Nous avons testé Chat GPT pour la traduction - voici les données


Tout le monde parle de la façon dont l’IA transforme la traduction, mais peut-elle vraiment gérer les nuances du langage humain ?
Des recherches récentes par Bureau Works ont mis cela à l'épreuve, en comparant GPT-3 avec les principaux moteurs de traduction automatique de Google, Amazon et Microsoft. L'étude s'est concentrée sur l'un des défis les plus difficiles de la localisation : les expressions idiomatiques. Pourquoi ? Parce que les traductions littérales ne suffisent pas quand il s'agit d'expressions comme « Le TAO est sorti du sac » ou « On va en rester là pour aujourd'hui. »
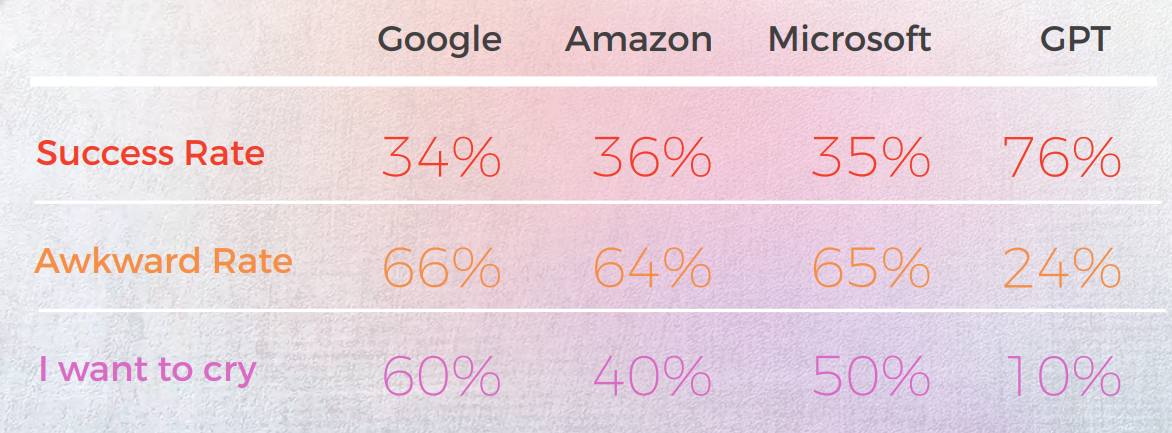
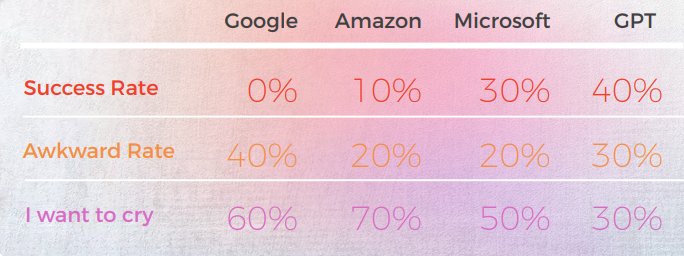
Les résultats ont été surprenants. GPT-3 a fourni des traductions précises et naturelles jusqu'à 90 % du temps, tandis que les moteurs traditionnels oscillaient entre 20 % et 50 % — et produisaient souvent des résultats gênants évalués « J'ai envie de pleurer » par des linguistes natifs.
Dans un monde où la nuance linguistique peut faire ou défaire votre message, ces découvertes soulignent à la fois la promesse et les limites actuelles de l'IA dans la traduction professionnelle.
Voici un résumé de nos Clé Findings:
- GPT-3 a constamment surpassé les moteurs de traduction automatique traditionnels (Google, Amazon, Microsoft) dans le traitement des expressions idiomatiques, atteignant une précision allant jusqu’à 90 % dans des langues comme le portugais et le chinois.
- Les moteurs traditionnels avaient du mal avec la métaphore et le langage figuratif, fournissant souvent des traductions littérales grammaticalement correctes mais sémantiquement erronées - certaines obtenant même des notes « Je veux pleurer » de la part des critiques natifs.
- Microsoft a pris plus de risques, en proposant des traductions plus audacieuses qui s’écartaient parfois de l’original mais semblaient plus naturelles - bien que GPT ait eu plus de mal à évaluer ces choix créatifs.
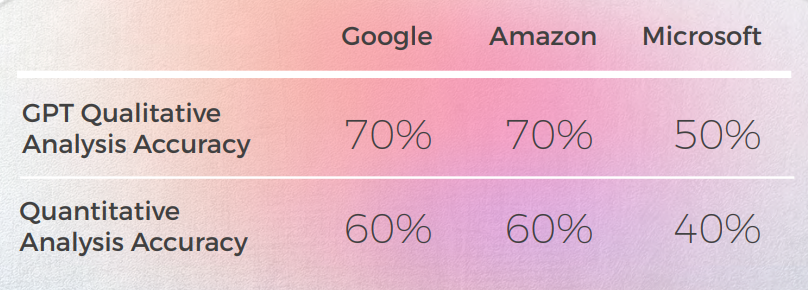
- L’analyse qualitative de GPT était solide, mais elle a eu du mal à attribuer des scores numériques cohérents, en particulier lorsqu’il s’agissait de différencier les notes de milieu de gamme comme 3 vs. 4.
- Dans presque toutes les langues, la deuxième itération de GPT - lorsqu’on lui a demandé une version plus figurative - a amélioré la clarté, le ton et l’adéquation culturelle.
- Le coréen était la langue la plus difficile tant pour les TA traditionnelles que pour GPT-3, affichant des performances nettement inférieures dans tous les domaines.
- GPT-3 s'est avéré précieux non seulement en tant que Traducteur mais aussi comme outil d'évaluation et de révision, aidant à signaler les formulations maladroites ou inexactes et à proposer des alternatives.
GPT a atteint une précision de 90 % dans les idiomes chinois—les MTs ont eu du mal
L'analyse suivante a été rédigée par notre linguiste anglais/chinois James Hou.

Dans l’ensemble, tous les moteurs ont eu du mal avec la nature métaphorique du langage, se trompant souvent dans une littéralité excessive. Par exemple, la traduction « Appelons ça une journée. »« est une traduction plus littérale et quelque peu maladroite de « Arrêtons-nous là pour aujourd'hui ». Il transmet le sens de la phrase originale, mais la formulation est quelque peu maladroite et peut ne pas être aussi facile à comprendre pour les locuteurs natifs chinois.
Bien qu’elle transmette avec précision le sens de la phrase originale, la formulation est quelque peu maladroite et peut être moins claire pour les locuteurs natifs.
Résultats d'une perspective qualitative
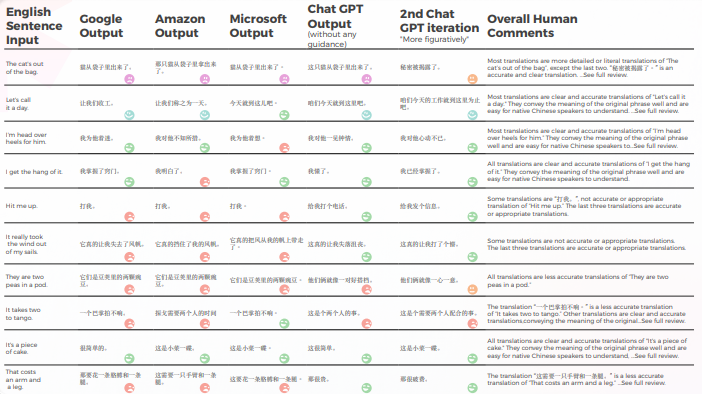
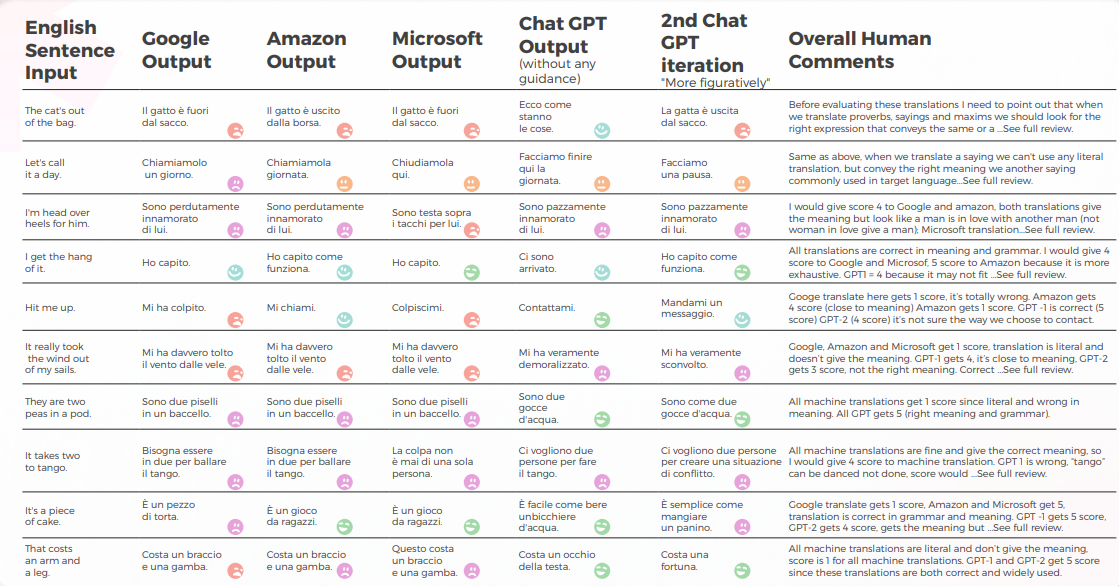
Le tableau ci-dessous présente une analyse synthétique de 10 phrases idiomatiques anglaises traduites en chinois, réalisée par notre équipe de linguistes.
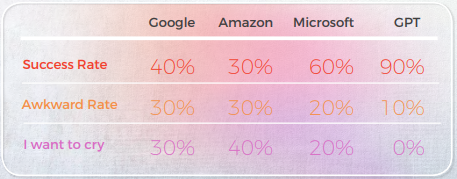
En ce qui concerne la qualité de la traduction, GPT a fait un excellent travail avec la contextualisation. Par exemple, "秘密被揭露了".” est une traduction précise et claire pour “Le TAO est sorti du sac”. Dans 9 phrases sur 10, le Contenu était bien adapté, intelligible et transmettait le sens approprié. Contrairement aux trois moteurs de traduction automatique, GPT n'a pas fait d'erreurs embarrassantes du type « Je veux pleurer ».
Le tableau ci-dessous contient l’analyse des données brutes.
Évaluation des GPTs Évaluation
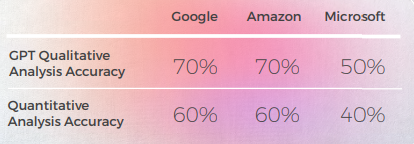
Analyse et Clé Conclusions
- Google et Amazon ont eu des résultats extrêmement similaires, ne s'écartant que légèrement l'un de l'autre, reflétant les erreurs et les choix métaphoriques de chacun. Par exemple, la traduction « 打我 ».« n’est pas une traduction exacte ou appropriée de « Hit me up ». L'expression « Hit me up » signifie contacter ou entrer en contact avec quelqu'un, généralement par téléphone ou par message texte. L’expression chinoise « 打我 » signifie « frappe-moi », et elle ne transmet pas le sens de la phrase originale.
- Microsoft a fait des choix plus audacieux en ce qui concerne l'adaptation linguiste des expressions idiomatiques.
- GPT a eu plus de mal à évaluer les choix métaphoriques de Microsoft, car ils s'écartaient davantage.
- GPT-3 a eu plus de facilité avec l’analyse qualitative, produisant une analyse textuelle convaincante (même si elle n’avait qu’une précision de 70 %).
- Bien qu’intelligible, l’analyse de GPT n’a pas permis d’identifier dans 30 % des cas. Cela a coïncidé avec des choix métaphoriques qui étaient littéraux et compréhensibles, mais qui s’écartaient du discours quotidien.
- GPT-3 a eu plus de mal à traduire l’analyse qualitative en un score. Bien que, d'une manière générale, les scores soient précis à 60 %, il était difficile de différencier des scores similaires tels qu'un 3 et un 4.
- La divergence extrême du score de 1 à 5 était plus facile à comprendre et plus compatible avec les commentaires globaux suggérant que :
- Peut-être que les critères de notation n’ont pas été suffisamment calibrés avec GPT-3
- Peut-être que la notation binaire pourrait être plus pertinente que la notation de gradient
- • Même si, sur le plan quantitatif, Microsoft a obtenu des résultats similaires à ceux de Google et d'Amazon, lorsque vous entrez dans le vif du sujet, Microsoft a fait des choix plus audacieux et a fourni de meilleurs résultats d'un point de vue qualitatif, mais était encore loin derrière GPT-3 en matière de précision et d'adaptation culturelle. Par exemple, la traduction « 我掌握了窍门。« Je m'y fais » est une traduction claire et précise de « I get the hang of it. » Il transmet bien le sens de la phrase originale et est facile à comprendre pour les locuteurs natifs chinois. C'est aussi une manière plus figurative et idiomatique d'exprimer l'idée de comprendre ou de maîtriser quelque chose par rapport à d'autres traductions possibles.
Applications pratiques et limitations
Dans cette analyse, GPT-3 a offert une contextualisation et une adaptation supérieures par rapport aux modèles de traduction automatique précédents.
Bien qu'aucun des moteurs ne soit suffisamment fiable pour remplacer les humains (du moins dans le contexte de cette étude), GPT-3 montre une capacité claire à aider les traducteurs humains et les réviseurs dans le processus de traduction et d'évaluation de la langue.
Français : Les moteurs de traduction automatique ont échoué sur 60 % des idiomes—GPT s'est démarqué
L'analyse suivante a été rédigée par notre linguiste anglais/français Laurène Bérard.

Dans l’ensemble, tous les moteurs ont eu du mal avec la nature métaphorique du langage, se trompant souvent dans une littéralité excessive.
Résultats d'une perspective qualitative
Le tableau ci-dessous présente une analyse synthétique de 10 phrases idiomatiques anglaises traduites en français, réalisée par notre équipe de linguistes.

En ce qui concerne la qualité de la traduction, GPT a fait un excellent travail avec la contextualisation. Sans aucune orientation, GPT avait totalement tort pour « The TAO’s out of the bag » mais était bon avec plus d'orientation, et ses 3 traductions étaient grammaticalement incomplètes donc assez difficiles à comprendre pour « It takes two to tango ».
Le Contenu était généralement bien adapté, intelligible et transmettait le sens approprié. Les trois moteurs de traduction automatique avaient un taux élevé de « je veux pleurer », alors même sans contexte, un traducteur aurait deviné que ce n'était pas à prendre littéralement (par exemple. « Concluons pour aujourd'hui », ce qui est assez évident mais a été totalement incompris par le moteur Google).
Le tableau ci-dessous contient l’analyse des données brutes.
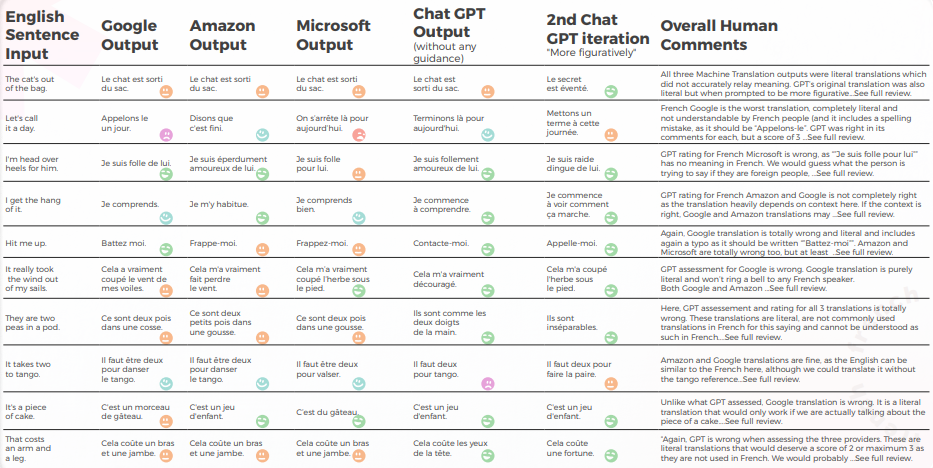
Évaluation des GPTs Évaluation
Analyse et Clé Conclusions
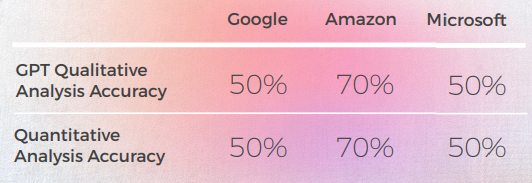
- Bien que la traduction soit correcte 8 fois sur 10, l'analyse de GPT des 3 moteurs était souvent erronée, car dans presque 50% des cas, elle indiquait que leur traduction était correcte alors qu'elle ne l'était pas.
- Bien que l’analyse d’intelligible GPT n’ait pas permis d’identifier de problèmes dans 30 à 50 % des cas, cela a coïncidé avec des choix littéraux qui auraient été corrects s’ils n’avaient pas porté sur des expressions idiomatiques.
- GPT n’a pas réussi à repérer les deux problèmes d’orthographe de Google (« Appelons le » et « Battez moi »).
- Les analyses qualitatives et quantitatives de GPT étaient globalement cohérentes les unes avec les autres.
- GPT a eu plus de mal à évaluer les traductions de Microsoft et de Google.
- Microsoft a fait de meilleurs choix en ce qui concerne l'adaptation linguiste des idiomes.
- Google et Amazon ont obtenu des résultats très similaires, ne s’écartant que légèrement l’un de l’autre. Microsoft s’est démarqué des deux.
- Dans un cas (l’expression tango), GPT a évalué une bonne traduction de Microsoft comme étant incorrecte (score de 2) alors qu’elle était compréhensible et tout aussi bonne que les traductions de Google et d’Amazon, que GPT a évaluées positivement (score de 5). Cela peut s’expliquer par le fait que Microsoft n’était pas aussi littéral que les deux autres moteurs, car il a choisi de mentionner la valse au lieu du tango.
- Microsoft a fait des choix plus audacieux et a fourni de meilleurs résultats d’un point de vue qualitatif, mais était encore loin derrière GPT en matière de précision et d’adaptation culturelle.
Applications pratiques et limitations
Dans cette analyse, GPT a fourni une bien meilleure contextualisation et adaptation que les moteurs de traduction automatique d'Amazon, Google et Microsoft. Bien qu'il ne soit pas pratique de remplacer les modèles traditionnels de traduction automatique par des modèles plus grands tels que GPT-3 en raison des coûts de calcul élevés et des rendements marginaux décroissants en ce qui concerne le discours non métaphorique, GPT-3 peut être un allié humain puissant lorsqu'il s'agit de fournir des suggestions et d'identifier des erreurs potentielles ainsi que des opportunités d'amélioration.
Même si les moteurs de traduction automatique sont « presque » là, ce « presque » devient progressivement plus difficile à aborder, comme le prouve GPT ici.
Bien qu'aucun des moteurs ne soit suffisamment fiable pour remplacer les humains (du moins dans le contexte de cette étude), GPT montre une capacité claire à aider les traducteurs humains et les réviseurs dans le processus de traduction et d'évaluation de la langue.
GPT a surpassé tous les moteurs de traduction automatique dans les idiomes allemands de 30 %
L'analyse suivante a été rédigée par notre linguiste anglais/allemand Olga Schneider.

Dans l’ensemble, GPT a produit la traduction la plus précise. Il analysait toujours la phrase anglaise avec précision et pouvait généralement dire si une traduction automatique était littérale ou idiomatique, mais il n'a pas réussi à détecter une mauvaise traduction 50 % du temps.
Résultats d'une perspective qualitative
Le tableau ci-dessous présente une analyse synthétique de 10 phrases idiomatiques anglaises traduites en allemand, réalisée par notre équipe de linguistes.

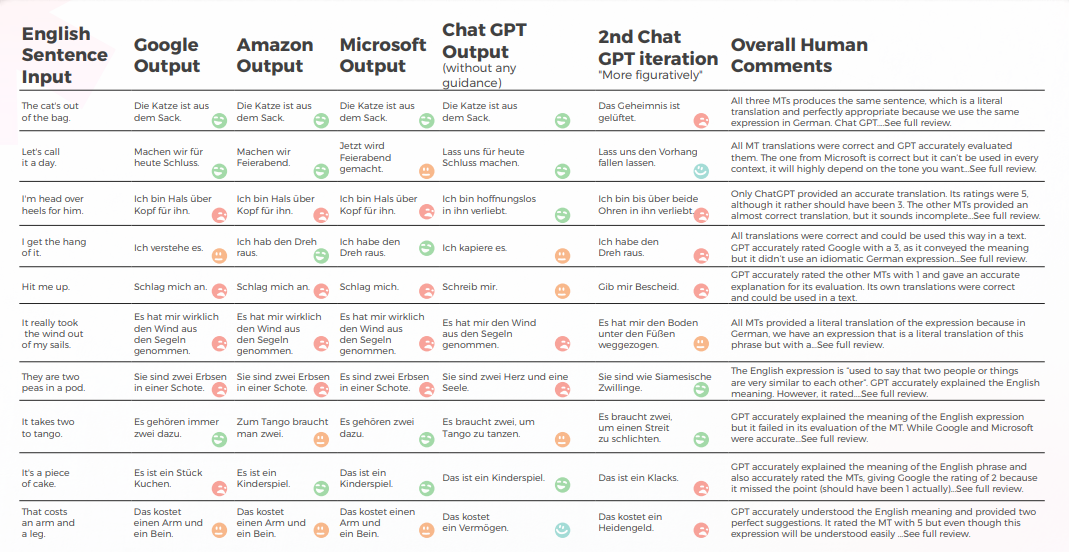
GPT produit de bons résultats 8 fois sur 10 au premier essai et 7 fois sur 10 au deuxième essai. Par exemple, seul GPT a été en mesure de fournir des traductions idiomatiques précises pour « Je suis éperdument amoureux de lui » et « Contacte-moi ».
La dernière sortie, la plus figurative, a produit 4 bonnes phrases, les autres étant soit bon soit « Je veux pleurer ». Dans l’ensemble, Amazon et Microsoft ont produit des traductions légèrement meilleures que Google.
Le tableau ci-dessous contient l’analyse des données brutes.
Évaluation des GPTs Évaluation
Analyse et Clé Conclusions
- GPT a une assez bonne connaissance des expressions idiomatiques allemandes, même celles qui ne correspondaient pas tout à fait à la phrase anglaise étaient des expressions idiomatiques d'une catégorie similaire. Par exemple: « Tirons la prise » et « Baissons le rideau » pour « Arrêtons-nous là ». Il comprend le sens général de ces expressions liées à la « fin » et pourrait être une source d’inspiration utile.
- Lorsqu'il s'agit d'expressions créatives, GPT semble s'inspirer des phrases anglaises, en suggérant la traduction allemande littérale de « Je suis amoureux de lui de la tête aux pieds » comme une alternative créative à « Je suis éperdument amoureux de lui ».
- Les notes de traduction de GPT ont été aléatoires et se sont avérées peu fiables. Dans un cas, il a attribué la note 2 à une traduction de Google, et il n’était pas clair pourquoi ce n’était pas le 1 qu’il aurait dû être.
- L’allemand et l’anglais partagent de nombreuses expressions idiomatiques, ce qui facilite la traduction. Mais des expressions étrangères à l’allemand (par ex. « Ils sont comme les deux doigts de la main » ou « C’est du gâteau ») finissent par être traduits littéralement. Dans le cas des pois, contrairement aux moteurs de traduction, GPT a compris qu’il devait fournir des expressions sur « deux ». Cependant, les expressions qu’il fournissait – bien que précises et couramment utilisées – ne transmettaient pas le sens correct.
Applications pratiques et limitations
GPT a fourni de meilleures traductions que Google, Amazon et Microsoft. Bien qu'elle ne soit pas fiable à 100 %, elle peut offrir un meilleur point de départ pour l'édition de traduction automatique que les trois autres moteurs. Bien que les expressions idiomatiques soient importantes, il y a un autre problème souvent rencontré dans la traduction automatique de texte anglais en allemand : une structure de phrase lourde qui est trop proche du texte original. Il serait important de voir comment GPT résout ce problème.
En matière d’évaluation, GPT n’est pas un bon outil, car son évaluation des traductions allemandes n’est précise qu’à 50 %.
Trois autres choses auraient été intéressantes à voir :
- GPT peut-il concurrencer DeepL pour l'allemand ? Bien que GPT puisse fournir de bonnes traductions, DeepL produit de bonnes traductions en allemand et offre également une gamme de fonctionnalités qui simplifient le processus de traduction (termes du glossaire traduits correctement avec le pluriel et le cas corrects, édition en un clic, phrases en autocomplétion après avoir tapé un ou deux mots pour accélérer la reformulation). La traduction de GPT doit être nettement meilleure que celle de DeepL pour compenser le manque de fonctionnalités.
- La précision de GPT pourrait-elle être améliorée avec plus de contexte, comme un paragraphe contenant la phrase ?
- Si Google est capable de reconnaître le texte généré par l'IA, comment gérera-t-il les traductions GPT avec un minimum ou aucune modification ? Peut-il détecter le « style GPT » et pénaliser un texte dans ses résultats de recherche ?
En résumé, dans son état actuel, le GPT peut être une source d’inspiration pour nos cerveaux humains limités. Il peut fournir des traductions décentes. Plus que cela, il peut nous aider à reformuler des expressions trop utilisées, trouver des métaphores, et penser en dehors des sentiers battus.
Italien: Les moteurs de traduction automatique ont renvoyé des traductions littérales dans 70 % des cas
L'analyse suivante a été rédigée par notre linguiste anglais/italien Elvira Bianco.

Dans l’ensemble, tous les moteurs ont eu du mal avec la nature métaphorique du langage, se trompant souvent dans une littéralité excessive.
Résultats d'une perspective qualitative
Le tableau ci-dessous présente une analyse synthétique de 10 phrases idiomatiques anglaises traduites en italien, réalisée par notre équipe de linguistes.
La traduction automatique a donné une traduction littérale très éloignée du sens correct. GPT a transmis le sens et l’expression corrects à 70 %, pour les 30 % restants, il a utilisé des expressions acceptables qui ne sont pas largement utilisées ou perçues comme un langage natif naturel.
Le tableau ci-dessous contient l’analyse des données brutes.
Évaluation des GPTs Évaluation

Analyse et Clé Résultats
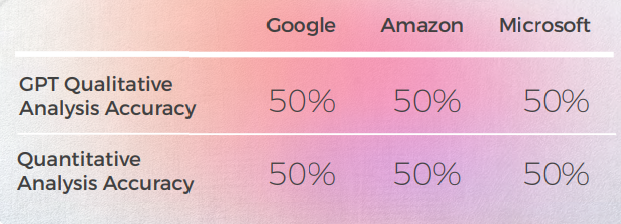
- Google Translate obtient seulement une bonne traduction et s'approche du sens dans 2 phrases.
- Amazon a donné 50% bon signifiant même si ce n'est pas en utilisant la manière la plus courante de transmettre le dicton anglais en langue italienne.
- Microsoft a donné 3 bonnes réponses en se rapprochant des dictons similaires italiens.
- Bien que le 1er Chat GPT approuve généralement les traductions automatiques, le 2e et le 3e Chat GPT donnent généralement le sens correct et ajoutent des suggestions de traduction précieuses.
Applications pratiques et limites
Telles que définies par https://it.wiktionary.org/wiki/espressione_idiomatica, une expression idiomatique typique d'une langue est généralement intraduisible littéralement dans d'autres langues, sauf en recourant à des expressions idiomatiques de la langue dans laquelle elle est traduite, avec des significations similaires aux expressions idiomatiques de la langue à partir de laquelle elle est traduite. Il est clair que la traduction mécanique produite par les machines de traduction les plus utilisées aujourd'hui (Google, Amazon, Microsoft) était peu fiable, malgré cela, GPT-3 s'est avéré capable à 70% de donner le bon sens et de fournir de bonnes suggestions dans l'adaptation de Contenu.
Il n'est pas improbable que dans un avenir proche, les machines mémoriseront également des expressions idiomatiques, mais bon, pour l'instant, nous avons besoin d'humains pour traduire en transmettant le même sens d'une langue à une autre.
Les langues sont pleines de nuances, de doubles sens, d’allusions, d’idiomes, de métaphores que seul un humain peut percevoir.
Le coréen avait la précision la plus basse parmi tous les moteurs testés
L'analyse suivante a été rédigée par notre linguiste anglais/coréen Sun Min Kim.

Résultats d'une perspective qualitative
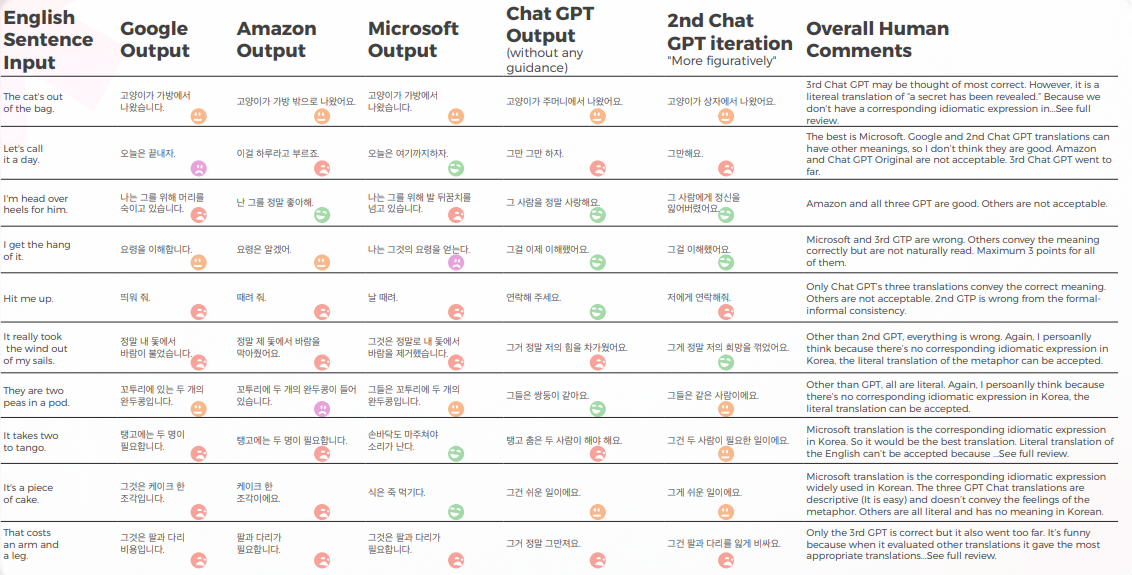
Le tableau ci-dessous présente une analyse synthétique de 10 phrases idiomatiques anglaises traduites en coréen, réalisée par notre équipe de linguistes.
La plupart des moteurs traduisent littéralement les expressions idiomatiques, tandis que GPT essaie de traduire de la manière la plus descriptive possible sans métaphore (par exemple, morceau de gâteau = facile, alors qu’en Corée, nous avons une expression idiomatique similaire qui transmet le même sens que Microsoft.
Les trois traductions de GPT ne sont pas cohérentes. Certains empirent avec l'itération.
Le tableau ci-dessous contient l’analyse des données brutes.
GPT connaît les problèmes lorsque les traductions tournent mal. Mais il n'est pas considéré comme correct de juger le meilleur.
Le GPT lui-même a des problèmes avec le traitement formel – informel et ainsi de suite) et il peut évaluer cette question.
Évaluation des GPTs Évaluation

Analyse et Clé Résultats
Parce que les originaux anglais dans cette étude sont des expressions idiomatiques, c'est un peu délicat car vous devez choisir entre la métaphore ou la description directe. Mais pour certaines expressions idiomatiques où la langue coréenne a des expressions idiomatiques similaires véhiculant le même sens, la plupart des moteurs n'ont pas réussi à trouver ces expressions, à quelques exceptions près (veuillez consulter la feuille de calcul et trouver celles avec le score de 5 par moi).
Pour d'autres, mon avis personnel est que si la métaphore elle-même peut véhiculer le sens, une traduction littérale peut être envisagée et il peut être préférable d'utiliser un mot descriptif. Bien sûr, si la métaphore n’a pas de contexte culturel en Corée, elle ne doit pas être traduite littéralement. Mais c'est une question subtile et peut-être liée à la préférence ou aux émotions humaines du Traducteur. Je ne pense pas qu'aucun moteur n'ait encore ce niveau de pensée humaine.
Applications pratiques et limitations
Je pense que la plupart des moteurs peuvent être utilisés à des fins de pré-traduction. Mais en considérant la Qualité, cela devrait être principalement pour des raisons d'efficacité uniquement (c'est-à-dire, ne pas taper à partir de zéro). Pour les textes plus descriptifs, tels que les manuels, je constate que la MTPE est bien plus avancée que ces expressions idiomatiques. Il y a donc encore de la place pour s'améliorer.
GPT a atteint un taux de réussite de 90 % dans les idiomes portugais brésiliens
L'analyse suivante a été rédigée par notre linguiste anglais/portugais Gabriel Fairman.

Dans l’ensemble, tous les moteurs ont eu du mal avec la nature métaphorique du langage, se trompant souvent dans une littéralité excessive.
Résultats d'une perspective qualitative
Le tableau ci-dessous présente une analyse synthétique de 10 phrases idiomatiques anglaises traduites en portugais, réalisée par notre équipe de linguistes.
La plupart des moteurs traduisent littéralement les expressions idiomatiques, tandis que GPT essaie de traduire de la manière la plus descriptive possible sans métaphore (par exemple, morceau de gâteau = facile, alors qu’en Corée, nous avons une expression idiomatique similaire qui transmet le même sens que Microsoft.
Les trois traductions de GPT ne sont pas cohérentes. Certains empirent avec l'itération.
Le tableau ci-dessous contient l’analyse des données brutes.
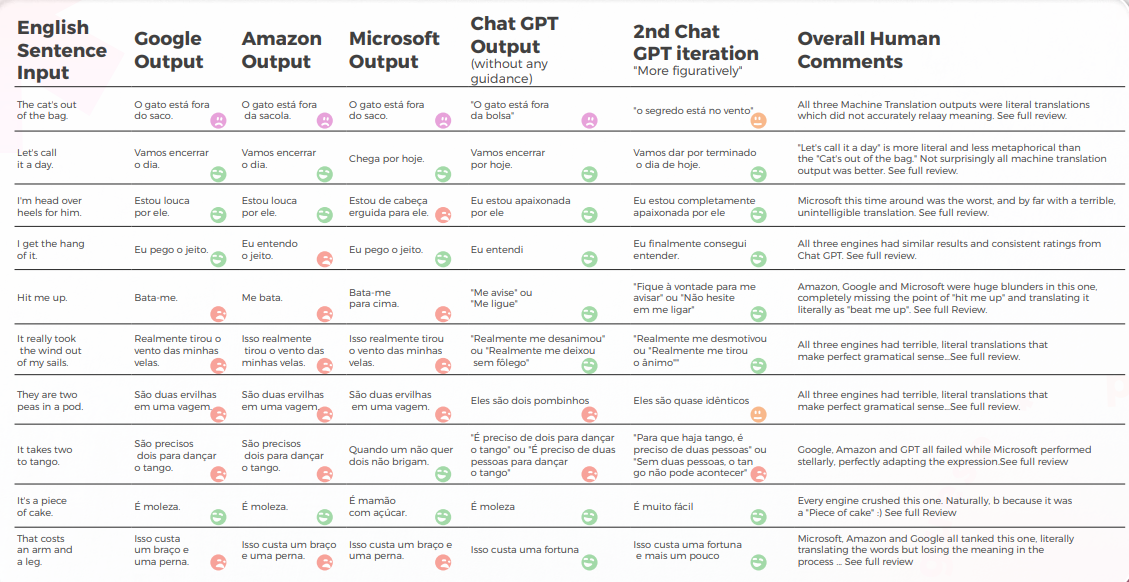
En ce qui concerne la qualité de la traduction, GPT a fait un excellent travail avec la contextualisation. Dans 9 phrases sur 10, le Contenu était bien adapté, intelligible et transmettait le sens approprié. Contrairement aux trois moteurs de traduction automatique, GPT n'a pas fait d'erreurs embarrassantes du type « Je veux pleurer ».
L'hypothèse initiale était qu'il y aurait une grande différence de Qualité entre les première et deuxième itérations de GPT, mais la Qualité de la traduction était similaire dans les deux.
Évaluation des Évaluations de GPTs
Analyse et Clé des Résultats
- Microsoft a fait des choix plus audacieux en ce qui concerne l'adaptation linguistique des expressions idiomatiques.
- GPT a eu plus de mal à évaluer les choix métaphoriques de Microsoft, car ils s'écartaient davantage.
- Google et Amazon ont obtenu des résultats extrêmement similaires, ne s’écartant que légèrement l’un de l’autre, reflétant les erreurs et les choix métaphoriques de l’autre. Microsoft s'est clairement démarqué des deux.
- GPT-3 a eu plus de facilité avec l’analyse qualitative, produisant une analyse textuelle convaincante (même si elle n’avait qu’une précision de 70 %).
- Bien qu’intelligible, l’analyse de GPT n’a pas permis d’identifier dans 30 % des cas. Cela a coïncidé avec des choix métaphoriques qui étaient littéraux et compréhensibles, mais qui s’écartaient du discours quotidien.
- GPT-3 a eu plus de mal à traduire l’analyse qualitative en un score.
- Bien que, d'une manière générale, les scores soient précis à 60 %, il était difficile de différencier des scores similaires tels qu'un 3 et un 4.
- La divergence extrême du score de 1 à 5 était plus facile à comprendre et plus compatible avec les commentaires globaux suggérant que :
- Peut-être que les critères de notation n’étaient pas suffisamment calibrés avec GPT-3
- Peut-être que la notation binaire pourrait être plus pertinente que la notation par gradient. Dans un cas anormal, Chat GPT-3 a évalué deux traductions similaires de manière radicalement différente, donnant à l’une un 1 et à l’autre un 5 alors que les deux auraient dû être 1.
- Même si, sur le plan quantitatif, Microsoft a obtenu des résultats similaires à ceux de Google et d’Amazon, lorsque vous entrez dans le vif du sujet, Microsoft a fait des choix plus audacieux et a fourni de meilleurs résultats d’un point de vue qualitatif, mais était encore loin derrière GPT-3 en matière de précision et d’adaptation culturelle.
Applications pratiques et limitations
Dans cette analyse, GPT-3 a fourni une contextualisation et une adaptation supérieures par rapport aux précédents
modèles de traduction automatique en portugais brésilien. Bien qu'il ne soit pas pratique de remplacer les modèles traditionnels de traduction automatique par des modèles plus grands tels que GPT-3 en raison des coûts informatiques élevés et des rendements marginaux décroissants en ce qui concerne le discours non métaphorique, GPT-3 peut être un puissant allié humain pour fournir des suggestions et identifier des erreurs potentielles ainsi que des opportunités d'amélioration.
Les cas limites linguistiques sont incroyables car ils illustrent si clairement combien il reste si peu lorsqu'il s'agit de modèles de langue. Même s'ils sont « presque » là, ce « presque » devient de plus en plus difficile à aborder et, si ce n'est plus difficile, certainement plus coûteux d'un point de vue informatique.
Bien qu'aucun des moteurs ne soit suffisamment fiable pour remplacer les humains (du moins dans le contexte de cette étude), GPT-3 montre une capacité claire à aider les traducteurs humains et les réviseurs dans le processus de traduction et d'évaluation de la langue.
Les MTs espagnols ont obtenu moins de 30 % — GPT était le gagnant évident
L'analyse suivante a été rédigée par notre linguiste anglais/espagnol Nicolas Davila.

Dans l’ensemble, tous les moteurs ont eu du mal avec la nature métaphorique du langage, se trompant souvent dans une littéralité excessive.
Résultats d'une perspective qualitative
Le tableau ci-dessous présente une analyse synthétique de 10 phrases idiomatiques anglaises traduites en espagnol, réalisée par notre équipe de linguistes.

En ce qui concerne la qualité de la traduction, GPT a fait un travail acceptable et meilleur que les autres en matière de contextualisation. Dans 7 phrases sur 10, le Contenu était intelligible, bien formé et transmettait le sens approprié, avec un faible taux de maladresse et de « j'ai envie de pleurer ».
Bien que l'hypothèse initiale était qu'il y aurait une grande différence de Qualité entre la première et les itérations suivantes de GPT, la Qualité de la traduction est similaire dans toutes. Les 2e et 3e itérations ajoutent parfois des éléments inutiles, augmentant légèrement le taux de maladresse.
Le tableau ci-dessous contient l’analyse des données brutes.
Évaluation des GPTs Évaluation

Analyse et Clé Résultats
- Les traductions MT étaient trop littérales, Amazon et Google étant très similaires en termes généraux, et Microsoft étant le pire.
- Google et Amazon ont obtenu des résultats extrêmement similaires, ne s’écartant que légèrement l’un de l’autre, reflétant les erreurs et les choix métaphoriques de l’autre. Microsoft a mal performé, produisant parfois des phrases mal formées et manquant certaines parties de la construction grammaticale.
- GPT-3 a eu plus de facilité avec l’analyse qualitative produisant une analyse textuelle cohérente, même si elle n’avait qu’une précision de 50 %.
- Souvent, l’analyse qualitative de GPT-3 était trop générale et plus restreinte au sens principal et littéral de la phrase, sans tenir compte des détails subtils de construction et de changement de sens. Il semble que GPT ne soit pas capable de détecter de telles différences et de les traduire en scores quantitatifs.
- De plus, GPT attribuait fréquemment la même analyse qualitative et un score quantitatif élevé à des phrases grammaticalement mal construites, ce qui semble être une limitation du modèle de GPT.
- GPT-3 a eu plus de mal à traduire l’analyse qualitative en un score.
- Il n’est précis qu’à 50 % pour Google et Amazon et à seulement 30 % pour Microsoft. Il semble que GPT ne mesurait que si la phrase transmettait le sens, mais pas les différences de construction ou de bonne formation.
- La divergence des scores de 1 à 5 était plus facile à comprendre et plus compatible avec l’ensemble des commentaires suggérant que : Peut-être que les critères de notation n’étaient pas suffisamment calibrés pour GPT-3. Peut-être que la notation binaire pourrait être plus pertinente que la notation par gradient. Peut-être que les critères de notation ou le modèle GPT ne prenaient pas en compte les problèmes grammaticaux, mais se concentraient uniquement sur la transmission du sens.
Applications pratiques et limitations
Dans cette analyse, GPT-3 a fourni une contextualisation et une adaptation supérieures par rapport aux modèles de traduction automatique précédents en espagnol d'Amérique latine.
GPT-3 pourrait être un outil puissant pour aider les humains à améliorer les traductions lorsqu'il s'agit de fournir des suggestions utiles et des opportunités d'amélioration. Mais, pour autant que je puisse voir, il a encore certaines limites.
Bien que des modèles plus grands comme GPT-3 puissent être utiles, il n'est pas pratique de les remplacer par des modèles traditionnels de traduction automatique, en raison de coûts de calcul plus élevés, car lorsqu'il s'agit de texte non métaphorique, cela pourrait réduire les gains marginaux.
Bien que GPT-3 montre une capacité évidente à aider les traducteurs humains et les réviseurs dans le processus de traduction et d'évaluation des langues, les considérations de coût doivent être incluses lors de l'évaluation de son utilisation pour des textes non métaphoriques.
Conclusions
Bien que les performances de ChatGPT puissent varier en fonction de l'invite et de la langue spécifique, notre étude suggère que ChatGPT a le potentiel de produire des traductions de plus haute Qualité que les moteurs de traduction automatique traditionnels, surtout lorsqu'il s'agit de gérer des expressions idiomatiques et un usage nuancé de la langue.
Cependant, il est important de noter que ChatGPT est loin de ne pas faire d’erreurs et qu’il a encore une immense marge d’amélioration, notamment lorsqu’il s’agit d’invites plus complexes ou de domaines linguistiques.
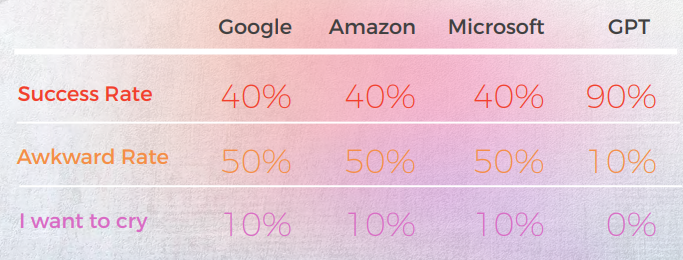
En tant que traducteur, ChatGPT a eu plus de succès que tous les moteurs de traduction automatique testés. Bien que les langues aient montré des résultats différents, le coréen était clairement l'exception avec une Qualité MT et une Qualité GPT significativement inférieures à celles des autres langues.
Dans toutes les langues, à l’exception du coréen, ChatGPT a eu un taux de réussite d’au moins 70 % et au plus un taux de réussite de 90 %, surpassant la traduction automatique traditionnelle. Et même en coréen, bien que les scores soient faibles, ils étaient toujours meilleurs que les résultats du moteur de traduction automatique.
Contrairement à la traduction automatique, avec un LLM, les itérations du même contenu peuvent améliorer la qualité de la sortie. C'est clé lorsqu'on pense aux intégrations, car alors qu'avec la MT traditionnelle votre sortie sera toujours la même que votre entrée (à moins que le moteur ne reçoive plus de données ou d'entraînement), avec un LLM on peut explorer plusieurs interactions via API afin d'optimiser la qualité du flux.
L’un des avantages de ChatGPT par rapport aux moteurs de traduction automatique traditionnels est sa capacité à apprendre et à s’améliorer au fil du temps, même sans données d’entraînement supplémentaires. Cela est dû à la nature des LLM, qui sont conçus pour affiner continuellement leurs modèles de langage en fonction de nouvelles entrées. Ainsi, ChatGPT peut potentiellement offrir des capacités de traduction plus adaptatives et dynamiques, ce qui pourrait être particulièrement utile dans des scénarios où la langue ou le Contenu évolue ou change constamment.
Un autre avantage de ChatGPT est son faible taux de grincement de dents, ce qui constitue une amélioration significative par rapport aux moteurs de traduction automatique traditionnels qui produisent souvent des traductions maladroites ou inappropriées. Cela pourrait rendre ChatGPT plus acceptable et convivial pour les utilisateurs non experts qui peuvent ne pas avoir le même niveau de connaissances linguistiques ou culturelles que les traducteurs professionnels.
Cependant, il est important de noter que ChatGPT n'est pas un substitut aux traducteurs humains, et il existe une myriade de cas où l'expertise et le jugement d'un traducteur humain sont nécessaires. Mais les taux de gêne nettement plus faibles de ChatGPT ouvrent la porte à une adoption plus large des traductions effectuées par des non-humains.
En tant qu’évaluateur, les performances de ChatGPT étaient plus mitigées, avec des taux de précision allant de 30 % à 70 %. Bien que cela suggère que ChatGPT pourrait ne pas être aussi efficace pour évaluer d'autres moteurs de traduction qu'il ne l'est pour proposer des traductions, il est possible que cela soit dû à la complexité et à la Qualité des invites d'évaluation, qui peuvent nécessiter des connaissances plus spécialisées ou contextuelles que celles que ChatGPT possède actuellement. Des recherches supplémentaires sont nécessaires pour explorer le potentiel de ChatGPT en tant qu’évaluateur, ainsi que ses limites et ses défis.Dans l’ensemble, notre étude suggère que ChatGPT dispose de capacités de traduction prometteuses qui méritent d’être explorées plus avant. Bien qu'il ne puisse pas remplacer ou contourner la totalité de Traducteurs humains, il pourrait potentiellement offrir des avantages significatifs en tant qu'outil d'aide ou de pré-traduction, surtout dans des scénarios où le temps, les Ressources ou l'expertise sont limités.
Comme pour toute technologie émergente, il reste encore de nombreux défis et opportunités d'amélioration, et des recherches et expérimentations supplémentaires seront nécessaires pour libérer pleinement son potentiel.
Méthodologie
Pour explorer comment les modèles de langage comme GPT-3 gèrent la traduction idiomatique par rapport aux moteurs de traduction automatique traditionnels, nous avons mené une expérience axée sur des cas limites linguistiques impliquant des métaphores et des expressions idiomatiques.
Sélection d'expressions idiomatiques
Nous avons sélectionné 10 idiomes anglais couramment utilisés, tels que « Concluons pour aujourd'hui », « Contacte-moi », et « Le TAO est sorti du sac. » Ces expressions sont bien connues pour mettre au défi les systèmes de traduction, car elles nécessitent une adaptation culturelle et contextuelle plutôt qu'une équivalence littérale.
Moteurs et modèles de traduction testés
Chaque idiome a été traduit à l’aide de :
- Google Translate
- Amazon Translate
- Microsoft Traducteur
- GPT-3 (ChatGPT) – en utilisant deux approches :
- Une traduction directe sans aucune orientation
- Une deuxième version incitée à être plus figurative et idiomatique

Processus d'évaluation
Les résultats traduits ont été examinés par des linguistes natifs dans sept langues cibles : Portugais brésilien, espagnol, français, allemand, italien, chinois et coréen. Pour chaque phrase, les évaluateurs ont évalué :
- Si le sens de l’idiome original a été préservé
- Le caractère naturel de l’expression dans la langue cible
- Grammaire, syntaxe et précision sémantique
Chaque traduction a été évaluée sur une échelle de 1 à 5 :
- 5: Sens correct et langage naturel
- 1 : Traduction incorrecte, déroutante ou non naturelle (niveau « Je veux pleurer »)
De plus, nous avons demandé à ChatGPT d’évaluer les traductions des autres moteurs, à la fois en fournissant des commentaires textuels qualitatifs et des scores numériques. Cela nous a permis d’évaluer sa capacité en tant qu’évaluateur, et pas seulement en tant que générateur de traduction.
Limites de l’étude
Il est important de noter qu’il s’agissait d’une étude exploratoire :
- L’échantillon était limité à 10 expressions idiomatiques avec un réviseur humain par langue.
- Toutes les évaluations comportent un certain degré de subjectivité et de préférence individuelle.
- Les performances de GPT-3 reflètent une version spécifique du modèle et peuvent évoluer avec des mises à jour.
Malgré ces contraintes, les découvertes fournissent un aperçu précieux des capacités et des limites des modèles actuels, surtout dans des scénarios linguistiquement nuancés et culturellement dépendants.
Avertissements
(Avertissements de recherche réels à ne pas prendre à la légère)
Bien que nous ayons cherché à explorer le potentiel des capacités linguistiques de ChatGPT, il est important de noter que cette étude n'a évalué qu'un aspect de la traduction, à savoir la capacité à gérer des cas limites idiomatiques et hautement métaphoriques. D’autres aspects de la traduction, tels que la compréhension culturelle et contextuelle, peuvent nécessiter des méthodes et des critères d’évaluation différents.
La taille de l'échantillon de cette étude est limitée à 10 expressions idiomatiques et un relecteur par langue, ce qui peut ne pas être représentatif de l'ensemble des expressions idiomatiques de la langue anglaise, ni de la diversité des perspectives et de l'expertise des Traducteurs professionnels. Par conséquent, les résultats de cette étude doivent être interprétés avec prudence et ne peuvent être généralisés à d’autres contextes ou domaines.
De plus, les opinions et les évaluations d’un seul évaluateur par langue sont subjectives et peuvent être influencées par des préjugés, des expériences ou des préférences personnels. Comme pour toute évaluation subjective, il existe un certain degré de variabilité et d’incertitude dans les résultats. Pour augmenter la fiabilité et la validité de nos trouvailles, les études futures pourraient impliquer plusieurs examinateurs, des évaluations à l'aveugle ou des mesures de fiabilité inter-évaluateurs.
Il convient également de noter que les capacités linguistiques de ChatGPT ne sont pas statiques et peuvent changer au fil du temps à mesure que le modèle est entraîné et affiné. Par conséquent, les résultats de cette étude doivent être considérés comme un instantané des performances du modèle à un moment précis, et peuvent ne pas refléter ses capacités actuelles ou futures.
Enfin, cette étude n’a pas pour but de faire des affirmations définitives ou catégoriques sur l’utilité ou les limites de ChatGPT pour la traduction. Au contraire, il est destiné à servir d'enquête préliminaire et de point de départ pour les futures recherches et développements dans le domaine du traitement du langage naturel et de la traduction automatique. Comme pour toute technologie émergente, il reste encore de nombreux défis et opportunités d'amélioration, et des expérimentations supplémentaires et une Collaboration seront nécessaires pour explorer pleinement son potentiel.
Libérez la puissance de la glocalisation avec notre système de gestion de traduction.
Libérez la puissance de la
stème de gestion de traduction.








