اختبرنا Chat GPT للترجمة - إليك البيانات


وضعت الأبحاث الحديثة التي أجرتها Bureau Works هذا الأمر تحت الاختبار، حيث قارنت بين GPT-3 ومحركات الترجمة الآلية الرئيسية من Google وAmazon وMicrosoft. ركزت الدراسة على أحد أصعب التحديات في التوطين: التعبيرات الاصطلاحية. لماذا؟ لأن الترجمات الحرفية لا تنجح عندما تتعامل مع عبارات مثل "The cat’s out of the bag" أو "Let’s call it a day."
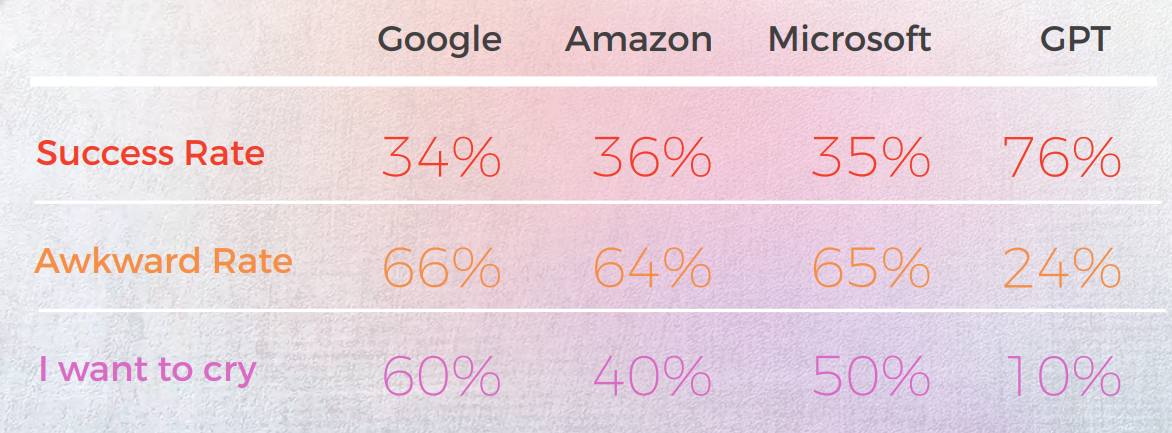
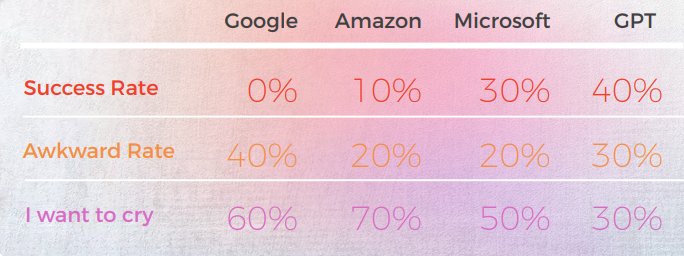
كانت النتائج مفاجئة. قدمت GPT-3 ترجمات دقيقة وطبيعية تصل إلى 90% من الوقت، بينما كانت المحركات التقليدية تتراوح بين 20% و50% — وغالبًا ما أنتجت مخرجات محرجة تم تقييمها بـ "أريد أن أبكي" من قبل اللغويين الأصليين.
في عالم يمكن أن تؤدي فيه الفروق اللغوية الدقيقة إلى نجاح أو فشل رسالتك، تسلط هذه الاكتشافات الضوء على كل من الوعد والقيود الحالية للذكاء الاصطناعي في الترجمة الاحترافية.
هنا ملخص لأهم نتائجنا الرئيسية:
- تفوقت GPT-3 باستمرار على محركات الترجمة التقليدية (Google و Amazon و Microsoft) في التعامل مع التعبيرات الاصطلاحية - حيث وصلت إلى دقة تصل إلى 90٪ في لغات مثل البرتغالية والصينية.
- كافحت المحركات التقليدية مع الاستعارة واللغة التصويرية، وغالبًا ما تقدم ترجمات حرفية كانت صحيحة نحويًا ولكنها متوقفة من الناحية الدلالية - حتى أن بعضها حصل على تقييمات "أريد أن أبكي" من المراجعين الأصليين.
- أخذت Microsoft المزيد من المخاطر، حيث قدمت ترجمات أكثر جرأة انحرفت أحيانًا عن الأصل ولكنها شعرت بأنها أكثر طبيعية - على الرغم من أن GPT واجهت صعوبة في تقييم هذه الخيارات الإبداعية.
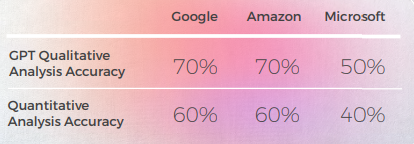
- كان التحليل النوعي لـ GPT قويًا، لكنه واجه صعوبة في تعيين درجات عددية متسقة، خاصة عند التمييز بين التصنيفات متوسطة المدى مثل 3 مقابل. 4.
- في كل لغة تقريبًا، أدى التكرار الثاني لGPT - عندما يُطلب منه إصدار أكثر تصويرية - إلى تحسين الوضوح والنبرة والملاءمة الثقافية.
- كانت اللغة الكورية هي اللغة الأكثر تحديًا لكل من MTs التقليدية و GPT-3، حيث أظهرت أداءً أقل بكثير في جميع المجالات.
- أثبت GPT-3 قيمته ليس فقط كـ المترجم ولكن أيضًا كأداة للتقييم والمراجعة، حيث يساعد في تحديد العبارات الغير ملائمة أو غير الدقيقة ويقدم بدائل.
حقق GPT دقة بنسبة 90% في الأمثال الصينية—واجهت MTs صعوبة
تمت كتابة التحليل التالي بواسطة اللغوي الإنجليزي/الصيني جيمس هو.

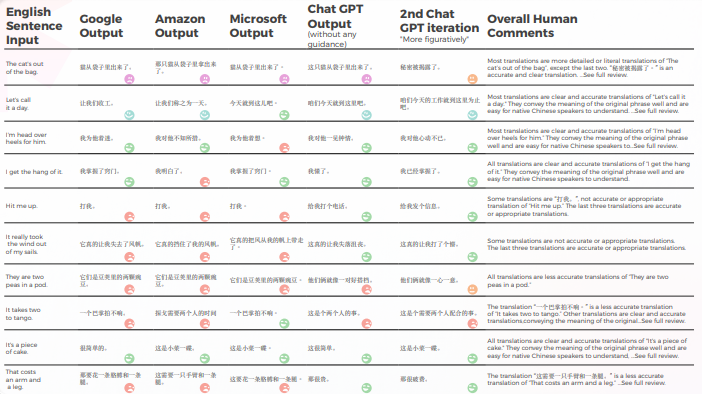
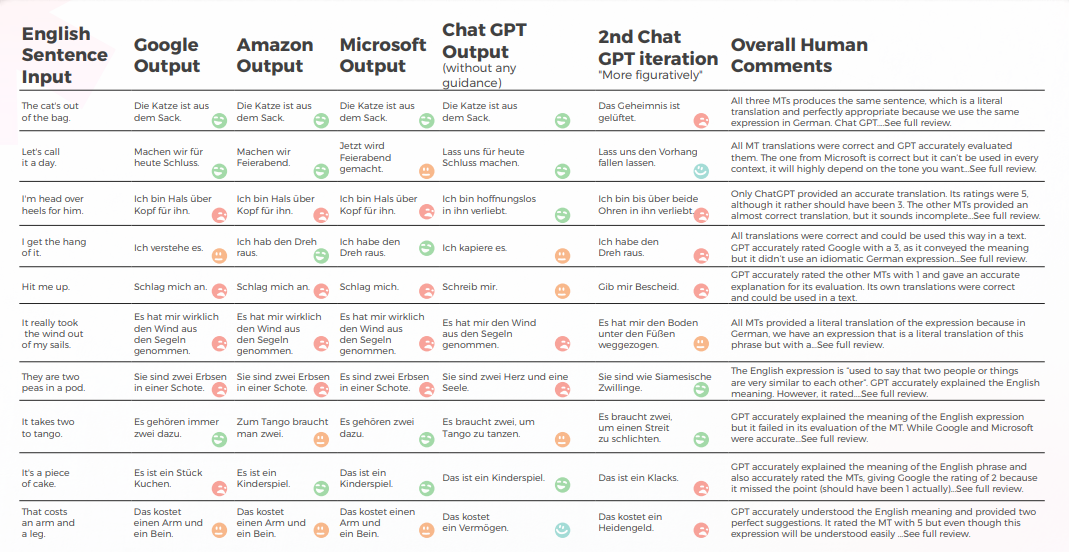
بشكل عام، كافحت جميع المحركات مع الطبيعة المجازية للغة، وغالبًا ما تخطئ في الحرفية المفرطة. على سبيل المثال، الترجمة "让我们称之为一天"." هي ترجمة أكثر حرفية ومحرجة إلى حد ما ل "دعونا ننهي العمل لهذا اليوم". إنه ينقل معنى العبارة الأصلية، لكن الصياغة محرجة إلى حد ما وقد لا يكون من السهل على المتحدثين الأصليين باللغة الصينية فهمها.
في حين أنها تنقل بدقة معنى العبارة الأصلية، إلا أن الصياغة محرجة إلى حد ما وقد تكون أقل وضوحًا للمتحدثين الأصليين.
الناتج من منظور نوعي
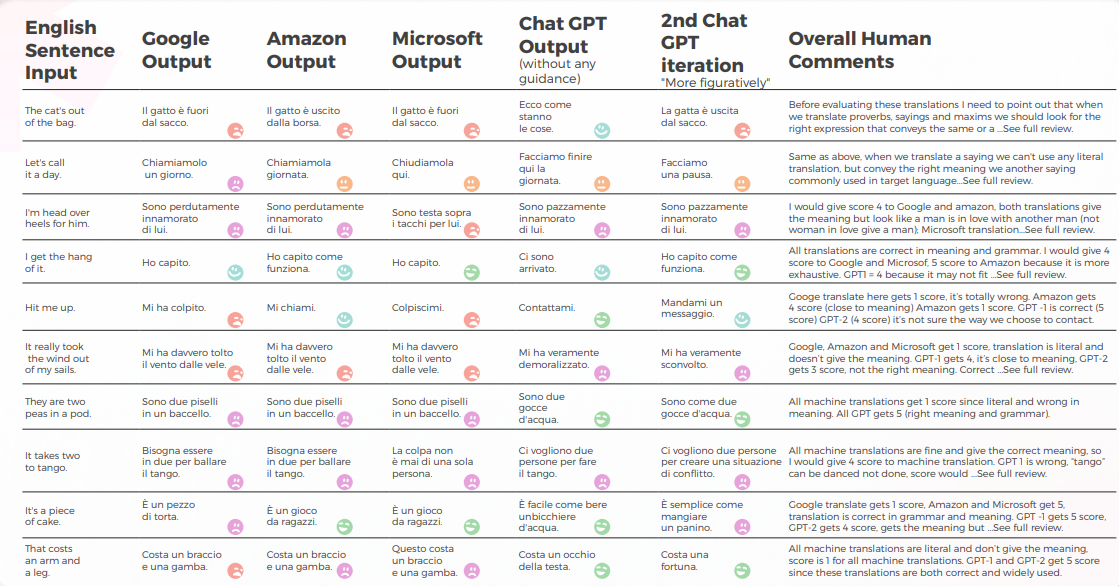
يقدم الجدول أدناه تحليلاً تركيبياً لعشر جمل اصطلاحية إنجليزية مترجمة إلى الصينية، كما أجراه فريقنا من اللغويين.
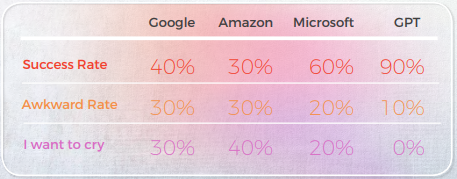
فيما يتعلق بالجودة في الترجمة، قام GPT بعمل رائع في التفسير السياقي. على سبيل المثال، "تم الكشف عن السر.""هي ترجمة دقيقة وواضحة لعبارة "The cat’s out of the bag". في 9 من أصل 10 جمل، كان المحتوى متكيفًا بشكل جيد، ومفهومًا، وينقل المعنى المناسب. على عكس محركات الترجمة الآلية الثلاثة، لم يكن لدى GPT أخطاء محرجة من نوع "أريد أن أبكي".
يحتوي الجدول أدناه على تحليل البيانات الأولية.
تقييم نماذج GPTs
تحليل ونتائج رئيسية
- كانت نتائج Google وAmazon متشابهة للغاية، حيث انحرفت قليلاً عن بعضها البعض، مما يعكس أخطاء واختيارات مجازية متشابهة. على سبيل المثال، الترجمة "打我"." ليست ترجمة دقيقة أو مناسبة ل "تواصل معي". العبارة "Hit me up" تعني التواصل أو الاتصال بشخص ما، عادةً عبر الهاتف أو الرسائل النصية. العبارة الصينية "打我" تعني "اضربني" ، ولا تنقل معنى العبارة الأصلية.
- اتخذت Microsoft خيارات أكثر جرأة عندما يتعلق الأمر بالتكيف اللغوي للتعابير.واجهت GPT صعوبة أكبر في تقييم الخيارات المجازية لشركة Microsoft كلما ابتعدت أكثر.
- كان لدى GPT-3 وقت أسهل مع التحليل النوعي الذي ينتج تحليلاً نصياً مقنعاً (على الرغم من دقة 70٪ فقط).على الرغم من أن تحليل GPT الواضح فشل في تحديد 30٪ من الحالات. تزامن هذا مع خيارات مجازية كانت حرفية ومفهومة ولكنها انحرفت عن الخطاب اليومي.واجه GPT-3 صعوبة في ترجمة التحليل النوعي إلى درجة. على الرغم من أن الدرجات كانت دقيقة بنسبة 60٪ بشكل عام، إلا أنه كان من الصعب التمييز بين الدرجات المتشابهة مثل 3 مقابل 4.
- كان الاختلاف الشديد في الدرجات من 1 إلى 5 أسهل في الفهم وأكثر توافقًا مع التعليقات العامة التي تشير إلى ما يلي:
- ربما لم تتم معايرة معايير التسجيل بشكل كاف مع GPT-3
- ربما يمكن أن يكون التسجيل الثنائي أكثر صلة من تسجيل التدرج
- • على الرغم من أن أداء Microsoft من الناحية الكمية كان مشابهًا لأداء Google و Amazon، إلا أنه عند التعمق في التفاصيل الدقيقة للغة، اتخذت Microsoft خيارات أكثر جرأة وحققت نتائج أفضل من منظور نوعي، لكنها لا تزال متأخرة كثيرًا عن GPT-3 فيما يتعلق بالدقة والتكيف الثقافي. على سبيل المثال، الترجمة "我掌握了窍门。"هي ترجمة واضحة ودقيقة ل"أنا أتمكن منه". إنه ينقل معنى العبارة الأصلية جيدًا ويسهل على المتحدثين الأصليين باللغة الصينية فهمه. كما أنها طريقة مجازية وتعبيرية أكثر للتعبير عن الأفكار المتعلقة بفهم أو إتقان شيء ما مقارنةً بالترجمات المحتملة الأخرى.
التطبيقات العملية والقيود
في هذا التحليل، قدم GPT-3 سياقًا وتكيفًا أفضل من نماذج الترجمة الآلية السابقة.
بينما لا يوجد أي من المحركات موثوقًا بما يكفي ليحل محل البشر (على الأقل في سياق هذه الدراسة)، يظهر GPT-3 قدرة واضحة على مساعدة المترجمين والمراجعين البشريين في عملية الترجمة وتقييم اللغة.
الفرنسية: فشلت محركات الترجمة الآلية في 60% من التعابير الاصطلاحية—برز GPT
تمت كتابة التحليل التالي بواسطة اللغوي الإنجليزي/الفرنسي Laurène Bérard.

بشكل عام، كافحت جميع المحركات مع الطبيعة المجازية للغة، وغالبًا ما تخطئ في الحرفية المفرطة.
الناتج من منظور نوعي
يقدم الجدول أدناه تحليلاً تركيبياً لعشر جمل اصطلاحية إنجليزية مترجمة إلى الفرنسية، كما أجراه فريقنا من اللغويين.

فيما يتعلق بالجودة في الترجمة، قام GPT بعمل رائع في التفسير السياقي. بدون أي توجيه، كان GPT خاطئًا تمامًا في "The cat’s out of the bag" ولكنه كان صحيحًا مع المزيد من التوجيه، وكانت ترجماته الثلاث غير مكتملة نحويًا وبالتالي كان من الصعب فهمها لـ "It takes two to tango".
كان المحتوى بشكل عام متكيفًا جيدًا، ومفهومًا، ونقل المعنى المناسب. واجهت محركات الترجمة الآلية الثلاثة معدلًا عاليًا من "أريد أن أبكي" بينما حتى بدون سياق كان المترجم سيخمن أنها لم تكن مقصودة حرفيًا (مثلًا. "دعنا ننهي العمل لهذا اليوم"، وهو أمر واضح تماما ولكن أسيء فهمه تماما من قبل محرك Google.
يحتوي الجدول أدناه على تحليل البيانات الأولية.
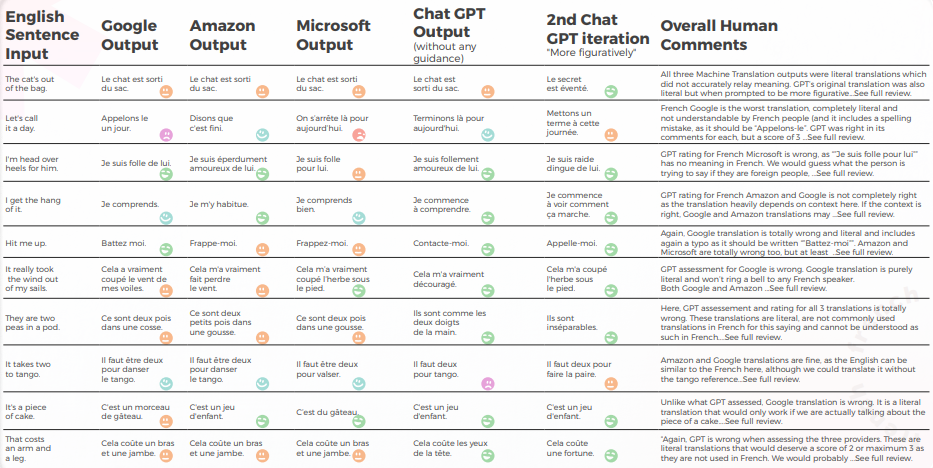
تقييم نماذج GPTs تقييم
تحليل ونتائج رئيسية
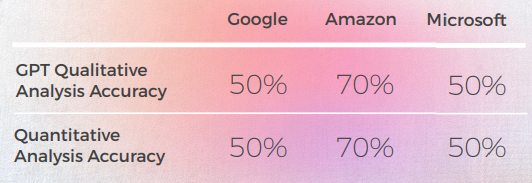
- على الرغم من الترجمة الصحيحة 8 مرات من أصل 10، كان تحليل GPT للمحركات الثلاثة غالبًا خاطئًا، حيث ذكرت حوالي 50% من الحالات أن ترجمتها كانت جيدة بينما لم تكن كذلك.
- على الرغم من أن تحليل GPT الواضح فشل في تحديد المشكلات في 30 إلى 50٪ من الحالات، إلا أن هذا تزامن مع الخيارات التي كانت حرفية وكان من الممكن أن تكون صحيحة إذا لم تتعامل مع التعبيرات الاصطلاحية.
- فشل GPT في اكتشاف مشكلتي التهجئة من Google ("Appelons le" و "Battez moi").كانت التحليلات النوعية والكمية لـ GPT متسقة عالميًا مع بعضها البعض.واجهت GPT صعوبة أكبر في تقييم ترجمات Microsoft و Google.
- اتخذت Microsoft خيارات أفضل عندما يتعلق الأمر بالتكيف اللغوي مع التعابير الاصطلاحية.
- كان لدى Google و Amazon نتائج متشابهة جدا، مع انحراف طفيف فقط عن بعضهما البعض. تميزت Microsoft عن الاثنين.
- في إحدى الحالات (تعبير التانغو)، قامت GPT بتقييم ترجمة جيدة من Microsoft على أنها خاطئة (درجة 2) بينما كانت مفهومة وجيدة بنفس القدر مثل ترجمات Google وAmazon التي قيمتها GPT بشكل إيجابي (درجة 5)، ولكن يمكن تفسير ذلك بحقيقة أن Microsoft لم تكن حرفية مثل المحركين الآخرين، حيث اختارت ذكر الفالس بدلاً من التانغو.
- اتخذت Microsoft خيارات أكثر جرأة وقدمت نتائج أفضل من منظور نوعي، لكنها لا تزال متأخرة كثيرًا عن GPT عندما يتعلق الأمر بالدقة والتكيف الثقافي.
التطبيقات العملية والقيود
في هذا التحليل، قدم GPT تكييفًا وسياقًا أفضل بكثير من محركات الترجمة الآلية الخاصة بأمازون وجوجل ومايكروسوفت. على الرغم من أنه ليس من الملائم استبدال نماذج الترجمة الآلية التقليدية بنماذج أكبر مثل GPT-3 بسبب التكاليف الحسابية العالية وتناقص العوائد الحدية عندما يتعلق الأمر بالخطاب غير المجازي، يمكن أن يكون GPT-3 حليفًا قوية للإنسان عندما يتعلق الأمر بتقديم الاقتراحات وتحديد الأخطاء المحتملة وكذلك الفرص للتحسين.
على الرغم من أن محركات الترجمة الآلية "تكاد" تكون هناك، إلا أن هذا "التكاد" يصبح من الصعب التعامل معه بشكل متزايد كما أثبت GPT هنا.
بينما لا يوجد أي من المحركات موثوقًا بما يكفي ليحل محل البشر (على الأقل في سياق هذه الدراسة)، يظهر GPT قدرة واضحة على مساعدة المترجمين والمراجعين البشريين في عملية الترجمة وتقييم اللغة.
تفوق GPT على جميع محركات الترجمة الآلية في التعابير الألمانية بنسبة 30%
تمت كتابة التحليل التالي بواسطة اللغوي الإنجليزي/الألماني أولغا شنايدر.

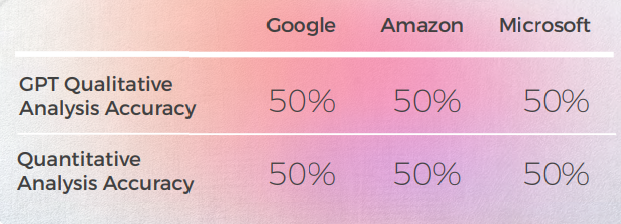
بشكل عام، أنتجت GPT الترجمة الأكثر دقة. كان دائمًا يحلل الجملة الإنجليزية بدقة وعادةً ما يمكنه تحديد ما إذا كانت الترجمة الآلية حرفية أو اصطلاحية، لكنه فشل في اكتشاف الترجمة الخاطئة بنسبة 50% من الوقت.
الناتج من منظور نوعي
يقدم الجدول أدناه تحليلاً تركيبياً لعشر جمل اصطلاحية إنجليزية مترجمة إلى الألمانية، كما أجراه فريقنا من اللغويين.

ينتج GPT نتائج جيدة 8 من أصل 10 مرات في المحاولة الأولى و 7 من أصل 10 مرات في المحاولة الثانية. على سبيل المثال، كان GPT فقط قادرًا على تقديم ترجمات اصطلاحية دقيقة لعبارة "أنا مغرم به جدًا" و"تواصل معي".
كان آخر إنتاج مجازي للغاية قد أنتج 4 جمل جيدة، بينما كانت الجمل الأخرى إما صحيح أو "أريد أن أبكي". بشكل عام، أنتجت أمازون ومايكروسوفت ترجمات أفضل قليلاً من جوجل.
يحتوي الجدول أدناه على تحليل البيانات الأولية.
تقييم تقييمات GPTs
تحليل ونتائج رئيسية
- لدى GPT معرفة جيدة إلى حد ما بالتعابير الاصطلاحية الألمانية، حتى تلك التي لم تتطابق تمامًا مع الجملة الإنجليزية كانت تعابير اصطلاحية من فئة مشابهة. على سبيل المثال: "دعنا نسحب القابس" و "دعنا نسدل الستار" ل "دعنا ننهي اليوم". إنه يفهم المعنى العام لهذه العبارات المتعلقة ب "النهاية" ويمكن أن يكون مصدراً مفيداً للإلهام.عندما يتعلق الأمر بالتعبيرات الإبداعية، يبدو أن GPT يستلهم من العبارات الإنجليزية، حيث يقترح الترجمة الألمانية الحرفية لعبارة "أنا أحبه من الرأس إلى أخمص القدمين" كبديل إبداعي لعبارة "أنا مغرم به حتى النخاع".
- كانت تقييمات ترجمة GPTs إما ناجحة أو فاشلة، وثبت أنها غير موثوقة. في إحدى الحالات، صنفت ترجمة Google على أنها 2، ولم يكن من الواضح سبب عدم كونها 1 كما كان ينبغي أن تكون.
- تشترك الألمانية والإنجليزية في العديد من التعبيرات الاصطلاحية، مما يجعل الترجمة أسهل. لكن التعبيرات الغريبة عن الألمانية (على سبيل المثال. "إنهما حبتان في جراب واحد" أو "إنها سهلة للغاية") ينتهي بهم الأمر بترجمتها حرفيًا. في حالة البازلاء، على عكس محركات الترجمة، أدركت GPT أنها بحاجة إلى تقديم تعبيرات حول "الثنائيات". ومع ذلك، فإن التعبيرات التي قدمتها - على الرغم من دقتها وشيوع استخدامها - لم تنقل المعنى الصحيح.
التطبيقات والقيود العملية
قدمت GPT ترجمات أفضل من Google و Amazon و Microsoft. على الرغم من أنه ليس موثوقًا بنسبة 100%، إلا أنه يمكن أن يوفر نقطة انطلاق أفضل لتحرير الترجمة الآلية مقارنة بالمحركات الثلاثة الأخرى. بينما تُعتبر التعابير الاصطلاحية مهمة، هناك مشكلة أخرى غالبًا ما تُواجه في الترجمة الآلية للنصوص من الإنجليزية إلى الألمانية: هيكل الجمل المعقد الذي يكون قريبًا جدًا من النص الأصلي. سيكون من المهم أن نرى كيف يحل GPT هذه المشكلة.
عندما يتعلق الأمر بالتقييم، فإن GPT ليست أداة جيدة، حيث أن تقييمها للترجمات الألمانية دقيق بنسبة 50٪ فقط.
كان من المثير للاهتمام رؤية ثلاثة أشياء أخرى:
- هل يمكن لـ GPT التنافس مع DeepL للغة الألمانية؟ بينما قد يقدم GPT ترجمات جيدة، فإن DeepL ينتج ترجمات ألمانية جيدة ويقدم أيضًا مجموعة من الميزات التي تبسط عملية الترجمة (يتم ترجمة مسرد المصطلحات بشكل صحيح مع الجمع والحالة الصحيحة، وتحرير بنقرة واحدة، وإكمال تلقائي للجمل بعد كتابة كلمة أو كلمتين لتسريع إعادة الصياغة). يجب أن تكون ترجمة GPT أفضل بشكل كبير من ترجمة DeepL لتعويض نقص الميزات.
- هل يمكن تحسين دقة GPT بمزيد من السياق، مثل فقرة تحتوي على العبارة؟إذا كانت Google قادرة على التعرف على النص الذي تم إنشاؤه بواسطة الذكاء الاصطناعي، فكيف ستتعامل مع ترجمات GPT بأقل قدر من التحرير أو بدونه؟ هل يمكنه اكتشاف "نمط GPT" ومعاقبة نص في نتائج البحث الخاصة به؟
باختصار، في حالته الحالية، يمكن أن يكون GPT مصدر إلهام لأدمغتنا البشرية المحدودة. يمكنه أن يقدم ترجمات لائقة. أكثر من ذلك، يمكن أن يساعدنا في إعادة صياغة التعبيرات المفرطة الاستخدام، ابحث عن الاستعارات، وفكر خارج الصندوق.
الإيطالية: أعادت محركات الترجمة الآلية ترجمات حرفية في 70% من الحالات
تمت كتابة التحليل التالي بواسطة اللغوي الإنجليزي/الإيطالي Elvira Bianco.

بشكل عام، كافحت جميع المحركات مع الطبيعة المجازية للغة، وغالبًا ما تخطئ في الحرفية المفرطة.
الناتج من منظور نوعي
يقدم الجدول أدناه تحليلاً تركيبياً لعشر جمل اصطلاحية إنجليزية مترجمة إلى الإيطالية، كما أجراه فريقنا من اللغويين.
الترجمة الآلية أعطت ترجمة حرفية بعيدة جدًا عن المعنى الصحيح. نقلت GPT المعنى والتعبير الصحيحين بنسبة 70٪، أما بالنسبة لـ 30٪ المتبقية فقد استخدمت تعبيرات مقبولة لكنها ليست شائعة الاستخدام أو لا تُعتبر مثل الكلام الطبيعي للناطقين الأصليين.
يحتوي الجدول أدناه على تحليل البيانات الأولية.
تقييم نماذج اللغة الكبيرة Evaluation

تحليل و رئيسي النتائج
- Google Translate يحصل على ترجمة واحدة صحيح ويقترب من المعنى في جملتين.
- Amazon أعطت 50% صحيح المعنى حتى لو لم تستخدم الطريقة الأكثر شيوعًا لنقل القول الإنجليزي في اللغة الإيطالية.
- قدمت Microsoft 3 إجابات صحيحة تقترب من أقوال إيطالية مشابهة.
- بينما يعتمد Chat GPT الأول عادةً على الترجمة الآلية، فإن Chat GPT الثاني والثالث عادةً ما يقدمان المعنى الصحيح ويضيفان اقتراحات ترجمة قيمة.
التطبيقات والقيود العملية
كما هو محدد في https://it.wiktionary. org/wiki/espressione_idiomatica، عادةً ما يكون التعبير الاصطلاحي النموذجي للغة ما غير قابل للترجمة حرفيًا إلى لغات أخرى، إلا عن طريق اللجوء إلى التعبيرات الاصطلاحية للغة التي يُترجم إليها بمعاني مشابهة للتعبيرات الاصطلاحية للغة التي يُترجم منها. من الواضح أن الترجمة الآلية التي تنتجها أكثر آلات الترجمة استخدامًا اليوم (Google, Amazon, Microsoft) كانت غير موثوقة، ومع ذلك أثبت GPT-3 قدرته بنسبة 70% على إعطاء المعنى الصحيح وتقديم اقتراحات جيدة في تكييف المحتوى.
ليس من غير المحتمل أنه في المستقبل القريب ستتمكن الآلات أيضًا من حفظ التعبيرات الاصطلاحية، ولكن صحيح الآن نحتاج إلى البشر لترجمة المعاني نفسها من لغة إلى أخرى.
اللغات مليئة بالفروق الدقيقة، والتلميحات المزدوجة، والإشارات، والتعابير الاصطلاحية، والاستعارات التي لا يمكن أن يدركها إلا الإنسان.
كانت اللغة الكورية الأقل دقة عبر جميع المحركات التي تم اختبارها
تمت كتابة التحليل التالي بواسطة اللغوي الإنجليزي/الكوري Sun Min Kim.

الناتج من منظور نوعي
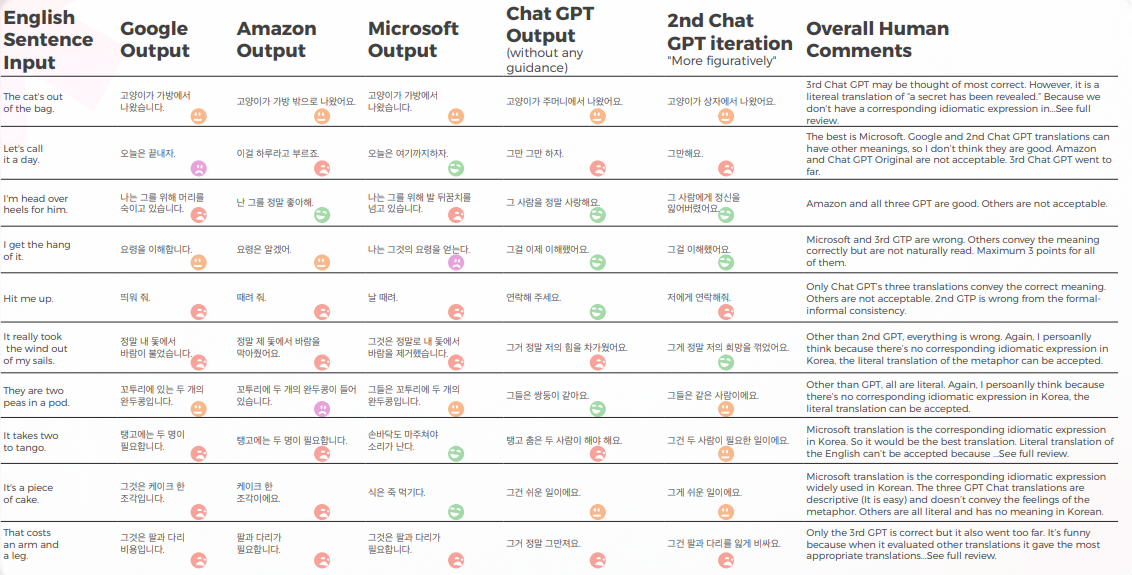
يقدم الجدول أدناه تحليلاً تركيبياً لعشر جمل اصطلاحية إنجليزية مترجمة إلى الكورية، كما أجراه فريقنا من اللغويين.
تترجم معظم المحركات التعبيرات الاصطلاحية حرفيًا، بينما يحاول GPT الترجمة بشكل وصفي قدر الإمكان بدون استخدام الاستعارات (على سبيل المثال، "قطعة من الكعكة" تعني "سهل"، بينما في كوريا، لدينا تعبير اصطلاحي مشابه ينقل نفس المعنى كما فعلت Microsoft).
ترجمات GPT الثلاث غير متسقة. البعض يزداد سوءًا مع التكرار.
يحتوي الجدول أدناه على تحليل البيانات الأولية.
يعرف GPT المشاكل عندما تسوء الترجمات. لكن لا يُعتبر صحيحًا في الحكم على الأفضل.
لدى GPT نفسها مشكلات في التعامل الرسمي وغير الرسمي وما إلى ذلك) ويمكنها تقييم هذه المشكلة.
تقييم GPTs تقييم

تحليل و رئيسي Findings
لأن الأصول الإنجليزية في هذه الدراسة هي تعبيرات اصطلاحية، فإن الأمر معقد بعض الشيء لأن عليك الاختيار بين الاستعارة أو الوصف المباشر. لكن بالنسبة لبعض التعابير الاصطلاحية حيث أن اللغة الكورية لديها تعبيرات اصطلاحية مشابهة تنقل نفس المعنى، فقد فشلت معظم المحركات في ابحث عن تلك التعبيرات مع بعض الاستثناءات القليلة (يرجى الاطلاع على ورقة العمل وابحث عن تلك التي حصلت على درجة 5 مني).
بالنسبة للآخرين، فكرتي الشخصية هي أنه إذا كان الاستعارة نفسها يمكن أن تنقل المعنى، يمكن اعتبار الترجمة الحرفية لها وربما يكون من الأفضل استخدام كلمة وصفية. بالطبع، إذا لم يكن للاستعارة سياق ثقافي في كوريا، فلا ينبغي ترجمتها حرفيًا. لكنها مسألة دقيقة وربما تعتمد على تفضيل أو مشاعر المترجم. لا أعتقد أن أي محرك لديه هذا المستوى من التفكير الشبيه بالإنسان حتى الآن.
التطبيقات العملية والقيود
أعتقد أنه يمكن استخدام معظم المحركات لأغراض ما قبل الترجمة. لكن بالنظر إلى الجودة، يجب أن يكون الهدف الأساسي هو الكفاءة فقط (أي، عدم الكتابة من الصفر). لمزيد من النصوص الوصفية، مثل الكتيبات، أرى أن MTPE أكثر تقدمًا بكثير من هذه التعبيرات الاصطلاحية. لذلك ، لا يزال هناك مجال للتحسين.
حقق GPT معدل نجاح 90% في التعابير الاصطلاحية البرتغالية البرازيلية
تمت كتابة التحليل التالي بواسطة اللغوي الإنجليزي/البرتغالي غابرييل فيرمان.

بشكل عام، كافحت جميع المحركات مع الطبيعة المجازية للغة، وغالبًا ما تخطئ في الحرفية المفرطة.
الناتج من منظور نوعي
يقدم الجدول أدناه تحليلاً تركيبياً لعشر جمل اصطلاحية إنجليزية مترجمة إلى البرتغالية، كما أجراه فريقنا من اللغويين.
تترجم معظم المحركات التعبيرات الاصطلاحية حرفيًا، بينما يحاول GPT الترجمة بشكل وصفي قدر الإمكان بدون استخدام الاستعارات (على سبيل المثال، "قطعة من الكعكة" تعني "سهل"، بينما في كوريا، لدينا تعبير اصطلاحي مشابه ينقل نفس المعنى كما فعلت Microsoft).
ترجمات GPT الثلاث غير متسقة. البعض يزداد سوءًا مع التكرار.
يحتوي الجدول أدناه على تحليل البيانات الأولية.
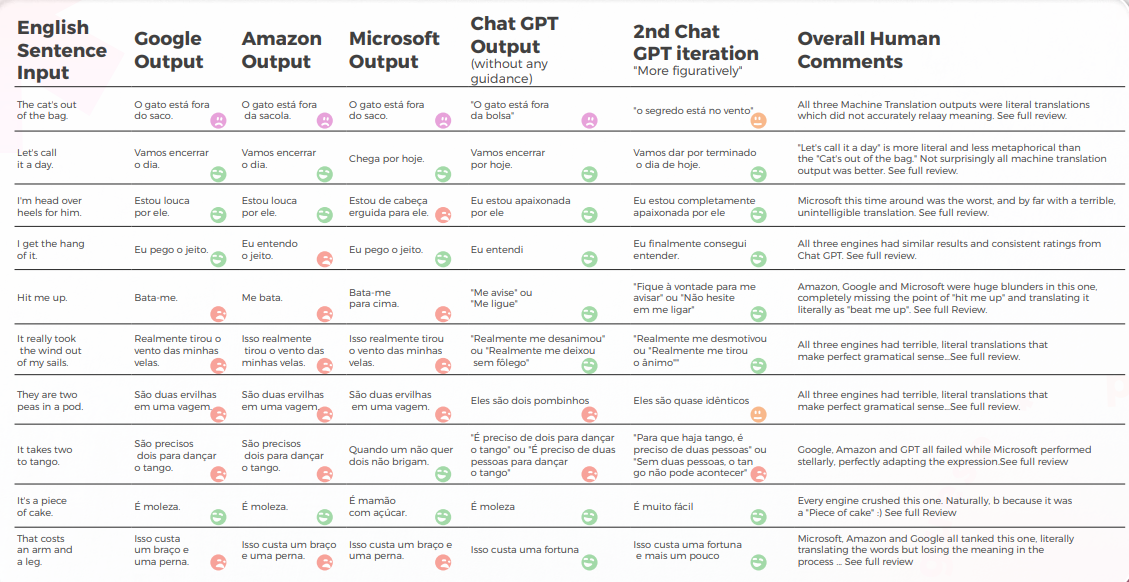
فيما يتعلق بالجودة في الترجمة، قام GPT بعمل رائع في التفسير السياقي. في 9 من أصل 10 جمل، كان المحتوى متكيفًا بشكل جيد، ومفهومًا، وينقل المعنى المناسب. على عكس محركات الترجمة الآلية الثلاثة، لم يكن لدى GPT أخطاء محرجة من نوع "أريد أن أبكي".
كانت الفرضية الأولية هي أنه سيكون هناك فرق كبير في الجودة بين النسخة الأولى والثانية من GPT، لكن جودة الترجمة كانت متشابهة في كلتا الحالتين.
تقييم تقييمات GPTs
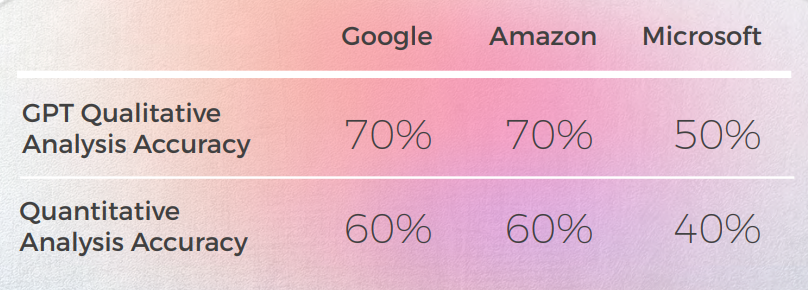
تحليل ونتائج رئيسية
- اتخذت Microsoft خيارات أكثر جرأة عندما يتعلق الأمر بالتكيف اللغوي للتعابير.واجهت GPT صعوبة أكبر في تقييم الخيارات المجازية لشركة Microsoft كلما ابتعدت أكثر.
- حققت Google و Amazon نتائج متشابهة للغاية، حيث انحرفتا قليلاً فقط عن بعضهما البعض، مما يعكس أخطاء بعضهما البعض وخياراتهما المجازية. من الواضح أن Microsoft برزت من الاثنين.
- كان لدى GPT-3 وقت أسهل مع التحليل النوعي الذي ينتج تحليلاً نصياً مقنعاً (على الرغم من دقة 70٪ فقط).على الرغم من أن تحليل GPT الواضح فشل في تحديد 30٪ من الحالات. تزامن هذا مع خيارات مجازية كانت حرفية ومفهومة ولكنها انحرفت عن الخطاب اليومي.واجه GPT-3 صعوبة في ترجمة التحليل النوعي إلى درجة.
- على الرغم من أن الدرجات كانت دقيقة بنسبة 60٪، إلا أنه كان من الصعب التمييز بين الدرجات المتشابهة مثل 3 مقابل 4.
- كان الاختلاف الشديد في الدرجات من 1 إلى 5 أسهل في الفهم وأكثر توافقًا مع التعليقات العامة التي تشير إلى ما يلي:
- ربما لم تتم معايرة معايير التقييم بشكل كافٍ مع GPT-3
- ربما يمكن أن يكون التقييم الثنائي أكثر ملاءمة من التقييم التدريجي. في حالة شاذة واحدة، قام Cchat GPT-3 بتقييم ترجمتين متشابهتين بطرق مختلفة جذريًا، حيث أعطى إحداهما 1 والأخرى 5، بينما كان يجب أن يكون كلاهما 1.على الرغم من أن أداء Microsoft من الناحية الكمية كان مشابهًا لـ Google و Amazon، إلا أنه عند التعمق في التفاصيل الدقيقة للغة، اتخذت Microsoft خيارات أكثر جرأة وحققت نتائج أفضل من منظور نوعي، لكنها لا تزال متأخرة كثيرًا عن GPT-3 فيما يتعلق بالدقة والتكيف الثقافي.
التطبيقات العملية والقيود
في هذا التحليل، قدم GPT-3 تكييفًا وسياقًا متفوقًا مقارنة بنماذج
الترجمة الآلية السابقة في البرتغالية البرازيلية. على الرغم من أنه ليس من الملائم استبدال نماذج الترجمة الآلية التقليدية بنماذج أكبر مثل GPT-3 بسبب التكاليف الحسابية العالية وتناقص العوائد الحدية عندما يتعلق الأمر بالخطاب غير المجازي، يمكن أن يكون GPT-3 حليفًا قوية للإنسان عندما يتعلق الأمر بتقديم الاقتراحات وتحديد الأخطاء المحتملة وكذلك الفرص للتحسين.
الحالات الحافة اللغوية مذهلة لأنها توضح بوضوح شديد كم يتبقى في القليل عندما يتعلق الأمر بنماذج اللغة. على الرغم من أنهم "تقريبًا" هناك، إلا أن هذا "تقريبًا" يصبح أصعب بشكل تدريجي للتعامل معه، وإذا لم يكن أصعب، فهو بالتأكيد أكثر تكلفة من منظور حسابي.
بينما لا يوجد أي من المحركات موثوقًا بما يكفي ليحل محل البشر (على الأقل في سياق هذه الدراسة)، يظهر GPT-3 قدرة واضحة على مساعدة المترجمين والمراجعين البشريين في عملية الترجمة وتقييم اللغة.
حصلت الترجمة الآلية الإسبانية على أقل من 30%—كان GPT الفائز الواضح
تم كتابة التحليل التالي بواسطة اللغوي الإنجليزي/الإسباني نيكولاس دافيلا.

بشكل عام، كافحت جميع المحركات مع الطبيعة المجازية للغة، وغالبًا ما تخطئ في الحرفية المفرطة.
الناتج من منظور نوعي
يقدم الجدول أدناه تحليلاً تركيبياً لعشر جمل اصطلاحية إنجليزية مترجمة إلى الإسبانية، كما أجراه فريقنا من اللغويين.

فيما يتعلق بالجودة في الترجمة، قام GPT بعمل مقبول وأفضل من الآخرين في السياق. في 7 من أصل 10 جمل، كان المحتوى واضحًا، ومُشكلًا بشكل جيد، ونقل المعنى المناسب، مع معدلات منخفضة من الإحراج و"أريد أن أبكي".
على الرغم من أن الفرضية الأولية كانت أن هناك سيكون فرق كبير في الجودة بين النسخة الأولى من GPT والتكرارات اللاحقة، إلا أن جودة الترجمة متشابهة في جميعها، التكرارات الثانية والثالثة أحيانًا تضيف أشياء غير ضرورية، مما يزيد قليلاً من معدل الإحراج.
يحتوي الجدول أدناه على تحليل البيانات الأولية.
تقييم تقييمات GPTs

تحليل ونتائج رئيسية
- كانت الترجمات الآلية حرفية للغاية، حيث كانت أمازون وجوجل متشابهتين جدًا بشكل عام، ومايكروسوفت كانت الأسوأ.
- حققت Google و Amazon نتائج متشابهة للغاية، حيث انحرفتا قليلاً فقط عن بعضهما البعض، مما يعكس أخطاء بعضهما البعض وخياراتهما المجازية. كان أداء Microsoft ضعيفًا، حيث كانت تنتج أحيانًا جملًا سيئة التكوين وتفتقد بعض أجزاء البناء النحوي.
- كان لدى GPT-3 وقت أسهل مع التحليل النوعي الذي ينتج تحليلاً نصياً متماسكاً، على الرغم من دقة 50٪ فقط.
- في كثير من الأحيان، كان التحليل النوعي لـ GPT-3 عامًا للغاية وأكثر تقييدًا بالمعنى الرئيسي والحرفي للجملة، دون النظر في التفاصيل الدقيقة للبناء والتغيير في المعنى. يبدو أن GPT غير قادر على التقاط مثل هذه الاختلافات وترجمتها إلى درجات كمية.
- أيضًا، قام GPT في كثير من الأحيان بتعيين نفس التحليل النوعي والدرجة الكمية العالية للجمل التي كانت سيئة البناء من الناحية النحوية، مما يبدو أنه يمثل قيدًا في نموذج GPT.واجه GPT-3 صعوبة في ترجمة التحليل النوعي إلى درجة.
- كونها دقيقة بنسبة 50٪ فقط لجوجل وأمازون ودقيقة بنسبة 30٪ فقط لمايكروسوفت. يبدو أن GPT كان يقيس فقط ما إذا كانت الجملة تنقل المعنى، ولكن لا توجد اختلافات في البناء أو التكوين الجيد.
- كان اختلاف النتيجة من 1 إلى 5 أسهل في الفهم وأكثر توافقًا مع التعليقات العامة التي تشير إلى ما يلي: ربما لم تتم معايرة معايير التقييم بشكل كافٍ لـ GPT-3. ربما يكون التقييم الثنائي أكثر ملاءمة من التقييم التدريجي. ربما لم تكن معايير التقييم أو نموذج GPT تأخذ في الاعتبار القضايا النحوية، بل كانت تركز فقط على نقل المعنى.
التطبيقات العملية والقيود
في هذا التحليل، قدم GPT-3 تكييفًا وسياقًا متفوقًا مقارنةً بنماذج الترجمة الآلية السابقة في الإسبانية اللاتينية.
يمكن أن يكون GPT-3 أداة قوية في مساعدة البشر على تحسين الترجمات عندما يشير إلى تقديم اقتراحات مفيدة وفرص للتحسين. ولكن، بقدر ما أستطيع أن أرى، لا يزال لديه قيود معينة.
على الرغم من أن النماذج الأكبر مثل GPT-3 يمكن أن تكون مفيدة، إلا أنه ليس من الملائم استبدال نماذج الترجمة الآلية التقليدية بها، بسبب التكاليف الحسابية الأعلى، حيث أنه عندما يتعلق الأمر بالنصوص غير المجازية، قد يقلل ذلك من المكاسب الهامشية.
بينما يظهر GPT-3 قدرة واضحة على مساعدة المترجمين والمراجعين البشريين في عملية الترجمة وتقييم اللغة، يجب أخذ الاعتبارات المالية في الحسبان عند تقييم استخدامه للنصوص غير المجازية.
الاستنتاجات
بينما يمكن أن يختلف أداء ChatGPT اعتمادًا على النص المحدد واللغة، تشير دراستنا إلى أن ChatGPT لديه القدرة على إنتاج ترجمات ذات جودة أعلى من محركات الترجمة التقليدية، خاصة عندما يتعلق الأمر بالتعامل مع التعبيرات الاصطلاحية والاستخدام الدقيق للغة.
ومع ذلك، من المهم ملاحظة أن ChatGPT بعيد كل البعد عن عدم ارتكاب الأخطاء ولا يزال لديه مجال هائل للتحسين، خاصة عندما يتعلق الأمر بالمطالبات أو مجالات اللغة الأكثر تعقيدًا.
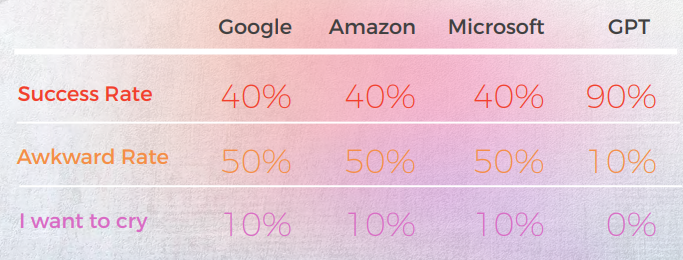
بصفته المترجم، كان ChatGPT أكثر نجاحًا من جميع محركات الترجمة الآلية التي تم اختبارها. بينما أظهرت اللغات نتائج مختلفة، كانت الكورية بوضوح استثناءً حيث كانت الجودة في الترجمة الآلية والجودة في GPT أقل بشكل ملحوظ مقارنةً باللغات الأخرى.
في جميع اللغات باستثناء الكورية، حقق ChatGPT معدل نجاح لا يقل عن 70٪ ولا يزيد عن 90٪، وكان أداؤه أفضل من الترجمة الآلية التقليدية. وحتى في اللغة الكورية، رغم أن الدرجات كانت منخفضة، إلا أنها كانت لا تزال أفضل من مخرجات محرك MT.
على عكس الترجمة الآلية، مع نموذج اللغة الكبير (LLM)، يمكن لتحسينات نفس المحتوى أن تحسن من جودة المخرجات. هذا رئيسي عند التفكير في التكاملات لأنه بينما مع الترجمة الآلية التقليدية سيكون ناتجك دائمًا هو نفسه مدخلك (ما لم يحصل المحرك على بيانات أو تدريب إضافي)، مع نموذج اللغة الكبير يمكن للمرء استكشاف عدة تفاعلات عبر API من أجل تحسين جودة الموجز.
تتمثل إحدى ميزات ChatGPT على محركات MT التقليدية في قدرته على التعلم والتحسين بمرور الوقت، حتى بدون بيانات تدريب إضافية. ويرجع ذلك إلى طبيعة LLMs، التي تم تصميمها لتحسين نماذجها اللغوية باستمرار بناءً على مدخلات جديدة. على هذا النحو، يمكن لـ ChatGPT أن يقدم قدرات ترجمة أكثر تكيفًا وديناميكية، مما قد يكون مفيدًا بشكل خاص في السيناريوهات التي تكون فيها اللغة أو المحتوى في تطور أو تغيير مستمر.ميزة أخرى ل ChatGPT هي معدل الإحراج المنخفض، وهو تحسن كبير مقارنة بمحركات الترجمة التقليدية التي غالبًا ما تنتج ترجمات محرجة أو غير مناسبة. قد يجعل هذا ChatGPT أكثر قبولًا وسهولة في الاستخدام للمستخدمين غير الخبراء الذين قد لا يمتلكون نفس المستوى من المعرفة اللغوية أو الثقافية مثل المترجمين المحترفين.
ومع ذلك، من المهم ملاحظة أن ChatGPT ليس بديلاً عن المترجمين البشريين، وهناك العديد من الحالات التي تكون فيها خبرة وحكم المترجم البشري ضرورية. لكن معدلات الإحراج المنخفضة بشكل ملحوظ في ChatGPT تفتح الباب أمام اعتماد أوسع للترجمات التي لا تعتمد على البشر.
كمقيم، كان أداء ChatGPT أكثر تباينًا، حيث تراوحت معدلات الدقة من 30٪ إلى 70٪. بينما يشير هذا إلى أن ChatGPT قد لا يكون فعالًا في تقييم محركات الترجمة الأخرى كما هو في اقتراح الترجمات، فمن الممكن أن يكون ذلك بسبب تعقيد و الجودة الخاصة بمحفزات التقييم، والتي قد تتطلب معرفة أكثر تخصصًا أو سياقية مما يمتلكه ChatGPT حاليًا. هناك حاجة إلى مزيد من البحث لاستكشاف إمكانات ChatGPT كمقيم، بالإضافة إلى حدوده وتحدياته.بشكل عام، تشير دراستنا إلى أن ChatGPT لديه قدرات ترجمة واعدة تستحق المزيد من الاستكشاف. على الرغم من أنه قد لا يكون قادرًا على استبدال أو تجاوز المترجمين البشريين وكالة ترجمة، إلا أنه يمكن أن يقدم فوائد كبيرة كأداة مساعدة أو أداة للترجمة المسبقة، خاصة في السيناريوهات التي تكون فيها الوقت أو الموارد أو الخبرة محدودة.
كما هو الحال مع أي تقنية ناشئة، لا تزال هناك العديد من التحديات والفرص للتحسين، وستكون هناك حاجة إلى مزيد من البحث والتجريب لفتح إمكاناتها بالكامل.
المنهجية
لاستكشاف كيفية تعامل نماذج اللغة مثل GPT-3 مع الترجمة الاصطلاحية مقارنة بمحركات الترجمة الآلية التقليدية، أجرينا تجربة تركز على الحالات اللغوية الحادة التي تتضمن الاستعارات والتعبيرات الاصطلاحية.
اختيار التعابير الاصطلاحية
لقد اخترنا 10 تعابير اصطلاحية إنجليزية شائعة الاستخدام، مثل "لننهي العمل لهذا اليوم"، و"تواصل معي"، و"أُفْصِحَ السِّرّ". تُعرف هذه التعبيرات بأنها تشكل تحديًا للأنظمة الترجمة، لأنها تتطلب التكيف الثقافي والسياقي بدلاً من التكافؤ الحرفي.
تم اختبار محركات ونماذج الترجمة
تمت ترجمة كل مصطلح باستخدام:
- Google Translate
- Amazon Translate
- Microsoft المترجم
- GPT-3 (ChatGPT) – باستخدام نهجين:
- ترجمة مباشرة بدون أي توجيه
- نسخة ثانية تم تحفيزها لتكون أكثر تصويرية واصطلاحية

عملية التقييم
تمت مراجعة المخرجات المترجمة من قبل اللغويين الناطقين باللغة الأم عبر سبع لغات مستهدفة: البرتغالية البرازيلية والإسبانية والفرنسية والألمانية والإيطالية والصينية والكورية. لكل جملة، قام المراجعون بتقييم:
- ما إذا كان معنى المصطلح الأصلي قد تم الحفاظ عليه
- طبيعة التعبير في اللغة المستهدفة
- القواعد وبناء الجملة والدقة الدلالية
تم تصنيف كل ترجمة على مقياس من 1 إلى 5:
- 5: المعنى الصحيح واللغة الطبيعية الصوتية
- 1: ترجمة غير صحيحة أو مربكة أو غير طبيعية (مستوى "أريد أن أبكي")
بالإضافة إلى ذلك، طلبنا من ChatGPT تقييم ترجمات المحركات الأخرى، من خلال تقديم ملاحظات نصية نوعية ودرجات رقمية. سمح لنا ذلك بتقييم قدرته كمقيم، وليس فقط كمولد للترجمة.
قيود الدراسة
من المهم ملاحظة أن هذه كانت دراسة استكشافية:
- اقتصرت العينة على 10 تعابير مع مراجع بشري واحد لكل لغة.
- تحمل جميع التقييمات درجة من الذاتية والتفضيل الفردي.
- أداء GPT-3 يعكس إصدارًا محددًا من النموذج وقد يتطور مع التحديثات.
على الرغم من هذه القيود، توفر النتائج رؤية قيمة حول قدرات ونواقص النماذج الحالية، خاصة في السيناريوهات التي تتطلب فهمًا لغويًا دقيقًا وتعتمد على الثقافة.
إخلاء المسؤولية
(إخلاء المسؤولية عن الأبحاث الحقيقية لا ينبغي الاستخفاف بها)
بينما سعينا لاستكشاف إمكانيات ChatGPT اللغوية، من المهم ملاحظة أن هذه الدراسة قامت بتقييم جانب واحد فقط من الترجمة، وهو القدرة على التعامل مع الحالات الحادة اللغوية المجازية العالية. قد تتطلب جوانب أخرى من الترجمة، مثل الفهم الثقافي والسياقي، أساليب ومعايير تقييم مختلفة.
حجم العينة في هذه الدراسة محدود بـ 10 تعابير اصطلاحية ومراجع واحد لكل لغة، مما قد لا يكون ممثلاً للنطاق الكامل للتعابير الاصطلاحية في اللغة الإنجليزية، أو نطاق وجهات النظر والخبرات للمترجمين المحترفين. على هذا النحو، يجب تفسير نتائج هذه الدراسة بحذر ولا يمكن تعميمها على سياقات أو مجالات أخرى.
علاوة على ذلك، فإن آراء وتقييمات المراجع الفردي لكل لغة ذاتية وقد تتأثر بالتحيزات الشخصية أو الخبرات أو التفضيلات. كما هو الحال مع أي تقييم شخصي، هناك درجة من التباين وعدم اليقين في النتائج. لزيادة موثوقية وصحة نتائجنا، يمكن أن تتضمن الدراسات المستقبلية مراجعين متعددين، تقييمات عمياء، أو مقاييس موثوقية بين المقيمين.
تجدر الإشارة أيضًا إلى أن القدرات اللغوية لـ ChatGPT ليست ثابتة وقد تتغير بمرور الوقت مع استمرار تدريب النموذج وضبطه بشكل أكبر. لذلك، يجب اعتبار نتائج هذه الدراسة بمثابة لمحة سريعة عن أداء النموذج في وقت معين، وقد لا تعكس قدراته الحالية أو المستقبلية.
أخيرًا، لا تهدف هذه الدراسة إلى تقديم أي ادعاءات نهائية أو قاطعة حول فائدة أو قيود ChatGPT للترجمة. بل يُقصد به أن يكون بمثابة تحقيق أولي ونقطة انطلاق للبحث والتطوير المستقبلي في مجال معالجة اللغة الطبيعية والترجمة الآلية. كما هو الحال مع أي تقنية ناشئة، لا تزال هناك العديد من التحديات والفرص للتحسين، وستكون هناك حاجة إلى المزيد من التجارب و التعاون لاستكشاف إمكاناتها بالكامل.
Unlock the power of glocalization with our Translation Management System.
Unlock the power of
with our Translation Management System.








