Vi testade Chat GPT för översättning – här är uppgifterna


Alla pratar om hur AI förändrar översättningen – men kan den verkligen hantera nyanserna i det mänskliga språket?
Nyligen genomförd forskning av Bureau Works satte detta på prov genom att jämföra GPT-3 med stora maskinöversättningsmotorer från Google, Amazon och Microsoft. Studien fokuserade på en av de svåraste utmaningarna inom lokalisering: idiomatiska uttryck. Varför? Eftersom bokstavliga översättningar inte räcker när du har att göra med fraser som "The CAT’s out of the bag" eller "Let’s call it a day."
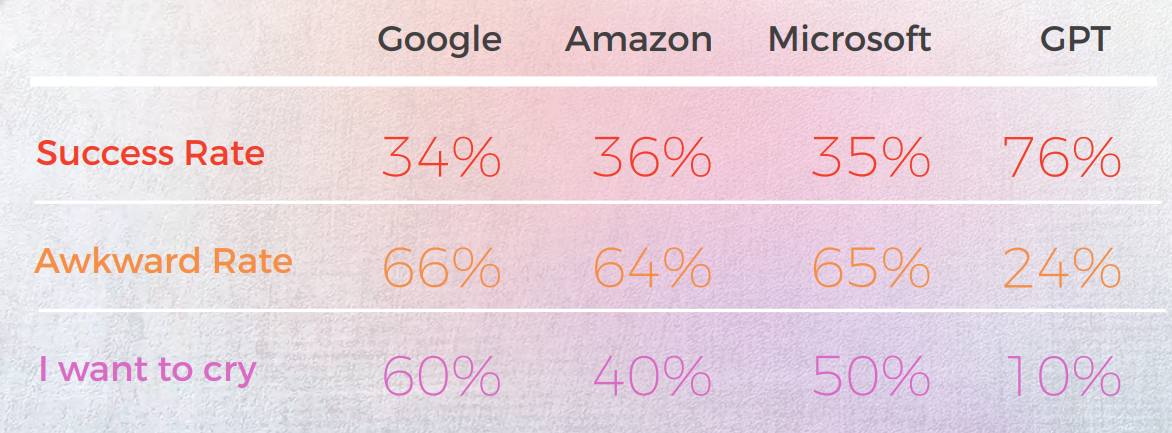
Resultaten var överraskande. GPT-3 levererade exakta, naturligt klingande översättningar upp till 90% av tiden, medan traditionella motorer låg mellan 20% och 50% — och ofta producerade pinsamma resultat som betygsattes som "Jag vill gråta" av infödda lingvister.
I en värld där språkliga nyanser kan göra eller förstöra ditt budskap, belyser dessa fynd både löftet och de nuvarande begränsningarna med AI i professionell översättning.
Här är en sammanfattning av våra Viktiga fynd:
- GPT-3 överträffade konsekvent traditionella MT-motorer (Google, Amazon, Microsoft) när det gällde att hantera idiomatiska uttryck – upp till 90 % noggrannhet på språk som portugisiska och kinesiska.
- Traditionella motorer kämpade med metaforer och bildspråk och levererade ofta ordagranna översättningar som var grammatiskt korrekta men semantiskt felaktiga – vissa fick till och med "Jag vill gråta"-betyg från inhemska recensenter.
- Microsoft tog fler risker och erbjöd djärvare översättningar som ibland avvek från originalet men kändes mer naturliga – även om GPT hade svårare att utvärdera dessa kreativa val.
- GPT:s kvalitativa analys var stark, men den hade svårt att tilldela konsekventa numeriska poäng, särskilt när man skilde mellan medelklassbetyg som 3 vs. 4.
- På nästan alla språk förbättrade GPT:s andra iteration – när den uppmanades till en mer figurativ version – tydligheten, tonen och den kulturella passformen.
- Koreanska var det mest utmanande språket, både för traditionella maskinöversättningar och GPT-3, och uppvisade betydligt lägre prestanda över hela linjen.
- GPT-3 visade sig vara värdefull inte bara som en Översättare utan också som ett verktyg för utvärdering och revidering, genom att hjälpa till att identifiera klumpiga eller felaktiga formuleringar och erbjuda alternativ.
GPT uppnådde 90 % noggrannhet i kinesiska idiom—MTs hade svårt
Följande analys skrevs av vår engelska/kinesiska lingvist James Hou.

Sammantaget kämpade alla motorer med språkets metaforiska natur och gjorde ofta misstag i överdriven bokstavlighet. Till exempel, översättningen "Låt oss kalla det en dag."" är en mer bokstavlig och något klumpig översättning av "Let's call it a day". Det förmedlar innebörden av den ursprungliga frasen, men formuleringen är något besvärlig och kanske inte är lika lätt för personer som har kinesiska som modersmål att förstå.
Även om det exakt förmedlar innebörden av den ursprungliga frasen, är formuleringen något besvärlig och kan vara mindre tydlig för modersmålstalare.
Utdata från ett kvalitativt perspektiv
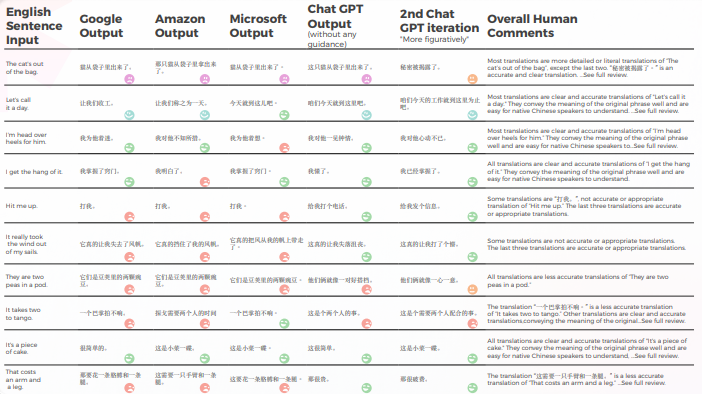
Tabellen nedan presenterar en syntetisk analys av 10 engelska idiomatiska meningar översatta till kinesiska, utförd av vårt team av lingvister.
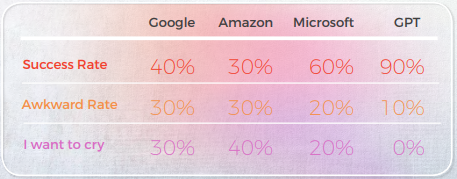
När det gäller översättningskvalitet gjorde GPT ett bra jobb med kontextualisering. Till exempel, "秘密被揭露了。” är en korrekt och tydlig översättning för “Katten är ute ur påsen”. I 9 av 10 meningar var innehållet väl anpassat, begripligt och förmedlade den lämpliga betydelsen. Tvärtemot de tre maskinöversättning-motorerna hade GPT inga pinsamma "I want to cry"-misstag.
Tabellen nedan innehåller rådataanalysen.
Utvärdering av GPTs Utvärdering
Analys och Viktiga Resultat
- Google och Amazon hade extremt liknande resultat, som endast avvek något från varandra, speglade varandras misstag och metaforiska val. Till exempel översättningen "打我"." är inte en korrekt eller lämplig översättning av "Hit me up". Uttrycket "Hit me up" betyder att Kontakta oss eller ta kontakt med någon, vanligtvis via telefon eller textmeddelande. Den kinesiska frasen "打我" betyder "slå mig", och den förmedlar inte innebörden av den ursprungliga frasen.
- Microsoft gjorde djärvare val när det gäller den lingvistiska anpassningen av idiomen.
- GPT hade svårare att utvärdera Microsofts metaforiska val eftersom de avvek mer.
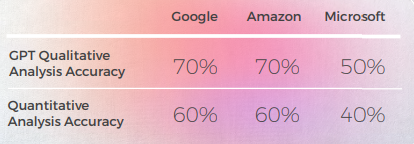
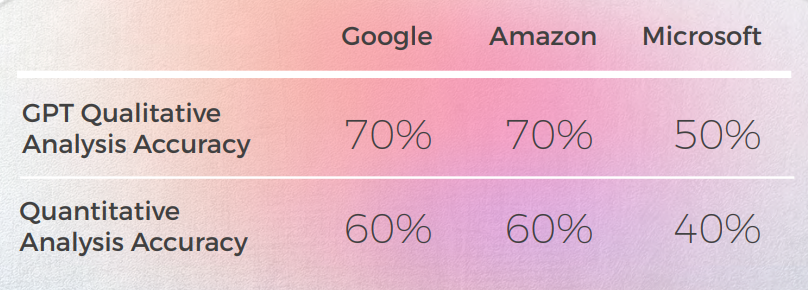
- GPT-3 hade det lättare med den kvalitativa analysen som gav övertygande textanalys (även om den bara hade 70 % noggrannhet).
- Även om det är begripligt misslyckades GPT:s analys att identifiera i 30 % av fallen. Detta sammanföll med metaforiska val som var bokstavliga och förståeliga, men som avvek från den vardagliga diskursen.
- GPT-3 hade svårare att översätta den kvalitativa analysen till en poäng. Även om poängen i stort sett var 60 % korrekta, var det svårt att skilja mellan liknande resultat som en 3 kontra en 4.
- Extrem poängskillnad från 1 till 5 var lättare att förstå och mer kompatibel med övergripande kommentarer som föreslog att:
- Kanske var poängkriterierna inte tillräckligt kalibrerade med GPT-3
- Kanske kan binär poängsättning vara mer relevant än gradientpoängsättning
- • Även om Microsoft kvantitativt presterade på samma sätt som Google och Amazon, gjorde Microsoft djärvare val och gav bättre resultat ur ett kvalitativt perspektiv när man går in på språkets detaljer, men låg fortfarande långt efter GPT-3 när det gällde noggrannhet och kulturell anpassning. Till exempel, översättningen "Jag har fått kläm på det."" är en tydlig och korrekt översättning av "Jag får kläm på det." Den förmedlar innebörden av den ursprungliga frasen väl och är lätt att förstå för personer som har kinesiska som modersmål. Det är också ett mer bildligt och idiomatiskt sätt att uttrycka idén om att förstå eller bemästra något jämfört med andra möjliga översättningar.
Praktiska tillämpningar och begränsningar
I denna analys gav GPT-3 överlägsen kontextualisering och anpassning jämfört med tidigare maskinöversättningsmodeller.
Även om ingen av motorerna är tillräckligt pålitliga för att ersätta människor (åtminstone i kontexten av denna studie), visar GPT-3 en tydlig förmåga att hjälpa mänskliga översättare och granskare i processen att översätta och utvärdera språk.
Franska: MT-motorer misslyckades med 60 % av idiomen—GPT utmärkte sig
Följande analys skrevs av vår engelska/franska lingvist Laurène Bérard.

Sammantaget kämpade alla motorer med språkets metaforiska natur och gjorde ofta misstag i överdriven bokstavlighet.
Output från ett kvalitativt perspektiv
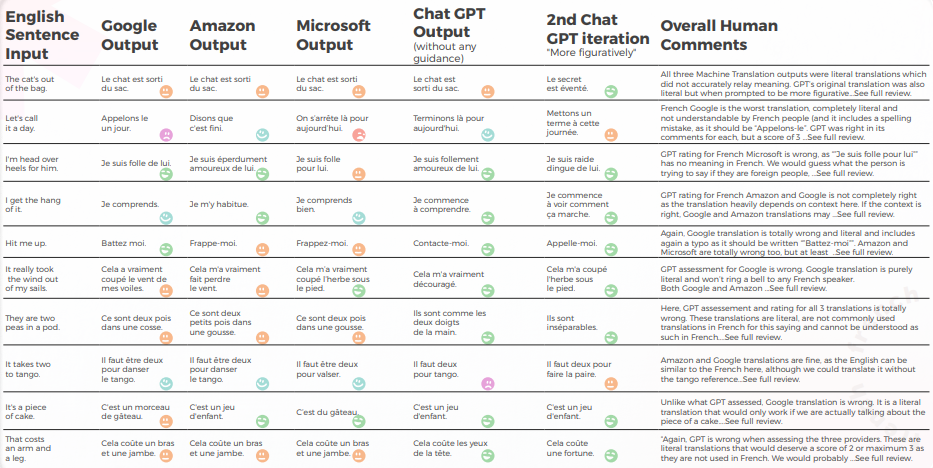
Tabellen nedan presenterar en syntetisk analys av 10 engelska idiomatiska meningar översatta till franska, utförd av vårt team av lingvister.

När det gäller översättningskvalitet gjorde GPT ett bra jobb med kontextualisering. Utan någon vägledning hade GPT helt fel för “The CAT’s out of the bag” men hade rätt med mer vägledning, och dess 3 översättningar var grammatiskt ofullständiga och därmed ganska svåra att förstå för “It takes two to tango”.
Innehållet var generellt väl anpassat, begripligt och förmedlade den avsedda betydelsen. De tre maskinöversättning-motorerna hade en hög "jag vill gråta"-frekvens medan även utan kontext skulle en översättare ha gissat att det inte var menat bokstavligt (t.ex. "Låt oss avsluta för dagen", vilket är ganska uppenbart men missförstods helt av Google-motorn).
Tabellen nedan innehåller rådataanalysen.
Utvärdering av GPTs Utvärdering
Analys och Viktiga Resultat
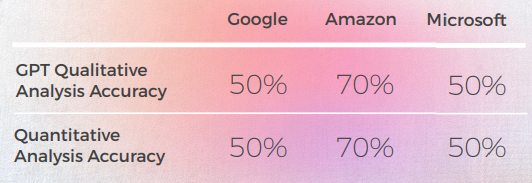
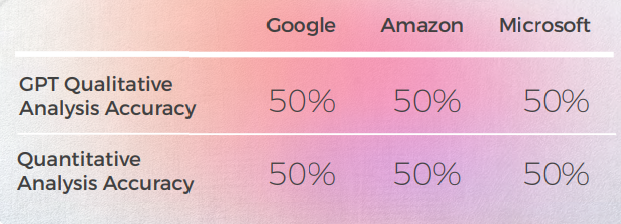
- Trots att den översatte korrekt 8 gånger av 10, var GPT-analysen av de 3 motorerna ofta felaktig, eftersom nästan 50% av fallen angav att deras översättning var bra medan den inte var det.
- Även om begriplig GPT:s analys misslyckades med att identifiera problem i 30 till 50 % av fallen, sammanföll detta med val som var bokstavliga och skulle ha varit korrekta om de inte hade hanterat idiomatiska uttryck.
- GPT misslyckades med att upptäcka de två stavningsproblemen från Google ("Appelons le" och "Battez moi").
- GPT:s kvalitativa och kvantitativa analyser var globalt konsistenta med varandra.
- GPT hade svårare att utvärdera Microsofts och Googles översättningar.
- Microsoft gjorde bättre val när det gäller den lingvistiska anpassningen av idiomen.
- Google och Amazon hade mycket liknande resultat, bara något avvikande från varandra. Microsoft stack ut från de två.
- I ett fall (tangouttrycket) bedömde GPT att en bra översättning från Microsoft var fel (poäng 2) medan den var förståelig och lika bra som Google- och Amazon-översättningarna som GPT utvärderade positivt (poäng 5), men det kan förklaras av det faktum att Microsoft inte var lika bokstavlig som de andra två motorerna, eftersom de valde att nämna vals istället för tango.
- Microsoft gjorde djärvare val och gav bättre resultat ur ett kvalitativt perspektiv men låg fortfarande långt efter GPT när det kom till noggrannhet och kulturell anpassning.
Praktiska tillämpningar och begränsningar
I denna analys gav GPT mycket bättre kontextualisering och anpassning än Amazons, Googles och Microsofts maskinöversättningsmotorer. Även om det inte är praktiskt att ersätta traditionella maskinöversättning-modeller med större modeller som GPT-3 på grund av höga beräkningskostnader och avtagande marginalnytta när det gäller icke-metaforisk diskurs, kan GPT-3 vara en kraftfull mänsklig allierad när det gäller att ge förslag och identifiera potentiella misstag samt möjligheter till förbättring.
Även om maskinöversättning motorer är "nästan" där, blir detta "nästan" successivt svårare att hantera, vilket bevisas av GPT här.
Även om ingen av motorerna är tillräckligt pålitliga för att ersätta människor (åtminstone i kontexten av denna studie), visar GPT en tydlig förmåga att hjälpa mänskliga översättare och granskare i processen att översätta och utvärdera språk.
GPT överträffade alla MT-motorer i tyska idiom med 30 %
Följande analys skrevs av vår engelska/tyska lingvist Olga Schneider.

Sammantaget producerade GPT den mest exakta översättningen. Den analyserade alltid den engelska meningen noggrant och kunde vanligtvis avgöra om en maskinöversättning var bokstavlig eller idiomatisk, men den misslyckades med att upptäcka en felöversättning 50% av gångerna.
Utdata från ett kvalitativt perspektiv
Tabellen nedan presenterar en syntetisk analys av 10 engelska idiomatiska meningar översatta till tyska, utförd av vårt team av lingvister.

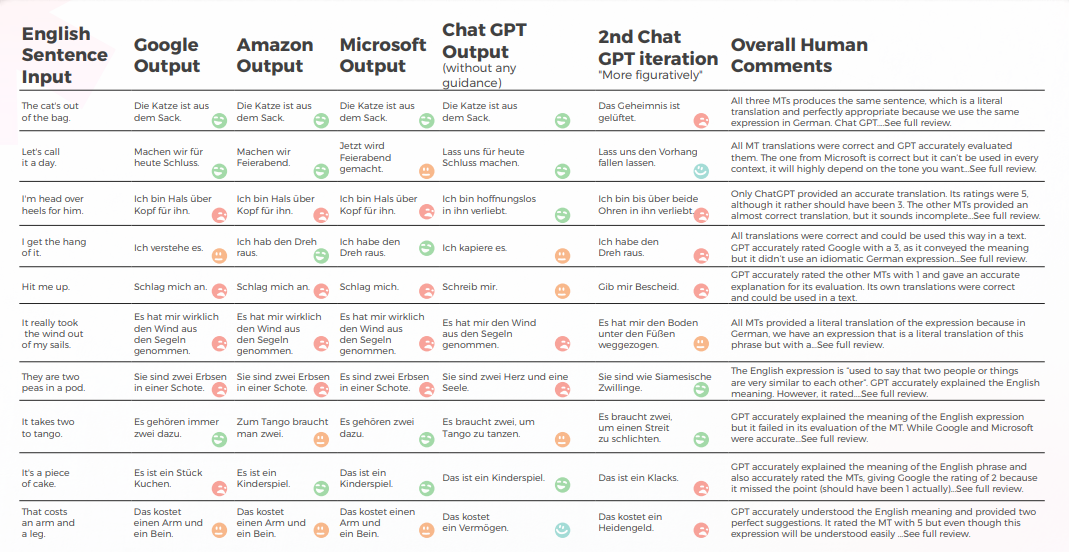
GPT ger bra resultat 8 av 10 gånger på första försöket och 7 av 10 gånger på andra försöket. Till exempel var det bara GPT som kunde tillhandahålla korrekta idiomatiska översättningar av "I'm head over heels for him" och "Hit me up".
Den sista, mest bildliga utmatningen producerade 4 bra meningar, medan de andra antingen var helt rätt eller "jag vill gråta". Sammantaget producerade Amazon och Microsoft något bättre översättningar än Google.
Tabellen nedan innehåller rådataanalysen.
Utvärdering av GPTs utvärdering
Analys och Viktiga resultat
- GPT har en ganska bra kunskap om tyska idiomatiska uttryck, även de som inte riktigt matchade den engelska meningen var idiomatiska uttryck av en liknande kategori. Till exempel: "Låt oss dra ur kontakten" och "Låt oss fälla ridån" för "Låt oss avsluta för idag". Den förstår den allmänna innebörden av dessa fraser relaterade till "slut" och kan vara en användbar inspirationskälla.
- När det gäller kreativa uttryck verkar GPT hämta inspiration från engelska fraser och föreslår den bokstavliga tyska översättningen av "Jag är kär i honom från topp till tå" som ett kreativt alternativ till "Jag är upp över öronen för honom".
- GPT:s översättningsbetyg var en hit eller miss och visade sig vara opålitliga. I ett fall gav den en Google-översättning betyget 2, och det var inte klart varför den inte var den 1 som den borde ha varit.
- Tyska och engelska har många idiomatiska uttryck gemensamt, vilket gör översättningen enklare. Men uttryck som är främmande för tyskan (t.ex. "De är som ler och långhalm" eller "Det är lätt som en plätt") översätts till slut ordagrant. När det gäller ärtorna, till skillnad från översättningsmotorerna, förstod GPT att det behövde ge uttryck om "tvåor". Men uttrycken som det gav – även om de var korrekta och ofta användes – förmedlade inte den korrekta innebörden.
Praktiska tillämpningar och begränsningar
GPT gav bättre översättningar än Google, Amazon och Microsoft. Även om det inte är 100% tillförlitligt, kan det ge en bättre utgångspunkt för maskinöversättning redigering än de andra tre motorerna. Även om idiomatiska uttryck är viktiga, finns det ett annat problem som ofta uppstår vid maskinöversättning av engelsk till tysk text: besvärlig meningsstruktur som ligger för nära originaltexten. Det skulle vara viktigt att se hur GPT löser detta problem.
När det gäller utvärdering är GPT inte ett bra verktyg, eftersom dess utvärdering av tyska översättningar bara är 50 % korrekt.
Tre fler saker hade varit intressanta att se:
- Kan GPT konkurrera med DeepL för tyska? Även om GPT kan ge bra översättningar, producerar DeepL bra tyska översättningar och erbjuder också en rad funktioner som förenklar översättningsprocessen (ordlista termer översätts korrekt med rätt plural och kasus, redigering med ett klick, autokomplettering av meningar efter att ha skrivit ett eller två ord för att påskynda omformulering). GPT:s översättning behöver vara betydligt bättre än den från DeepL för att kompensera för bristen på funktioner.
- Kan GPT:s noggrannhet förbättras med mer sammanhang, till exempel ett stycke som innehåller frasen?
- Om Google kan känna igen AI-genererad text, hur kommer den att hantera GPT-översättningar med minimal eller ingen redigering? Kan den upptäcka "GPT-stilen" och straffa en text i sina sökresultat?
Sammanfattningsvis kan GPT i sitt nuvarande tillstånd vara en inspirationskälla för våra begränsade mänskliga hjärnor. Det kan ge anständiga översättningar. Mer än så, det kan hjälpa oss att omformulera överanvända uttryck, hitta metaforer och tänka utanför boxen.
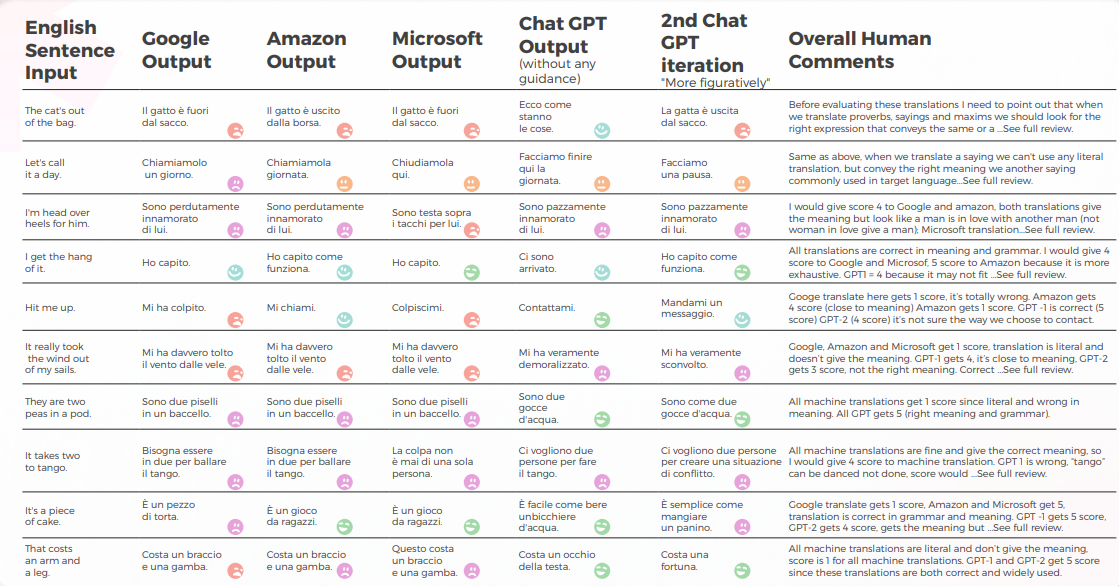
Italienska: MT-motorer returnerade bokstavliga översättningar i 70 % av fallen
Följande analys skrevs av vår engelska/italienska lingvist Elvira Bianco.

Sammantaget kämpade alla motorer med språkets metaforiska natur och gjorde ofta misstag i överdriven bokstavlighet.
Output från ett kvalitativt perspektiv
Tabellen nedan presenterar en syntetisk analys av 10 engelska idiomatiska meningar översatta till italienska, utförd av vårt team av lingvister.
Maskinöversättning gav en bokstavlig översättning som var mycket långt ifrån den korrekta betydelsen. GPT förmedlade den korrekta innebörden och uttrycket till 70 %, för de återstående 30 % använde acceptabla uttryck som inte används i stor utsträckning eller uppfattas som naturligt inhemskt tal.
Tabellen nedan innehåller rådataanalysen.
Utvärdering av GPTs Utvärdering

Analys och Viktiga Resultat
- Google Translate får bara en rätt översättning och kommer nära betydelsen i 2 meningar.
- Amazon gav 50% rätt betydelse även om de inte använde det vanligaste sättet att uttrycka det engelska uttrycket på italienska.
- Microsoft gav 3 rätt svar och kom närmare italienska liknande uttryck.
- Medan 1:a Chat GPT vanligtvis godkänner maskinöversättningar, ger 2:a och 3:e Chat GPT vanligtvis den korrekta betydelsen och lägger till värdefulla översättningsförslag.
Praktiska tillämpningar och begränsningar
Enligt definitionen i https://it.wiktionary. org/wiki/espressione_idiomatica är ett idiomatiskt uttryck som är typiskt för ett språk vanligtvis oöversättbart bokstavligen till andra språk, förutom genom att använda idiomatiska uttryck för det språk som det översätts till, med betydelser som liknar de idiomatiska uttrycken för det språk från vilket det översätts. Det är tydligt att den mekaniska översättningen som produceras av dagens mest använda översättningsmaskiner (Google, Amazon, Microsoft) var opålitlig, men GPT-3 visade sig kunna ge den rätta betydelsen till 70% och ge bra förslag vid anpassning av Innehåll.
Det är inte osannolikt att maskiner i en nära framtid också kommer att memorera idiomatiska uttryck, men just nu behöver vi människor för att översätta och förmedla samma betydelse från ett språk till ett annat.
Språk är fulla av nyanser, dubbeltydigheter, allusioner, idiom, metaforer som bara en människa kan uppfatta.
Koreanska hade den lägsta noggrannheten bland alla testade motorer
Följande analys skrevs av vår engelska/koreanska lingvist Sun Min Kim.

Utdata från ett kvalitativt perspektiv
Tabellen nedan presenterar en syntetisk analys av 10 engelska idiomatiska meningar översatta till koreanska, utförd av vårt team av lingvister.
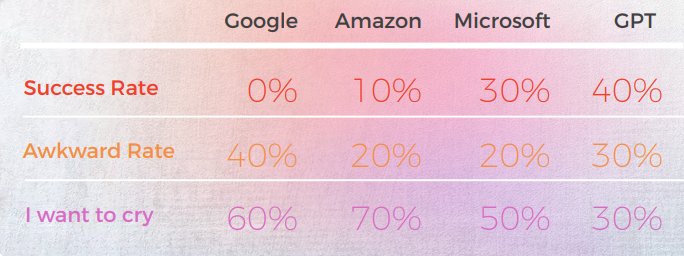
De flesta motorer översätter bokstavligen de idiomatiska uttrycken, medan GPT försöker översätta så beskrivande som möjligt utan metafor (t.ex. piece of cake = lätt, medan vi i Korea har ett liknande idiomatiskt uttryck som förmedlar samma betydelse som Microsoft gjorde.
GPT:s tre översättningar är inte konsekventa. Vissa blir sämre med iterationen.
Tabellen nedan innehåller rådataanalysen.
GPT känner till problemen när översättningarna blir fel. Men det anses inte vara korrekt att bedöma den bästa.
GPT har i sig problem med den formella – informella behandlingen och så vidare) och den kan utvärdera denna fråga.
Utvärdering av GPTs Utvärdering

Analys och Viktiga Resultat
Eftersom de engelska originalen i denna studie är idiomatiska uttryck, är det lite knepigt eftersom du måste välja mellan metaforen eller direkt beskrivning. Men för vissa idiomatiska uttryck där det koreanska språket har liknande idiomatiska uttryck som förmedlar samma betydelse, missade de flesta motorerna att hitta dessa uttryck med bara några få undantag (vänligen se kalkylbladet och hitta de med poängen 5 av mig).
För andra är min personliga tanke att om metaforen i sig kan förmedla betydelsen, kan en bokstavlig översättning av den övervägas och kanske är det bättre att använda ett beskrivande ord. Naturligtvis, om metaforen inte har någon kulturell kontext i Korea, bör den inte översättas ordagrant. Men det är en subtil fråga och kanske upp till preferensen eller de mänskliga känslorna hos översättaren. Jag tror inte att någon motor har den nivån av mänskligt tänkande ännu.
Praktiska tillämpningar och begränsningar
Jag tror att de flesta av motorerna kan användas för föröversättning. Men med tanke på Kvaliteten bör det främst vara för effektivitetens skull (det vill säga, inte skriva från grunden). För mer beskrivande texter, som manualer, ser jag att MTPE är mycket mer avancerat än dessa idiomatiska uttryck. Så det finns fortfarande utrymme för förbättringar.
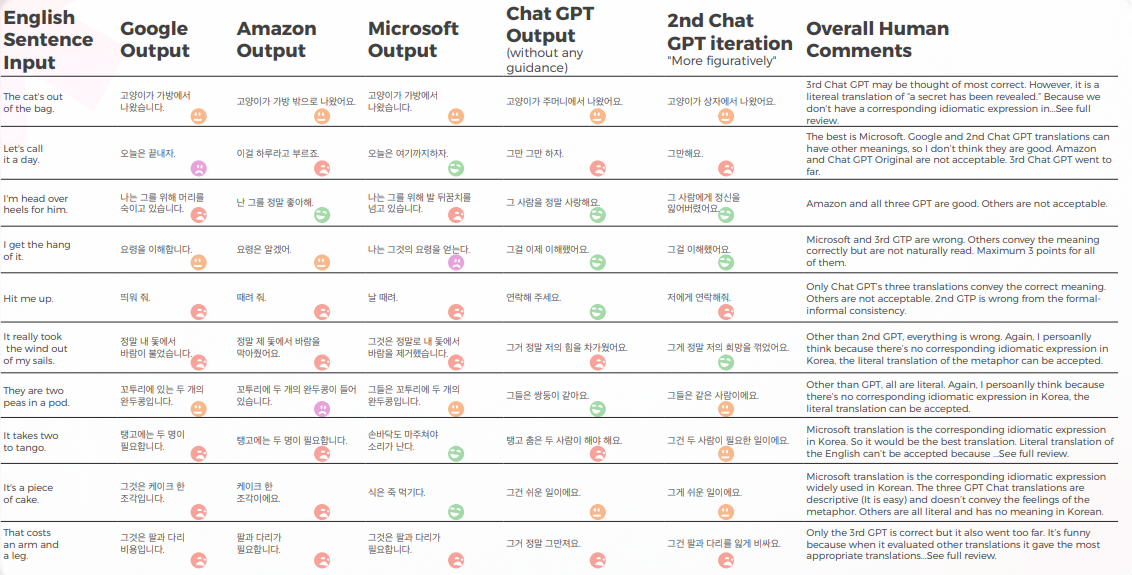
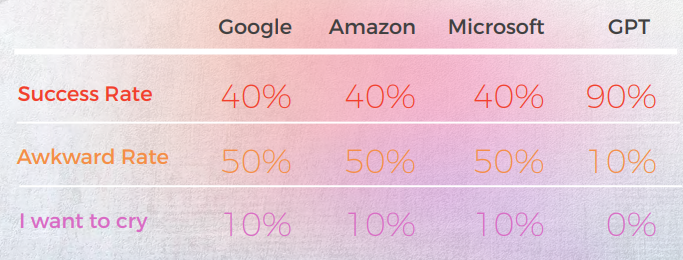
GPT nådde 90 % framgångsgrad i brasilianska portugisiska idiom
Följande analys skrevs av vår engelska/portugisiska lingvist Gabriel Fairman.

Sammantaget kämpade alla motorer med språkets metaforiska natur och gjorde ofta misstag i överdriven bokstavlighet.
Utdata från ett kvalitativt perspektiv
Tabellen nedan presenterar en syntetisk analys av 10 engelska idiomatiska meningar översatta till portugisiska, utförd av vårt team av lingvister.
De flesta motorer översätter bokstavligen de idiomatiska uttrycken, medan GPT försöker översätta så beskrivande som möjligt utan metafor (t.ex. piece of cake = lätt, medan vi i Korea har ett liknande idiomatiskt uttryck som förmedlar samma betydelse som Microsoft gjorde.
GPT:s tre översättningar är inte konsekventa. Vissa blir sämre med iterationen.
Tabellen nedan innehåller rådataanalysen.
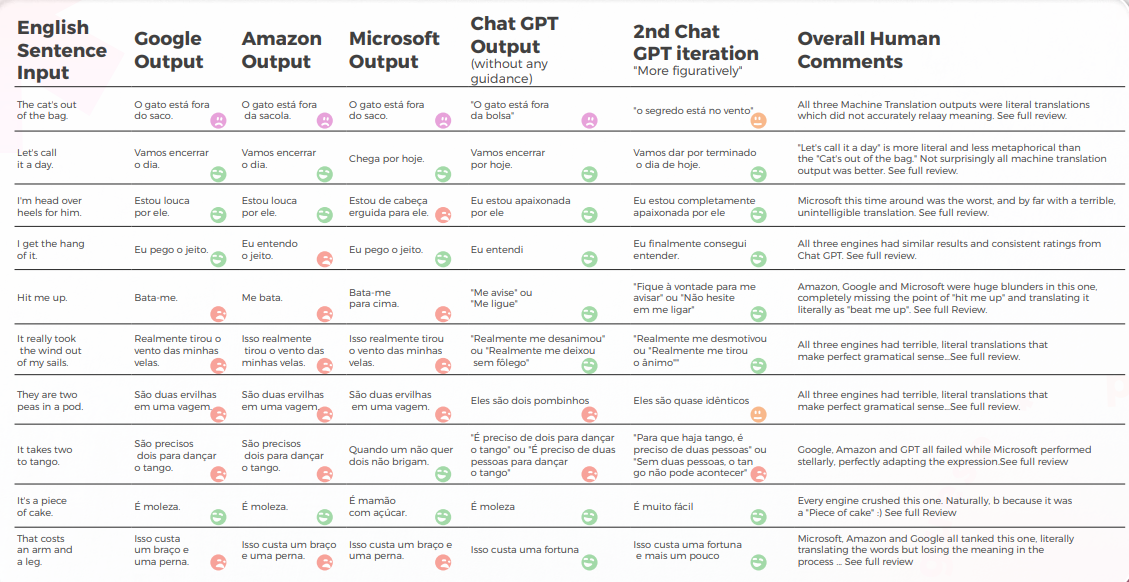
När det gäller översättningskvalitet gjorde GPT ett bra jobb med kontextualisering. I 9 av 10 meningar var innehållet väl anpassat, begripligt och förmedlade den lämpliga betydelsen. Tvärtemot de tre maskinöversättning-motorerna hade GPT inga pinsamma "I want to cry"-misstag.
Den initiala hypotesen var att det skulle vara en stor skillnad i Kvalitet mellan GPT:s första och andra iterationer, men översättningskvaliteten var liknande i båda.
Utvärdering av GPTs Utvärdering
Analys och Viktiga Resultat
- Microsoft gjorde djärvare val när det gäller den lingvistiska anpassningen av idiomen.
- GPT hade svårare att utvärdera Microsofts metaforiska val eftersom de avvek mer.
- Google och Amazon hade extremt liknande resultat, bara något avvikande från varandra, speglade varandras misstag och metaforiska val. Microsoft stack tydligt ut från de två.
- GPT-3 hade det lättare med den kvalitativa analysen som gav övertygande textanalys (även om den bara hade 70 % noggrannhet).
- Även om det är begripligt misslyckades GPT:s analys att identifiera i 30 % av fallen. Detta sammanföll med metaforiska val som var bokstavliga och förståeliga, men som avvek från den vardagliga diskursen.
- GPT-3 hade svårare att översätta den kvalitativa analysen till en poäng.
- Även om poängen i stort sett var 60 % korrekta, var det svårt att skilja mellan liknande resultat som en 3 kontra en 4.
- Extrem poängskillnad från 1 till 5 var lättare att förstå och mer kompatibel med övergripande kommentarer som föreslog att:
- Kanske var poängkriterierna inte tillräckligt kalibrerade med GPT-3
- Kanske kan binär poängsättning vara mer relevant än gradientpoäng. I ett avvikande fall utvärderade Chat GPT-3 två liknande översättningar på radikalt olika sätt, vilket gav den ena en 1 och den andra en 5 när båda borde ha varit 1.
- Även om Microsoft kvantitativt presterade på samma sätt som Google och Amazon, gjorde Microsoft djärvare val och gav bättre resultat ur ett kvalitativt perspektiv när man går in på språkets detaljer, men låg fortfarande långt efter GPT-3 när det gällde noggrannhet och kulturell anpassning.
Praktiska tillämpningar och begränsningar
I denna analys gav GPT-3 överlägsen kontextualisering och anpassning jämfört med tidigare
maskinöversättningsmodeller på brasiliansk portugisiska. Även om det inte är praktiskt att ersätta traditionella maskinöversättningsmodeller med större modeller som GPT-3 på grund av höga beräkningskostnader och avtagande marginalnytta när det gäller icke-metaforisk diskurs, kan GPT-3 vara en kraftfull mänsklig allierad när det gäller att ge förslag och identifiera potentiella misstag samt möjligheter till förbättring.
Lingvistiska undantagsfall är fantastiska eftersom de så tydligt illustrerar hur mycket som finns kvar i så lite när det gäller språkmodeller. Även om de är "nästan" där, blir detta "nästan" allt svårare att ta itu med och om inte svårare, definitivt dyrare ur ett beräkningsperspektiv.
Även om ingen av motorerna är tillräckligt pålitliga för att ersätta människor (åtminstone i kontexten av denna studie), visar GPT-3 en tydlig förmåga att hjälpa mänskliga översättare och granskare i processen att översätta och utvärdera språk.
Spanska MTs fick under 30 %—GPT var den klara vinnaren
Följande analys skrevs av vår engelska/spanska lingvist Nicolas Davila.

Sammantaget kämpade alla motorer med språkets metaforiska natur och gjorde ofta misstag i överdriven bokstavlighet.
Utdata från ett kvalitativt perspektiv
Tabellen nedan presenterar en syntetisk analys av 10 engelska idiomatiska meningar översatta till spanska, utförd av vårt team av lingvister.

När det gäller översättningskvalitet gjorde GPT ett acceptabelt jobb och bättre än de andra med kontextualisering. I 7 av 10 meningar var Innehållet begripligt, välformat och förmedlade den avsedda betydelsen, med låg grad av besvärlighet och "jag vill gråta"-frekvenser.
Även om den initiala hypotesen var att det skulle vara en stor skillnad i Kvalitet mellan GPT:s första och efterföljande iterationer, är översättningskvaliteten liknande i alla. 2:a och 3:e iterationerna Lägg till ibland onödiga saker, vilket ökar den besvärliga graden något.
Tabellen nedan innehåller rådataanalysen.
Utvärdering av GPTs Utvärdering

Analys och Viktiga Resultat
- MT-översättningar var för bokstavliga, där Amazon och Google var mycket lika i allmänna termer, och Microsoft var den sämsta.
- Google och Amazon hade extremt liknande resultat, bara något avvikande från varandra, speglade varandras misstag och metaforiska val. Microsoft presterade dåligt och producerade ibland meningar som var dåligt utformade och saknade vissa delar av den grammatiska konstruktionen.
- GPT-3 hade lättare med den kvalitativa analysen och producerade en sammanhängande textanalys, även om den bara hade 50 % noggrannhet.
- Ofta var GPT-3:s kvalitativa analys för allmän och mer begränsad till meningens huvudsakliga och bokstavliga betydelse, utan att ta hänsyn till subtila detaljer i konstruktionen och förändringar i betydelsen. Det verkar som om GPT inte kan fånga upp sådana skillnader och översätta dem till kvantitativa poäng.
- GPT tilldelade också ofta samma kvalitativa analys och höga kvantitativa poäng till meningar som var grammatiskt dåligt konstruerade, vilket verkar vara en begränsning i GPT:s modell.
- GPT-3 hade svårare att översätta den kvalitativa analysen till en poäng.
- Att det bara är 50 % korrekt för Google och Amazon och bara 30 % korrekt för Microsoft. Det verkar som om GPT bara mätte om meningen förmedlade betydelsen, men inga skillnader i konstruktion eller välformulering.
- Poängskillnaden från 1 till 5 var lättare att förstå och mer kompatibel med de övergripande kommentarerna som föreslog att: Kanske var poängkriterierna inte tillräckligt kalibrerade för GPT-3. Kanske kan binär poängsättning vara mer relevant än gradientpoängsättning. Kanske tog poängkriterierna eller GPT-modellen inte hänsyn till grammatiska frågor, utan förmedlade bara betydelse.
Praktiska tillämpningar och begränsningar
I denna analys gav GPT-3 överlägsen kontextualisering och anpassning jämfört med tidigare maskinöversättningsmodeller på latinamerikansk spanska.
GPT-3 kan vara ett kraftfullt verktyg för att hjälpa människor att förbättra översättningar när det handlar om att ge användbara förslag och möjligheter till förbättring. Men så vitt jag kan se har den fortfarande vissa begränsningar.
Även om större modeller som GPT-3 kan vara till hjälp, är det inte lämpligt att ersätta traditionella maskinöversättningsmodeller med dem, på grund av högre beräkningskostnader, eftersom det när det gäller icke-metaforisk text kan minska marginalvinster.
Även om GPT-3 visar tydlig förmåga att hjälpa mänskliga översättare och granskare i processen att översätta och utvärdera språk, bör kostnadsöverväganden inkluderas när man utvärderar dess användning för icke-metaforiska texter.
Slutsatser
Även om ChatGPT:s prestation kan variera beroende på uppmaningen och det specifika språket, tyder vår studie på att ChatGPT har potential att producera översättningar av högre Kvalitet än traditionella MT-motorer, särskilt när det gäller att hantera idiomatiska uttryck och nyanserad språkbruk.
Det är dock viktigt att notera att ChatGPT är långt ifrån att inte göra misstag och att det fortfarande finns ett enormt utrymme för förbättringar, särskilt när det gäller mer komplexa uppmaningar eller språkdomäner.
Som en översättare var ChatGPT mer framgångsrik än alla testade maskinöversättningstjänster. Även om språken visade olika resultat, var koreanska tydligt avvikande med MT Kvalitet och GPT Kvalitet som var betydligt lägre än andra språk.
På alla språk utom koreanska hade ChatGPT minst 70 % framgång och högst 90 % framgång, vilket presterade bättre än traditionell maskinöversättning. Och även på koreanska, även om poängen var låga, var de fortfarande bättre än MT-motorns resultat.
Till skillnad från maskinöversättning kan iterationer av samma innehåll med en LLM förbättra utdata kvaliteten. Detta är viktigt när man tänker på integrationer eftersom med traditionell MT kommer din output alltid att vara densamma som din input (om inte motorn får ytterligare data eller träning), medan med en LLM kan man utforska flera interaktioner via API för att optimera flödeskvalitet.
En fördel med ChatGPT jämfört med traditionella MT-motorer är dess förmåga att lära sig och förbättras med tiden, även utan ytterligare träningsdata. Detta beror på LLM:ernas natur, som är utformade för att kontinuerligt förfina sina språkmodeller baserat på ny input. Således kan ChatGPT potentiellt erbjuda mer adaptiva och dynamiska översättningsmöjligheter, vilket kan vara särskilt användbart i scenarier där språket eller Innehållet ständigt utvecklas eller förändras.
En annan fördel med ChatGPT är dess låga cringe-frekvens, vilket är en betydande förbättring jämfört med traditionella MT-motorer som ofta producerar besvärliga eller olämpliga översättningar. Detta kan göra ChatGPT mer acceptabelt och användarvänligt för icke-expertanvändare som kanske inte har samma nivå av språklig eller kulturell kunskap som professionella översättare.
Det är dock viktigt att notera att ChatGPT inte är en ersättning för mänskliga översättare, och det finns en myriad av fall där expertisen och omdömet hos en mänsklig översättare behövs. Men ChatGPT:s betydligt lägre cringe-frekvens öppnar dörren för en bredare användning av icke-mänskligt drivna översättningar.
Som utvärderare var ChatGPT:s prestanda mer blandad, med en noggrannhet på mellan 30 % och 70 %. Även om detta antyder att ChatGPT kanske inte är lika effektiv på att utvärdera andra översättningsmotorer som den är på att föreslå översättningar, är det möjligt att detta beror på komplexiteten och Kvaliteten på utvärderingsfrågorna, som kan kräva mer specialiserad eller kontextuell kunskap än vad ChatGPT för närvarande besitter. Ytterligare forskning behövs för att utforska ChatGPT:s potential som utvärderare, samt dess begränsningar och utmaningar.
Sammantaget tyder vår studie på att ChatGPT har lovande översättningsmöjligheter som är värda att utforska ytterligare. Även om det kanske inte kan ersätta eller kringgå mänskliga översättare helt, kan det potentiellt erbjuda betydande fördelar som ett hjälpmedel eller föröversättningsverktyg, särskilt i scenarier där tid, resurser eller expertis är begränsade.
Som med all ny teknik finns det fortfarande många utmaningar och möjligheter till förbättring, och ytterligare forskning och experimentering kommer att behövas för att fullt ut låsa upp dess potential.
Metodologi
För att utforska hur språkmodeller som GPT-3 hanterar idiomatisk översättning jämfört med traditionella maskinöversättningsmotorer, genomförde vi ett experiment fokuserat på lingvistiska specialfall som involverar metaforer och idiomatiska uttryck.
Urval av idiomatiska uttryck
Vi valde ut 10 vanliga engelska idiom, såsom "Låt oss avsluta för idag," "Hör av dig," och "The CAT's out of the bag." Dessa uttryck är välkända för att utmana översättningssystem, eftersom de kräver kulturell och kontextuell anpassning snarare än bokstavlig likvärdighet.
Översättningsmotorer och modeller testade
Varje idiom översattes med:
- Google Translate
- Amazon Translate
- Microsoft Översättare
- GPT-3 (ChatGPT) – med två metoder:
- En direkt översättning utan någon vägledning
- En andra version som uppmanas att vara mer bildlig och idiomatisk

Utvärderingsprocess
De översatta resultaten granskades av infödda lingvister över sju målspråk: Brasiliansk portugisiska, spanska, franska, tyska, italienska, kinesiska och koreanska. För varje mening utvärderade granskarna:
- Om betydelsen av det ursprungliga idiomet bevarades
- Uttryckets naturlighet på målspråket
- Grammatik, syntax och semantisk noggrannhet
Varje översättning bedömdes på en skala från 1 till 5:
- 5: Korrekt betydelse och naturligt klingande språk
- 1: Felaktig, förvirrande eller onaturlig översättning ("Jag vill gråta"-nivå)
Dessutom bad vi ChatGPT att utvärdera de andra motorernas översättningar, både genom att ge kvalitativ textfeedback och numeriska poäng. Detta gjorde det möjligt för oss att bedöma dess kapacitet som utvärderare, inte bara som översättningsgenerator.
Studiens begränsningar
Det är viktigt att notera att detta var en explorativ studie:
- Urvalet var begränsat till 10 idiom med en mänsklig granskare per språk.
- Alla utvärderingar har en viss grad av subjektivitet och individuella preferenser.
- GPT-3:s prestanda återspeglar en specifik version av modellen och kan utvecklas med Uppdatera.
Trots dessa begränsningar ger resultaten värdefull insikt i kapaciteterna och begränsningarna hos nuvarande modeller, särskilt i lingvistiskt nyanserade och kulturellt beroende scenarier.
Ansvarsfriskrivningar
(Verkliga forskningsansvarsfriskrivningar som inte bör tas lätt på)
Även om vi strävade efter att utforska potentialen i ChatGPT:s språkkapaciteter, är det viktigt att notera att denna studie endast utvärderade en aspekt av översättning, nämligen förmågan att hantera lingvistiska idiomatiska och mycket metaforiska gränsfall. Andra aspekter av översättning, såsom kulturell och kontextuell förståelse, kan kräva andra utvärderingsmetoder och kriterier.
Urvalsstorleken i denna studie är begränsad till 10 idiom och en granskare per språk, vilket kanske inte är representativt för hela spektrumet av idiomatiska uttryck i det engelska språket, eller för det spektrum av perspektiv och expertis hos professionella översättare. Som sådan bör resultaten av denna studie tolkas med försiktighet och kan inte generaliseras till andra sammanhang eller domäner.
Dessutom är åsikterna och utvärderingarna från den enskilda granskaren per språk subjektiva och kan påverkas av personliga fördomar, erfarenheter eller preferenser. Som med alla subjektiva bedömningar finns det en viss variabilitet och osäkerhet i resultaten. För att öka tillförlitligheten och validiteten av våra fynd, kan framtida studier involvera flera granskare, blinda utvärderingar eller mått på interbedömarreliabilitet.
Det är också värt att notera att ChatGPT:s språkkunskaper inte är statiska och kan förändras med tiden i takt med att modellen tränas och finjusteras ytterligare. Därför bör resultaten av denna studie betraktas som en ögonblicksbild av modellens prestanda vid en viss tidpunkt och kanske inte återspeglar dess nuvarande eller framtida kapacitet.
Slutligen är denna studie inte avsedd att göra några definitiva eller kategoriska påståenden om användbarheten eller begränsningarna av ChatGPT för översättning. Snarare är det tänkt att fungera som en preliminär undersökning och utgångspunkt för framtida forskning och utveckling inom området för naturlig språkbehandling och maskinöversättning. Precis som med all ny teknik finns det fortfarande många utmaningar och möjligheter till förbättring, och ytterligare experimentering och Samarbete kommer att behövas för att fullt ut utforska dess potential.
Lås upp kraften i glokalisering med vårt översättningshanteringssystem.
Lås upp kraften i
med vårt översättningshanteringssystem.








