの同等性ではなく、文化的および文脈的な適応が求められるからです。
テストされた翻訳エンジンとモデル
各イディオムは、次のものを使用して翻訳されました。
- Google 翻訳
- Amazon 翻訳
- Microsoft 翻訳者
- GPT-3 (ChatGPT) – 2つのアプローチを使用:
- 指示なしの直接翻訳
- より比喩的で慣用的な表現を促された第二のバージョン

評価プロセス
翻訳された出力は、7つのターゲット言語のネイティブスピーカーの翻訳者によってレビューされました: ブラジルポルトガル語、スペイン語、フランス語、ドイツ語、イタリア語、中国語、韓国語。 各文について、レビュアーは評価しました。
- 元のイディオムの意味が保持されたかどうか
- ターゲット言語での表現の自然さ
- 文法、構文、および意味の精度
各翻訳は1から5のスケールで評価されました:
- 5: 正しい意味と自然な響きの言葉
- 1: 不正確、紛らわしい、または不自然な翻訳(「泣きたい」レベル)
さらに、ChatGPTに他のエンジンの翻訳を評価するよう依頼しました。これには、定性的なテキストフィードバックと数値スコアの両方を提供します。 これにより、単なる翻訳ジェネレーターとしてではなく、評価者としての能力を評価することができました。
研究の限界
これは探索的研究であったことに注意することが重要です。
- サンプルは10のイディオムに制限され、言語ごとに1人の人間のレビュアーがいました。
- すべての評価には、ある程度の主観性と個人の好みがあります。
- GPT-3のパフォーマンスはモデルの特定のバージョンを反映しており、更新に伴って進化する可能性があります。
これらの制約にもかかわらず、見つけた結果は、特に言語的に微妙で文化に依存するシナリオにおける現在のモデルの能力と限界について貴重な洞察を提供します。
免責事項
(本物の研究免責事項、軽視しないでください)
ChatGPTの言語能力の可能性を探ることを目指しましたが、この研究では翻訳の一側面、すなわち翻訳者が言語的な慣用句や高度に比喩的な難解なケースを処理する能力のみを評価したことに注意することが重要です。 翻訳の他の側面、例えば文化的および文脈的な理解には、異なる評価方法や基準が必要になる場合があります。
この研究のサンプルサイズは10のイディオムと各言語につき1人のレビュアーに限定されており、これは英語のイディオム表現の全範囲やプロの翻訳者の視点と専門知識の範囲を代表していない可能性があります。 したがって、この研究の結果は慎重に解釈する必要があり、他のコンテキストやドメインに一般化することはできません。
さらに、言語ごとに1人の査読者の意見や評価は主観的であり、個人的な偏見、経験、または好みに影響される可能性があります。 他の主観的な評価と同様に、結果にはある程度のばらつきと不確実性があります。 信頼性と妥当性を高めるために、将来の研究では複数のレビューア、ブラインド評価、または相互評価の信頼性測定を含めることができます。
また、ChatGPTの言語機能は静的なものではなく、モデルがさらに訓練され、微調整されるにつれて時間の経過とともに変化する可能性があることも注目に値します。 したがって、この研究の結果は、特定の時点でのモデルのパフォーマンスのスナップショットと見なすべきであり、現在または将来の能力を反映していない可能性があります。
最後に、この研究は、ChatGPTの翻訳の有用性や制限について、決定的または断定的な主張をすることを意図したものではありません。 むしろ、それは自然言語処理と機械翻訳の分野における将来の研究開発のための予備調査および出発点として役立つことを意図しています。 新興技術と同様に、まだ多くの課題と改善の機会があり、その可能性を十分に探るためにはさらなる実験とコラボレーションが必要です。
Unlock the power of glocalization with our Translation Management System.
Unlock the power of
with our Translation Management System.








