我们测试了 Chat GPT 的翻译 – 这是数据


每个人都在谈论 AI 如何改变翻译,但它真的能处理人类语言的细微差别吗?
Bureau Works 最近的研究对此进行了测试,将 GPT-3 与 Google、Amazon 和 Microsoft 的主要机器翻译引擎进行了比较。 该研究侧重于本地化中最棘手的挑战之一:惯用表达。 为什么?因为逐字翻译在处理像“猫已经出袋”或“今天就到此为止”这样的短语时并不奏效。
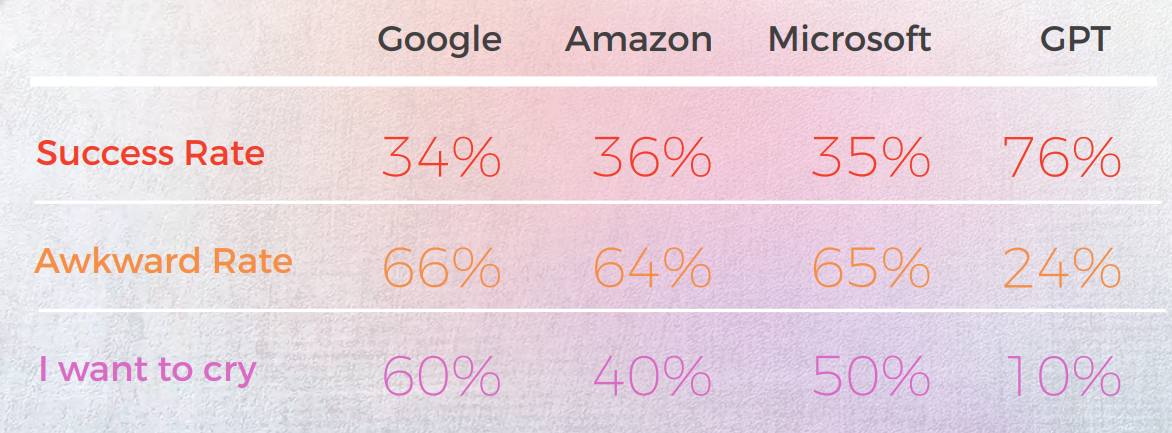
结果令人惊讶。 GPT-3在90%的情况下提供了准确且自然的翻译,而传统引擎则徘徊在20%到50%之间——并且经常产生让本地译员评价为“我想哭”的糟糕输出。
在一个语言细微差别可能决定信息成败的世界中,这些查找突出了AI在专业翻译中的潜力和当前局限性。
这是我们关键查找的总结:
- GPT-3 在处理惯用语方面始终优于传统的 MT 引擎(Google、Amazon、Microsoft)——在葡萄牙语和中文等语言中达到高达 90% 的准确率
- 传统引擎在隐喻和比喻语言方面苦苦挣扎,经常提供语法正确但语义不符的直译——有些甚至获得了母语评论家的“我想哭”评分。
- Microsoft冒了更多风险,提供更大胆的翻译,有时与原文有所不同,但感觉更自然——尽管GPT更难评估这些创造性的选择。
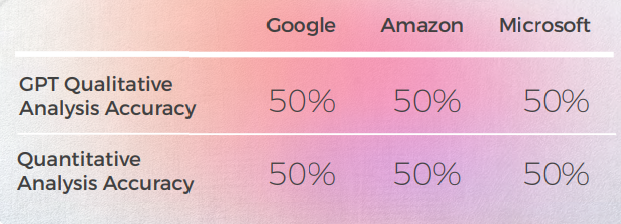
- GPT 的定性分析很强,但它难以分配一致的数字分数,尤其是在区分中等评级如 3 时。 4.
- 在几乎所有语言中,GPT 的第二次迭代——当被要求提供更形象的版本时——提高了清晰度、语气和文化契合度。
- 韩语是最具挑战性的语言,无论是对于传统的 MT 还是 GPT-3,整体表现都明显较低。
- 事实证明,GPT-3 不仅作为翻译很有价值,而且作为评估和修订的工具,帮助标记尴尬或不准确的措辞并提供替代方案。
GPT在中文成语中达到了90%的准确率——机器翻译表现不佳
以下分析由我们的英语/中文译员James Hou撰写。

总的来说,所有引擎都在与语言的隐喻性质作斗争,经常犯下过度的字面意义错误。 例如,翻译“让我们称之为一天。”“是”Let's call it a day“的更为直白且有些尴尬的翻译。 它传达了原短语的含义,但措辞有些别扭,对于以中文为母语的人来说可能不太容易理解。
虽然它准确地传达了原始短语的含义,但措辞有些尴尬,对于母语人士来说可能不太清楚。
从定性角度看输出
下表展示了由我们的译员团队进行的10个英语习语句子的中文翻译的综合分析。
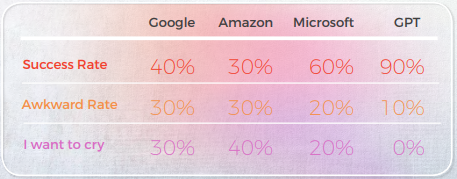
就翻译质量而言,GPT在语境化方面做得很出色。 例如,“秘密被揭露了。“CAT已经被揭露”是对“The cat’s out of the bag”的准确而清晰的翻译。 在10个句子中,有9个句子的内容适应良好、易于理解,并传达了适当的意义。 与三个机器翻译引擎相反,GPT 没有令人尴尬的“我想哭”错误。
下表包含原始数据分析。
GPTs 评估
分析和关键查找
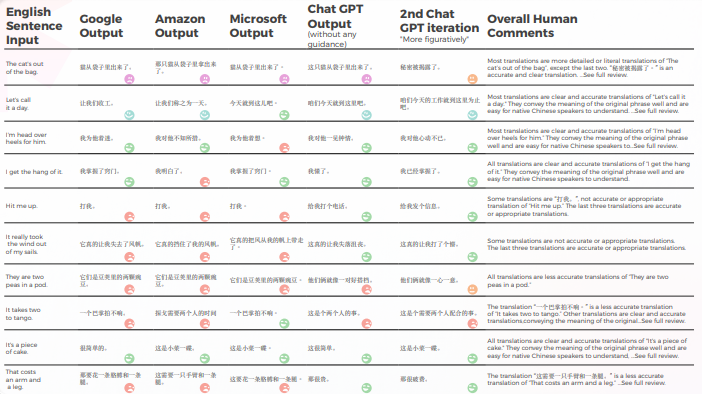
- Google 和 Amazon 的结果极其相似,仅有轻微偏差,反映了彼此的错误和比喻选择。 例如,翻译“打我”。“不是‘Hit me up’的准确或恰当的翻译。” 短语“Hit me up”意思是联系或与某人取得联系,通常是通过电话或短信。 中文短语“打我”的意思是“打我”,它并没有传达原短语的含义。
- Microsoft 在习语的语言适应方面做出了更大胆的选择。
- GPT 更难评估 Microsoft 的隐喻选择,因为它们偏离得更多。
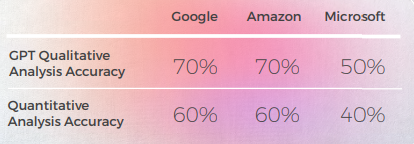
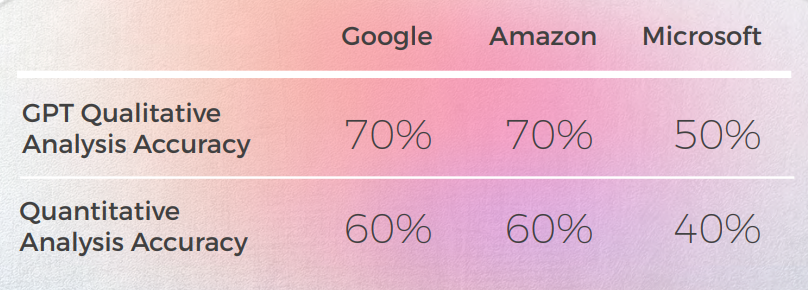
- GPT-3 在定性分析中更容易产生令人信服的文本分析(尽管准确率只有 70%)。
- 尽管 Intelligible GPT 的分析在 30% 的情况下未能识别。 这与字面上和可理解但偏离日常话语的隐喻选择相吻合。
- GPT-3 更难将定性分析转化为分数。 尽管广义上分数的准确率为 60%,但很难区分类似的分数,例如 3 分和 4 分。
- 从 1 到 5 的极端分数差异更容易理解,并且与总体评论更兼容,表明:
- 也许 GPT-3 没有充分校准评分标准
- 也许二进制评分可能比梯度评分更相关
- • 尽管 Microsoft 在定量上的表现与 Google 和 Amazon 相似,但当深入到语言的细节时,Microsoft 做出了更大胆的选择,并从定性角度提供了更好的结果,但在准确性和文化适应方面仍然远远落后于 GPT-3。 例如,翻译“我掌握了窍门”。“是‘我掌握窍门了’的清晰准确的翻译。” 它很好地传达了原文的含义,并且易于以中文为母语的人理解。 与其他可能的翻译相比,它也是一种更具形象和惯用的方式来表达理解或掌握某事的想法。
实际应用和局限性
在此分析中,GPT-3 提供了比以前的机器翻译模型更出色的上下文化和适应性。
虽然没有一个引擎足够可靠来取代人类(至少在本研究的背景下),但 GPT-3 显示出在翻译和评估语言过程中帮助人类翻译和审校人员的明确能力。
法语: MT Engines Failed on 60% of Idioms—GPT Stood Out
以下分析由我们的英语/法语译员Laurène Bérard撰写。

总的来说,所有引擎都在与语言的隐喻性质作斗争,经常犯下过度的字面意义错误。
从定性角度看输出
下表展示了我们的译员团队对10个英语习语句子翻译成法语的综合分析。

就翻译质量而言,GPT在语境化方面做得很出色。 在没有任何指导的情况下,GPT 对于 “The CAT’s out of the bag” 完全错误,但在有更多指导的情况下是正确的,并且它对 “It takes two to tango” 的 3 个翻译在语法上不完整,因此很难理解。
内容总体上适应良好、易于理解,并传达了适当的意义。 这三个机器翻译引擎的 “I want to cry” 率很高,而即使没有上下文,翻译人员也会猜到这并不是字面意思(例如 “让我们收工吧”,这很明显,但完全被 Google 引擎误解了。
下表包含原始数据分析。
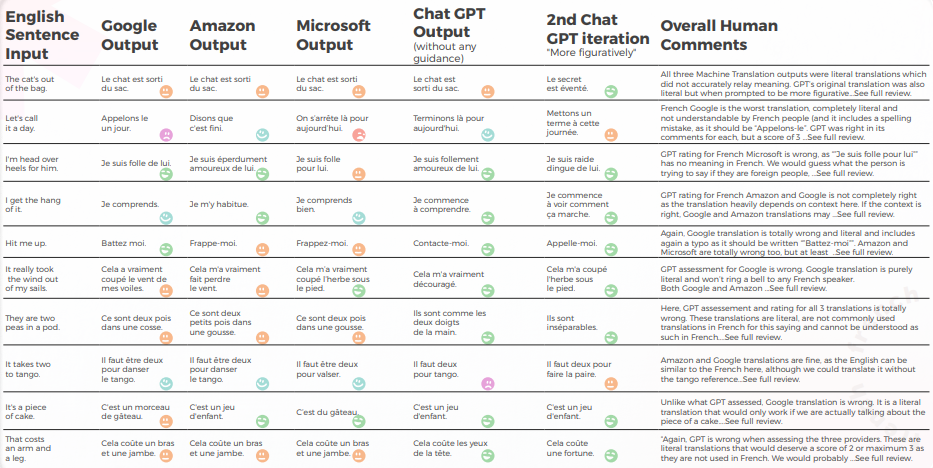
GPTs 评估
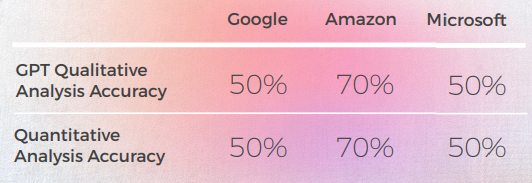
分析和关键查找
- 尽管在10次中有8次翻译正确,GPT对这3个引擎的分析常常是错误的,因为几乎50%的情况下,它们声称翻译没问题,但实际上并非如此。
- 尽管Intelligible GPT的分析在30%到50%的情况下未能识别出问题,但这与字面上的选择相吻合,如果不涉及惯用表达,这些选择本来是正确的。
- GPT 未能发现 Google 的两个拼写问题(“Appelons le”和“Battez moi”)。
- GPT 定性和定量分析在全球范围内彼此一致。
- GPT 在评估 Microsoft 和 Google 的翻译时遇到了更大的困难。
- Microsoft 在习语的语言适应方面做出了更好的选择。
- 谷歌和亚马逊的结果非常相似,只是略有不同。 微软从两者中脱颖而出。在一个案例(探戈表达)中,GPT 将 Microsoft 的优秀翻译评估为错误(得分为 2),尽管它是可以理解的,并且与 GPT 评价为正面(得分为 5)的 Google 和 Amazon 翻译一样好,但这可能是因为 Microsoft 的翻译不如其他两个引擎那么字面化,因为它选择提到华尔兹而不是探戈。
- Microsoft 做出了更大胆的选择,从定性角度提供了更好的结果,但在准确性和文化适应方面仍然远远落后于 GPT。
实际应用和局限性
在此分析中,GPT 提供了比 Amazon、Google 和 Microsoft 机器翻译引擎更好的上下文化和适应能力。 尽管由于高计算成本和在非隐喻性话语中边际收益递减的原因,用更大的模型(如GPT-3)替换传统机器翻译模型并不方便,但在提供建议、识别潜在错误以及改进机会方面,GPT-3可以是一个强大的人类盟友。
尽管机器翻译引擎“几乎”已经达到了目标,但正如 GPT 在这里所证明的那样,这个“几乎”变得越来越难以解决。
虽然没有一个引擎足够可靠来取代人类(至少在本研究的背景下),但 GPT 显示出在翻译和评估语言过程中帮助人类翻译和审校人员的明确能力。
GPT在德语习语中表现优于所有MT引擎30%
以下分析由我们的英语/德语译员Olga Schneider撰写。

总体而言,GPT 产生了最准确的翻译。 它总是准确地分析英语句子,通常可以判断机器翻译是直译还是惯用语,但在 50% 的情况下无法检测到误译。
从定性角度看输出
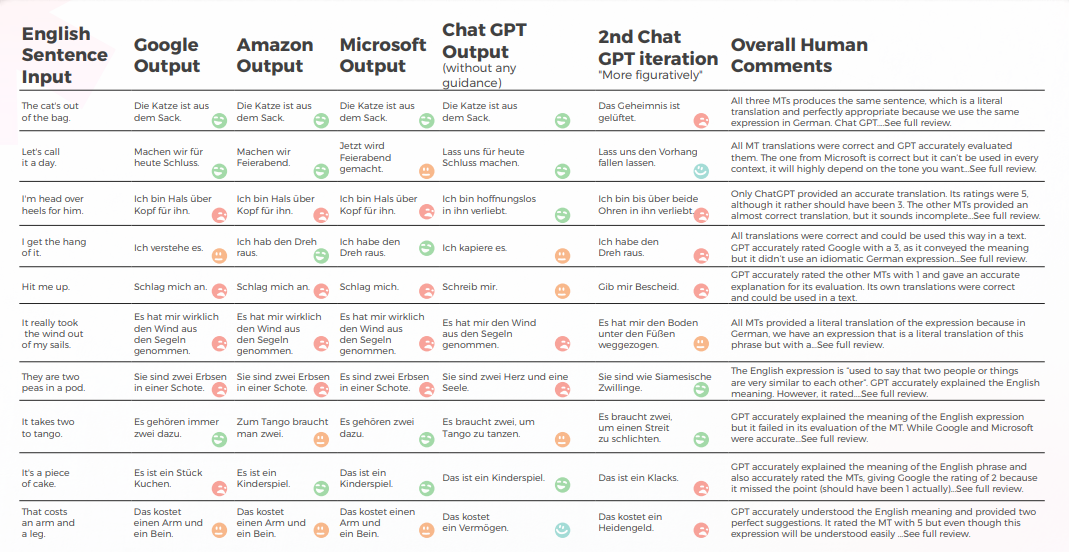
下表展示了由我们的译员团队进行的10个英语习语句子翻译成德语的综合分析。

GPT 在第一次尝试时 10 次中有 8 次产生良好结果,在第二次尝试时 10 次中有 7 次产生良好结果。 例如,只有 GPT 能够为 “I'm head over heels for him” 和 “Hit me up” 提供准确的惯用语翻译。
最后,最具象征性的输出产生了4个好的句子,其他的要么是all 正确,要么是“我想哭”。 总体而言,Amazon 和 Microsoft 的翻译效果略好于 Google。
下表包含原始数据分析。
GPTs 评估
分析和关键查找
- GPT 对德语习语有相当好的了解,即使是那些与英语句子不太匹配的习语也是类似类别的习语。 例如: “Let’s pull the plug”和“Let’s drop the curtain”表示“Let’s call it a day”。 它理解这些与“ending”相关的短语的一般含义,可以成为有用的灵感来源。
- 在创意表达方面,GPT 似乎从英语短语中汲取灵感,建议将“I am in love with him from head to toe”的字面德语翻译作为“I'm head over heels for him”的创造性替代方案。
- GPT 的翻译评级时好时坏,被证明是不可靠的。 在一个案例中,它将 Google 翻译评为 2 分,目前尚不清楚为什么它不是应该的 1 分。
- 德语和英语有许多惯用语,这使得翻译更容易。 但是德语中外来的表达式(例如 “他们就像一个豆荚里的两颗豌豆” 或 “这很简单”) 最终被直译。 在豌豆的情况下,与翻译引擎不同,GPT 明白它需要提供关于“twos”的表达。 然而,它提供的表达方式虽然准确且常用,但并没有传达正确的含义。
实际应用和局限性
GPT 提供了比 Google、Amazon 和 Microsoft 更好的翻译。 虽然它不是 100% 可靠的,但它可以为机器翻译编辑提供比其他三个引擎更好的起点。 虽然惯用语很重要,但在将英语文本翻译成德语文本的机器翻译中经常遇到另一个问题:繁琐的句子结构与原始文本过于接近。 了解 GPT 如何解决这个问题很重要。
在评估方面,GPT 不是一个好的工具,因为它对德语翻译的评估只有 50% 的准确率。
还有三件事会很有趣:
- GPT 能否与 DeepL 竞争德语?虽然 GPT 可能提供良好的翻译,但 DeepL 的德语翻译效果很好,并且还提供一系列简化翻译过程的功能(术语表使用正确的复数和大小写进行正确翻译、一键编辑、输入一两个单词后自动完成句子以加快改写速度)。 GPT 的翻译需要显著优于 DeepL 的翻译,以弥补功能的不足。
- GPT 的准确性是否可以通过更多上下文来提高,例如包含该短语的段落?
- 如果 Google 能够识别 AI 生成的文本,它将如何处理 GPT 翻译,而只需最少甚至无需编辑?它能否检测“GPT风格”并在搜索结果中惩罚该文本?
总之,在目前的状态下,GPT 可以成为我们有限的人脑的灵感来源。 它可以提供不错的翻译。 不仅如此,它可以帮助我们改写过度使用的表达,查找隐喻,并跳出固有思维模式。
意大利语: MT Engines在70%的情况下返回了字面翻译
以下分析由我们的英语/意大利语译员Elvira Bianco撰写。

总的来说,所有引擎都在与语言的隐喻性质作斗争,经常犯下过度的字面意义错误。
从定性角度看输出
下表展示了由我们的译员团队进行的10个英语习语句子翻译成意大利语的综合分析。
机器翻译给出的直译与正确含义相去甚远。 GPT 传达了 70% 的正确含义和表达,其余 30% 使用了可接受的表达方式,这些表达方式没有被广泛使用或被认为不像自然的母语表达。
下表包含原始数据分析。
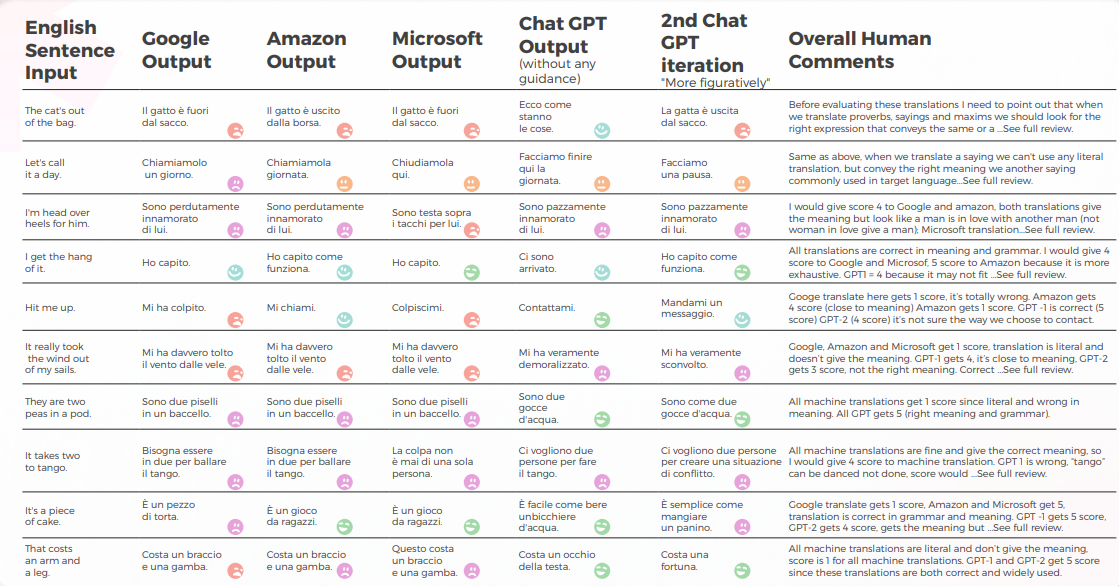
GPTs 评估

分析和关键查找
- Google Translate 只有一个正确翻译,并在两句话中接近意思。
- Amazon 给出了 50% 的正确含义,即使没有使用意大利语中传达英语说法的最常见方式。
- Microsoft 给出了 3 个正确答案,越来越接近意大利的类似说法。
- 虽然 1st Chat GPT 通常会批准机器翻译,但 2nd 和 3rd Chat GPT 通常会给出正确的含义并添加有价值的翻译建议。
实际应用和限制
根据 https://it.wiktionary.org/wiki/espressione_idiomatica 的定义,一种语言的典型惯用表达通常无法直接翻译成其他语言,除非借助于翻译目标语言中具有相似意义的惯用表达。 显然,当前最常用的翻译机器(Google、Amazon、Microsoft)所产生的机械翻译是不可靠的,不过GPT-3证明在70%的情况下能够给出正确的意义,并在内容适应方面提供良好的建议。
在不久的将来,机器也有可能记住习惯用语,但正确现在我们需要人类来翻译,以便在不同语言之间传达相同的含义。
语言充满了细微差别、双关语、典故、成语、隐喻,只有人类才能感知。
韩语在所有测试的引擎中准确率最低
以下分析由我们的英语/韩语译员金善敏撰写。

从定性角度看输出
下表展示了由我们的译员团队进行的10个英语习语句子翻译成韩语的综合分析。大多数引擎从字面上翻译惯用语,而 GPT 则试图尽可能地翻译为描述性,而不使用隐喻(例如,小菜一碟 = 简单,而在韩国,我们有一个类似的惯用语,传达与 Microsoft 相同的含义)。
GPT 的三种翻译并不一致。 有些在迭代中变得更糟。
下表包含原始数据分析。
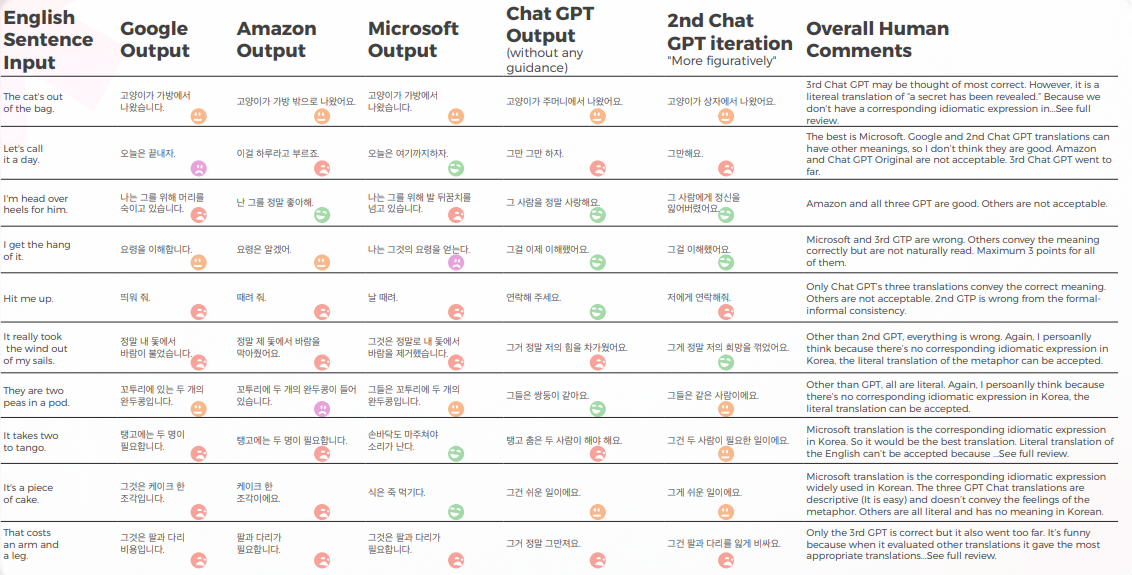
GPT 知道翻译出错时的问题。 但在判断最好的一个时,它不被认为是正确的。
GPT 本身在正式 – 非正式处理等方面存在问题,它可以评估这个问题。
GPTs评估

分析和关键查找
由于本研究中的英语原文是惯用表达,这有点棘手,因为你必须在隐喻或直接描述之间做出选择。 但是对于一些习语表达,韩语中有类似的习语表达传达相同的意思,大多数引擎未能查找这些表达,只有少数例外(请查看工作表并查找我评分为5的那些)。对于其他情况,我个人的想法是,如果隐喻本身可以传达意义,可以考虑对其进行直译,可能更好地使用描述性词语。 当然,如果这个比喻在韩国没有文化背景,就不应该按字面意思翻译。 但这是一个微妙的问题,可能取决于译者的偏好或人类情感。 我认为还没有任何引擎具有那种水平的类似人类的思维。
实际应用和限制
我确实认为大多数引擎都可以用于预翻译目的。 但考虑到质量,它应该主要仅用于提高效率的目的(即,不是从头开始打字)。 对于更具描述性的文本,例如手册,我认为 MTPE 比这些惯用表达要先进得多。 因此,仍有改进的空间。
GPT 在巴西葡萄牙语习语中达到 90% 的成功率
以下分析由我们的英语/葡萄牙语译员 Gabriel Fairman 撰写。

总的来说,所有引擎都在与语言的隐喻性质作斗争,经常犯下过度的字面意义错误。
从定性角度看输出
下表展示了我们的译员团队对10个英语习语句子翻译成葡萄牙语的综合分析。大多数引擎从字面上翻译惯用语,而 GPT 则试图尽可能地翻译为描述性,而不使用隐喻(例如,小菜一碟 = 简单,而在韩国,我们有一个类似的惯用语,传达与 Microsoft 相同的含义)。
GPT 的三种翻译并不一致。 有些在迭代中变得更糟。
下表包含原始数据分析。
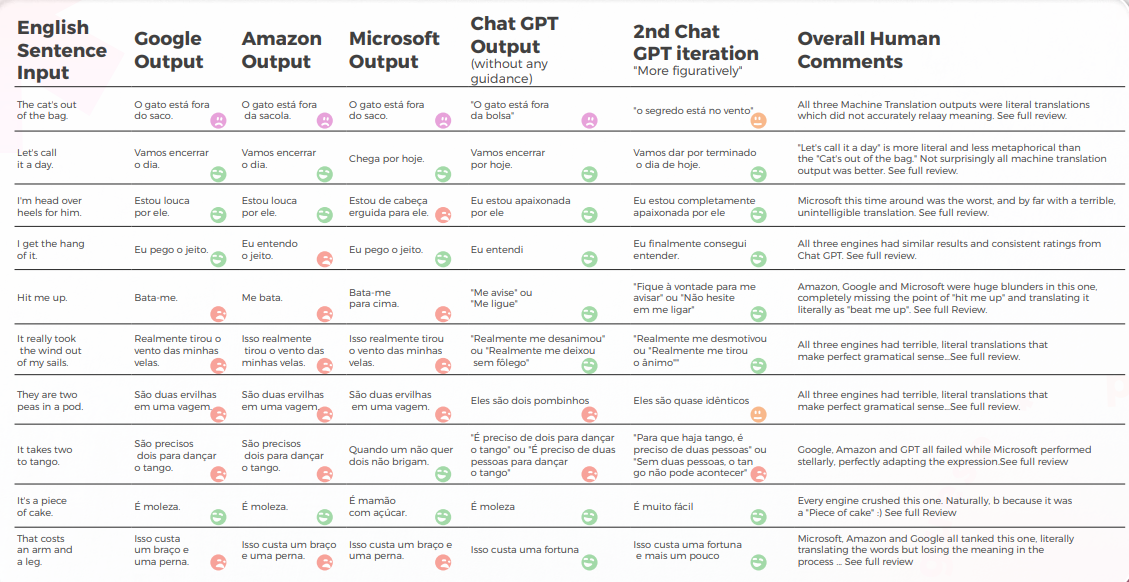
就翻译质量而言,GPT在语境化方面做得很出色。 在10个句子中,有9个句子的内容适应良好、易于理解,并传达了适当的意义。 与三个机器翻译引擎相反,GPT 没有令人尴尬的“我想哭”错误。
最初的假设是 GPT 的第一次迭代和第二次迭代之间的质量会有很大差异,但两者的翻译质量相似。
GPTs 评估的评估
分析和关键查找
- Microsoft 在习语的语言适应方面做出了更大胆的选择。
- GPT 更难评估 Microsoft 的隐喻选择,因为它们偏离得更多。
- 谷歌和亚马逊的结果非常相似,只是彼此略有不同,反映了彼此的错误和隐喻选择。 微软显然从两者中脱颖而出。
- GPT-3 在定性分析中更容易产生令人信服的文本分析(尽管准确率只有 70%)。
- 尽管 Intelligible GPT 的分析在 30% 的情况下未能识别。 这与字面上和可理解但偏离日常话语的隐喻选择相吻合。
- GPT-3 更难将定性分析转化为分数。
- 尽管广义上分数的准确率为 60%,但很难区分类似的分数,例如 3 分和 4 分。
- 从 1 到 5 的极端分数差异更容易理解,并且与总体评论更兼容,表明:
- 也许评分标准没有与 GPT-3 充分校准
- 也许二进制评分可能比梯度评分更相关。在一个异常案例中,Cchat GPT-3 以截然不同的方式评估了两个相似的翻译,一个给了 1,另一个给了 5,而它们都应该是 1。尽管 Microsoft 在定量上的表现与 Google 和 Amazon 相似,但当深入到语言的细节时,Microsoft 做出了更大胆的选择,并从定性角度提供了更好的结果,但在准确性和文化适应方面仍然远远落后于 GPT-3。
实际应用和局限性
在此分析中,GPT-3 提供了比以前的巴西葡萄牙语机器翻译模型更优越的
语境化和适应能力。 虽然由于高计算成本和在非隐喻性话语中边际收益递减,不方便用更大的模型(如GPT-3)替换传统的机器翻译模型,但GPT-3可以成为一个强大的人类盟友,在提供建议、识别潜在错误以及改进机会方面发挥作用。
语言的边缘案例非常惊人,因为它们如此清楚地展示了在涉及语言模型时,如何在如此少的内容中留下如此多的东西。 即使它们“几乎”在那里,这个“几乎”也变得越来越难以解决,如果不是更难的话,从计算的角度来看,肯定更昂贵。
虽然没有一个引擎足够可靠来取代人类(至少在本研究的背景下),但 GPT-3 显示出在翻译和评估语言过程中帮助人类翻译和审校人员的明确能力。
西班牙语MT得分低于30%—GPT是明显的赢家
以下分析由我们的英语/西班牙语译员Nicolas Davila撰写。

总的来说,所有引擎都在与语言的隐喻性质作斗争,经常犯下过度的字面意义错误。
从定性角度看输出
下表展示了我们的译员团队对10个英语习语句子翻译成西班牙语的综合分析。

就翻译质量而言,GPT 做了一个可以接受的工作,并且在上下文处理方面比其他的更好。 在10个句子中有7个句子的内容是可理解的、结构良好的,并传达了适当的意义,尴尬度和“我想哭”的比率很低。
虽然最初的假设是 GPT 的第一次迭代和后续迭代在质量上会有很大差异,但它们的翻译质量都相似,第 2 次和第 3 次迭代有时会添加不必要的内容,从而略微增加了尴尬的程度。
下表包含原始数据分析。
GPTs 评估

分析和关键查找
- 机器翻译过于字面化,Amazon 和 Google 在总体上非常相似,而 Microsoft 是最差的。
- 谷歌和亚马逊的结果非常相似,只是彼此略有不同,反映了彼此的错误和隐喻选择。 微软表现不佳,有时会产生格式不正确的句子,并缺少语法结构的某些部分。
- GPT-3 在定性分析中更容易产生连贯的文本分析,尽管准确率只有 50%。
- 通常,GPT-3 的定性分析过于笼统,更局限于句子的主要和字面含义,而没有考虑结构的细微细节和含义的变化。 GPT 似乎无法捕捉到这种差异并将其转化为定量分数。
- 此外,GPT 经常为语法结构不佳的句子分配相同的定性分析和高定量分数,这似乎是 GPT 模型的局限性。
- GPT-3 更难将定性分析转化为分数。
- 谷歌和亚马逊的准确率仅为 50%,微软的准确率仅为 30%。 GPT 似乎只是在衡量句子是否传达了意思,但在结构或良好形成方面没有差异。
- 从 1 到 5 的分数差异更容易理解,并且与总体评论更兼容,这表明: 也许评分标准没有针对 GPT-3 进行充分校准,也许二进制评分可能比梯度评分更相关。 也许评分标准或 GPT 模型没有考虑语法问题,而只是传达意义。
实际应用和局限性
在此分析中,GPT-3 提供了比以前的拉丁美洲西班牙语机器翻译模型更好的上下文化和适应性。
GPT-3 可以是一个强大的工具,在提供有用的建议和改进机会时帮助人类改进翻译。 但是,据我所知,它仍然有一定的局限性。尽管 GPT-3 等较大的模型可能会有所帮助,但由于计算成本较高,用它们替换传统的机器翻译模型并不方便,因为当涉及非隐喻文本时,它可能会减少边际收益。
虽然 GPT-3 在翻译和评估语言的过程中显示出帮助人工翻译和审校人员的明确能力,但在评估其在非隐喻文本中的使用时,应考虑成本。
结论
虽然 ChatGPT 的性能可能因提示和特定语言而异,但我们的研究表明,ChatGPT 有可能产生比传统 MT 引擎更高质量的翻译,尤其是在处理惯用语和细微的语言使用时。
但是,重要的是要注意,ChatGPT 远非不犯错误,仍有很大的改进空间,尤其是在涉及更复杂的提示或语言领域时。
作为翻译,ChatGPT 比所有经过测试的机器翻译引擎都更成功。 虽然语言显示出不同的结果,但韩语显然是异常值,MT 质量和 GPT 质量明显低于其他语言。
在除韩语以外的所有语言中,ChatGPT 的成功率至少为 70%,最高为 90%,表现优于传统 MT。 即使在韩语中,虽然分数较低,但仍然优于 MT 引擎的输出。
与机器翻译相反,使用大型语言模型,相同内容的多次迭代可以提高输出质量。 在考虑集成时,这是关键,因为传统的MT中,您的输出总是与输入相同(除非引擎获得更多数据或训练),而使用LLM可以通过API探索多种交互,以优化动态质量。
与传统 MT 引擎相比,ChatGPT 的一个优势是它能够随着时间的推移而学习和改进,即使没有额外的训练数据。 这是由于 LLM 的性质,LLM 旨在根据新输入不断优化其语言模型。 因此,ChatGPT 可能提供更具适应性和动态的翻译能力,这在语言或内容不断演变或变化的情况下可能特别有用。
ChatGPT 的另一个优势是其低畏缩率,这与传统的 MT 引擎相比是一个显著的改进,因为传统引擎经常产生尴尬或不适当的翻译。 这可能使ChatGPT对非专业用户更易接受和用户友好,这些用户可能没有与专业译员相同的语言或文化知识水平。
然而,需要注意的是,ChatGPT不能替代人工译员,在许多情况下仍需要人工译员的专业知识和判断力。 但 ChatGPT 明显较低的畏缩率为更广泛地采用非人工驱动的翻译打开了大门。
作为评估者,ChatGPT 的表现更加复杂,准确率从 30% 到 70% 不等。 虽然这表明 ChatGPT 在评估其他翻译引擎方面可能不如在建议翻译方面有效,但这可能是由于评估提示的复杂性和质量,这可能需要比 ChatGPT 目前拥有的更专业或上下文的知识。 需要进一步的研究来探索 ChatGPT 作为评估者的潜力,以及它的局限性和挑战。总体而言,我们的研究表明 ChatGPT 具有很有前途的翻译功能,值得进一步探索。 虽然它可能无法完全取代或绕过人工翻译,但它可能会作为辅助或翻译前工具提供显著的好处,尤其是在时间、资源或专业知识有限的情况下。
与任何新兴技术一样,仍然存在许多改进的挑战和机遇,需要进一步的研究和实验才能充分释放其潜力。
方法论
为了探讨像GPT-3这样的语言模型在处理习语翻译时与传统机器翻译引擎的表现差异,我们进行了一个实验,重点研究涉及隐喻和习语表达的语言边缘案例。
习语选择
我们选择了10个常用的英语习语,比如“Let’s call it a day,” “Hit me up,” 和 “The CAT’s out of the bag.” 这些表达方式以对翻译系统的挑战性而闻名,因为它们需要文化和上下文的适应,而不是字面上的对等。
测试的翻译引擎和模型
每个习语都使用以下方法进行翻译:
- Google Translate
- Amazon Translate
- Microsoft Translator
- GPT-3 (ChatGPT) – 使用两种方法:
- 没有任何指导的直接翻译
- 第二个版本被提示更具象征性和成语化

评估过程
译员对七种目标语言的翻译结果进行了审查: 巴西葡萄牙语、西班牙语、法语、德语、意大利语、中文和韩语。 对于每个句子,审稿人评估:
- 原始成语的含义是否被保留
- 目标语言中表达的自然性
- 语法、句法和语义准确性
每个翻译都按 1 到 5 的等级进行评分:
- 5: 正确的含义和自然发音的语言
- 1: 不正确、令人困惑或不自然的翻译(“我想哭”级别)
此外,我们要求 ChatGPT 通过提供定性文本反馈和数字分数来评估其他引擎的翻译。 这使我们能够评估它作为评估器的能力,而不仅仅是作为翻译生成器。
研究局限性
重要的是要注意,这是一项探索性研究:
- 样本限制为 10 个成语,每种语言有一名人工审稿人。
- 所有评估都带有一定程度的主观性和个人偏好。
- GPT-3 的性能反映了模型的特定版本,并且可能会随着更新而发展。
尽管有这些限制,查找结果提供了对当前模型能力和局限性的宝贵见解,特别是在语言上微妙和文化上依赖的场景中。
免责声明
(真正的研究免责声明,不容小觑)
虽然我们旨在探索ChatGPT语言能力的潜力,但需要注意的是,本研究仅评估了翻译的一个方面,即处理语言习语高度隐喻边缘案例的能力。 翻译的其他方面,例如文化和上下文理解,可能需要不同的评估方法和标准。
本研究的样本量仅限于 10 个成语和每种语言 1 名审稿人,这可能不能代表英语中所有惯用语表达的范围,也不代表专业翻译人员的观点和专业知识的范围。 因此,应谨慎解释本研究的结果,不能推广到其他背景或领域。
此外,每位审稿人对每种语言的意见和评价是主观的,可能会受到个人偏见、经验或偏好的影响。 与任何主观评估一样,结果存在一定程度的可变性和不确定性。 为了提高我们查找结果的可靠性和有效性,未来的研究可以涉及多个审阅者、盲评或评估者间一致性测量。
还值得注意的是,ChatGPT 的语言能力不是静态的,随着模型的进一步训练和微调,它可能会随着时间的推移而变化。 因此,本研究的结果应被视为模型在特定时间点的性能快照,可能无法反映其当前或未来的能力。
最后,本研究无意对 ChatGPT 的翻译有用性或局限性做出任何明确或绝对的声明。 相反,它旨在作为自然语言处理和机器翻译领域未来研究和开发的初步调查和起点。 与任何新兴技术一样,仍然存在许多挑战和改进机会,需要进一步的实验和合作以充分探索其潜力。
Unlock the power of glocalization with our Translation Management System.
Unlock the power of
with our Translation Management System.








