번역을 위해 Chat GPT를 테스트했습니다 – 데이터는 다음과 같습니다.


모두가 AI가 번역을 어떻게 변화시키고 있는지에 대해 이야기하고 있지만, 실제로 인간 언어의 뉘앙스를 처리할 수 있을까요?
Bureau Works의 최근 연구는 이를 시험하여 GPT-3을 Google, Amazon, Microsoft의 주요 기계 번역 엔진과 비교했습니다. 이 연구는 현지화에서 가장 어려운 과제 중 하나인 관용적 표현에 초점을 맞췄습니다. 왜? 직역은 "The CAT’s out of the bag"이나 "Let’s call it a day" 같은 구문을 다룰 때 효과적이지 않습니다.
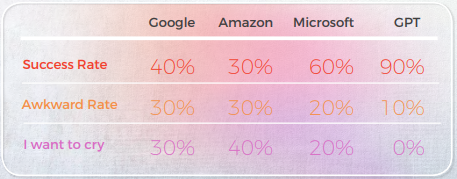
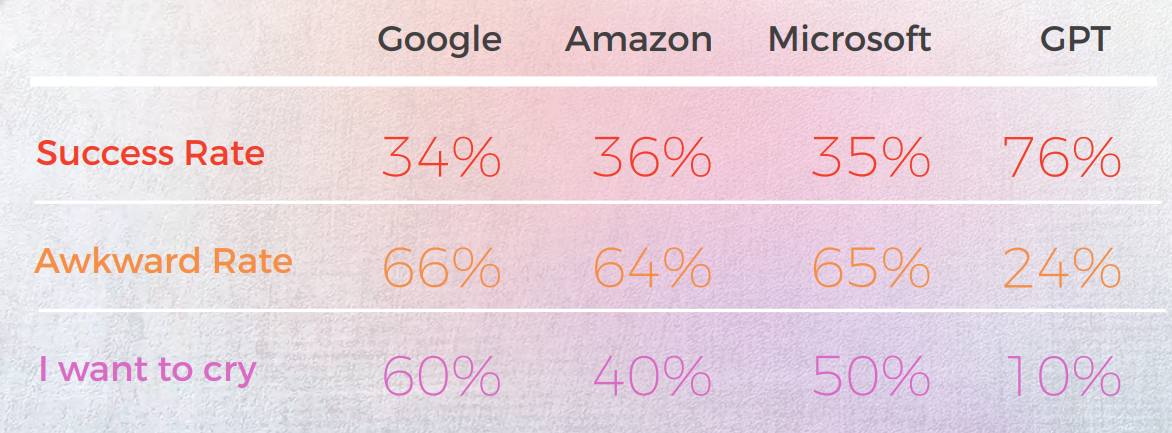
결과는 놀라웠습니다. GPT-3는 최대 90%의 시간 동안 정확하고 자연스러운 번역을 제공한 반면, 전통적인 엔진은 20%에서 50% 사이에 머물렀고, 종종 원어민 언어학자들에 의해 "울고 싶다"라고 평가되는 민망한 결과물을 만들어냈습니다.
언어적 뉘앙스가 메시지의 성패를 좌우할 수 있는 세상에서, 이러한 발견은 전문 번역에서 AI의 가능성과 현재의 한계를 모두 강조합니다.
여기 우리의 키 발견 사항 요약이 있습니다:
- GPT-3는 포르투갈어 및 중국어와 같은 언어에서 최대 90%의 정확도에 도달하여 관용적 표현을 처리하는 데 있어 기존 MT 엔진(Google, Amazon, Microsoft)을 지속적으로 능가했습니다.
- 기존 엔진은 은유와 비유적 언어에 어려움을 겪었으며, 문법적으로는 정확하지만 의미상으로는 잘못된 문자 그대로의 번역을 제공하는 경우가 많았고, 일부는 원어민 리뷰어로부터 "울고 싶다"라는 평가를 받기도 했습니다.
- 마이크로소프트는 더 많은 위험을 감수하며 때로는 원본에서 벗어나지만 더 자연스럽게 느껴지는 대담한 번역을 제공했습니다. 그러나 GPT는 이러한 창의적인 선택을 평가하는 데 더 어려움을 겪었습니다.
- GPT의 정성적 분석은 강력했지만 특히 3과 같은 중간 범위 등급을 구별할 때 일관된 수치 점수를 할당하는 데 어려움을 겪었습니다. 4.
- 거의 모든 언어에서 GPT의 두 번째 반복은 더 비유적인 버전을 요청받았을 때 명확성, 어조 및 문화적 적합성을 개선했습니다.
- 한국어는 기존 MT와 GPT-3 모두에서 가장 어려운 언어로 전반적으로 현저히 낮은 성능을 보였습니다.
- GPT-3는 번역가로서뿐만 아니라 평가 및 수정 도구로서도 가치가 있음을 입증했으며, 어색하거나 부정확한 표현을 지적하고 대안을 제시하는 데 도움을 줍니다.
GPT는 중국어 관용구에서 90%의 정확도를 달성했습니다—기계 번역은 어려움을 겪었습니다
다음 분석은 저희 영어/중국어 언어학자 James Hou가 작성했습니다.

전반적으로 모든 엔진은 언어의 은유적 특성과 씨름했으며 종종 과도한 문자 그대로의 오류를 범했습니다. 예를 들어, 번역 "让我们称之为一天"은..."는 "Let's call it a day"의 더 문자 그대로이고 다소 어색한 번역입니다. 원래 문구의 의미를 전달하지만 표현이 다소 어색하고 중국어 원어민이 이해하기 쉽지 않을 수 있습니다.
원래 구문의 의미를 정확하게 전달하지만, 표현이 다소 어색하고 원어민에게는 명확하지 않을 수 있습니다.
질적 관점에서의 출력
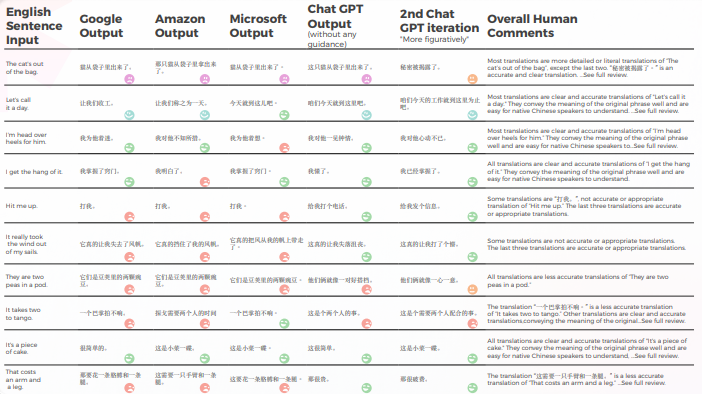
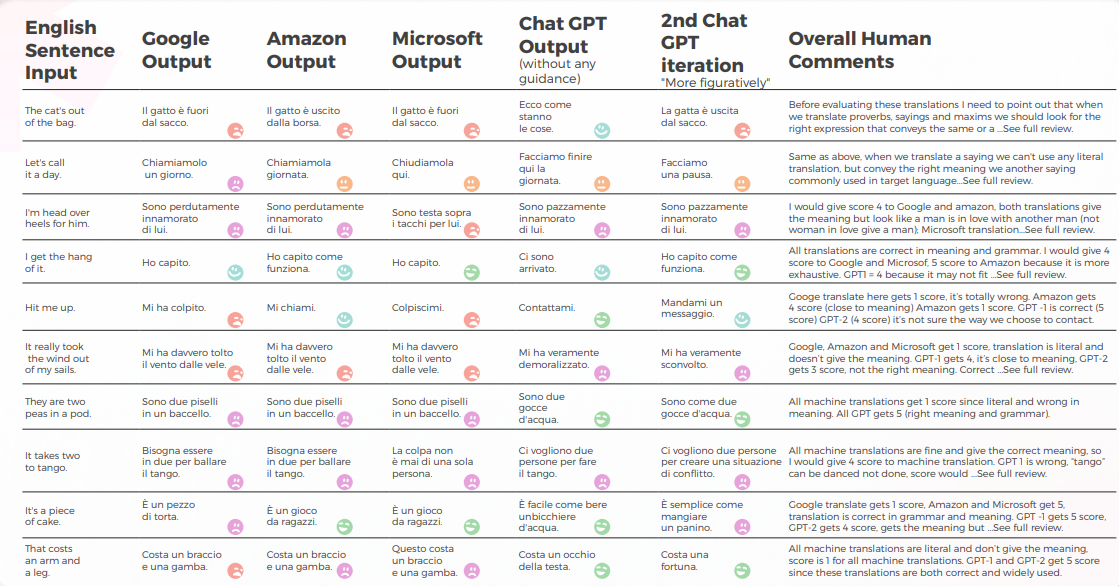
아래 표는 우리 언어학자 팀이 중국어로 번역한 10개의 영어 관용구 문장에 대한 종합 분석을 보여줍니다.
번역 품질에 관해서는, GPT가 맥락화에서 훌륭한 작업을 했습니다. 예를 들어 "비밀이 드러났다.""CAT가 가방에서 나왔다"는 정확하고 명확한 번역입니다. 10개의 문장 중 9개에서, 콘텐츠는 잘 적응되었고, 이해 가능하며, 적절한 의미를 전달했습니다. 세 개의 기계 번역 엔진과 달리, GPT는 당황스러운 "I want to cry" 실수를 하지 않았습니다.
아래 표에는 원시 데이터 분석이 포함되어 있습니다.
GPTs 평가
분석 및 키 찾기
- Google과 Amazon은 매우 유사한 결과를 보였으며, 서로의 실수와 비유적 선택을 반영하며 약간만 차이가 있었습니다. 예를 들어, 번역은 "打我"입니다."는 "Hit me up"의 정확하거나 적절한 번역이 아닙니다. “Hit me up”라는 표현은 일반적으로 전화나 문자 메시지로 누군가에게 연락하기를 의미합니다. 중국어 문구 "打我"는 "나를 때리다"를 의미하며 원래 문구의 의미를 전달하지 않습니다.
- Microsoft는 관용구의 언어적 적응에 있어 더 대담한 선택을 했습니다.
- GPT는 Microsoft의 은유적 선택이 더 많이 벗어남에 따라 평가하기가 더 어려웠습니다.
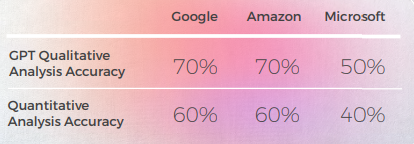
- GPT-3는 정성적 분석을 통해 설득력 있는 텍스트 분석을 생성하는 데 더 수월했습니다(정확도가 70%에 불과함).
- GPT의 분석은 이해할 수 있지만 사례의 30%에서 식별에 실패했습니다. 이것은 문자 그대로이고 이해할 수 있지만 일상적인 담론에서 벗어난 은유적 선택과 일치했습니다.
- GPT-3는 정성적 분석을 점수로 변환하는 데 어려움을 겪었습니다. 대체로 점수의 정확도는 60%였지만 3점과 4점과 같은 유사한 점수를 구별하기가 어려웠습니다.
- 1에서 5까지의 극단적인 점수 차이는 이해하기 쉬웠고 다음을 제안하는 전반적인 의견과 더 잘 맞았습니다.
- 아마도 채점 기준이 GPT-3로 충분히 보정되지 않았을 수 있습니다
- 아마도 이진 채점이 그래디언트 채점보다 더 관련성이 높을 수 있습니다
- • 양적으로 Microsoft는 Google 및 Amazon과 유사한 성능을 보였지만, 언어의 세부 사항으로 들어가면 Microsoft는 더 대담한 선택을 하고 질적 관점에서 더 나은 결과를 제공했지만, 정확성과 문화적 적응 측면에서는 여전히 GPT-3에 비해 크게 뒤처져 있었습니다. 예를 들어, 번역 "我掌握了窍门"은/는..."는 "I get the hang of it"의 명확하고 정확한 번역입니다. 원래 구문의 의미를 잘 전달하고 중국어 원어민이 쉽게 이해할 수 있습니다. 이것은 또한 다른 가능한 번역과 비교하여 무언가를 이해하거나 숙달하는 아이디어를 표현하는 더 비유적이고 관용적인 방법입니다.
실용적인 응용 및 한계
이 분석에서 GPT-3는 이전 기계 번역 모델보다 우수한 맥락화 및 적응을 제공했습니다.
어떤 엔진도 인간을 대체할 만큼 신뢰할 수는 없지만(적어도 이 연구의 맥락에서는), GPT-3는 인간 번역가와 검토자가 언어를 번역하고 평가하는 과정에서 도움을 줄 수 있는 명확한 능력을 보여줍니다.
프랑스어: MT 엔진은 관용구의 60%에서 실패했습니다—GPT가 두드러졌습니다
다음 분석은 저희 영어/프랑스어 언어학자 Laurène Bérard가 작성했습니다.

전반적으로 모든 엔진은 언어의 은유적 특성과 씨름했으며 종종 과도한 문자 그대로의 오류를 범했습니다.
정성적 관점에서의 출력
아래 표는 우리 언어학자 팀이 수행한 10개의 영어 관용구 문장을 프랑스어로 번역한 합성 분석을 보여줍니다.

번역 품질에 관해서는, GPT가 맥락화에서 훌륭한 작업을 했습니다. 지침이 전혀 없을 때, GPT는 "The cat’s out of the bag"에 대해 완전히 틀렸지만, 더 많은 지침이 있을 때는 적합했으며, "It takes two to tango"에 대한 3개의 번역은 문법적으로 불완전하여 이해하기 상당히 어려웠습니다.
콘텐츠는 일반적으로 잘 적응되었고, 이해 가능하며 적절한 의미를 전달했습니다. 세 개의 기계 번역 엔진은 높은 "울고 싶다" 비율을 보였지만, 맥락이 없어도 번역가는 그것이 문자 그대로의 의미가 아님을 추측했을 것입니다 (예: "오늘은 여기까지 하자"는 것은 매우 명백하지만 Google 엔진에 의해 완전히 오해되었습니다.
아래 표에는 원시 데이터 분석이 포함되어 있습니다.
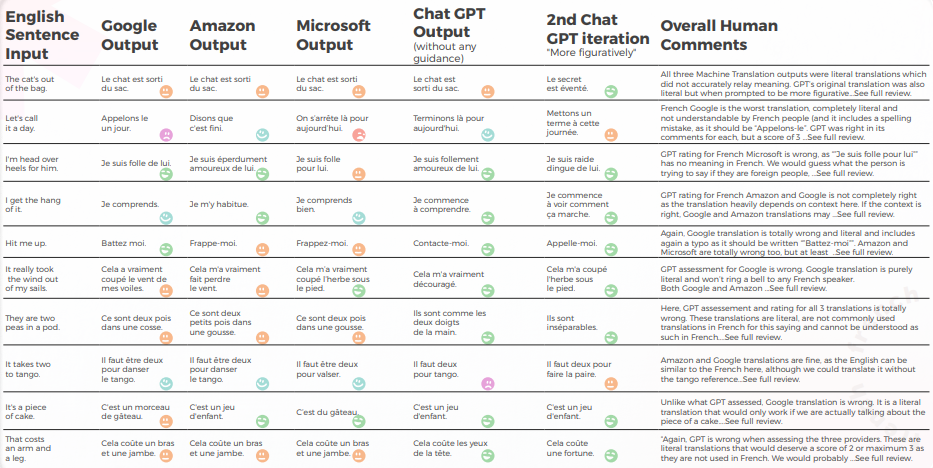
GPTs 평가 평가
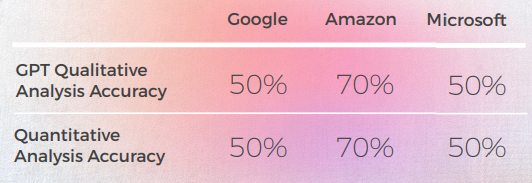
분석 및 키 찾기
- 10번 중 8번은 올바르게 번역했음에도 불구하고, 3개의 엔진에 대한 GPT 분석은 종종 잘못되었으며, 사례의 거의 50%가 번역이 괜찮다고 했지만 그렇지 않았습니다.
- 이해할 수 있는 GPT의 분석은 사례의 30-50%에서 문제를 식별하지 못했지만, 이는 문자 그대로의 선택과 일치했으며 관용적 표현을 다루지 않았다면 정확했을 것입니다.
- GPT는 Google에서 두 가지 철자 문제("Appelons le" 및 "Battez moi")를 발견하지 못했습니다.
- GPT 정성적 분석과 정량적 분석은 전 세계적으로 서로 일관성이 있었습니다.
- GPT는 Microsoft와 Google의 번역을 평가하는 데 더 어려움을 겪었습니다.
- Microsoft는 관용구의 언어적 적응에 있어 더 나은 선택을 했습니다.
- Google과 Amazon은 매우 유사한 결과를 보였지만 서로 약간 벗어났을 뿐입니다. Microsoft는 둘 중에서 두드러졌습니다.
- 한 가지 경우(탱고 표현)에서 GPT는 Microsoft의 훌륭한 번역을 틀렸다고 평가했지만(점수 2), 이는 이해할 수 있었고 GPT가 긍정적으로 평가한 Google 및 Amazon 번역(점수 5)만큼 동등하게 우수했습니다. 그러나 Microsoft가 다른 두 엔진만큼 문자 그대로 번역하지 않았다는 사실로 설명될 수 있습니다. Microsoft는 탱고 대신 왈츠를 언급하기로 선택했습니다.
- Microsoft는 더 대담한 선택을 하고 질적 관점에서 더 나은 결과를 제공했지만, 정확성과 문화적 적응에 있어서는 여전히 GPT에 비해 많이 뒤처져 있었습니다.
실용적인 응용과 한계
이 분석에서 GPT는 Amazon, Google 및 Microsoft 기계 번역 엔진보다 훨씬 더 나은 맥락화와 적응을 제공했습니다. 전통적인 기계 번역 모델을 GPT-3와 같은 더 큰 모델로 대체하는 것은 높은 계산 비용과 비유적이지 않은 담론에서의 한계 수익 감소 때문에 편리하지 않지만, GPT-3는 제안 제공, 잠재적 실수 식별 및 개선 기회 발견에 있어 강력한 인간의 동반자가 될 수 있습니다.
기계 번역 엔진이 "거의" 도달했음에도 불구하고, 이 "거의"는 여기 GPT에 의해 입증된 것처럼 점점 더 다루기 어려워집니다.
어떤 엔진도 인간을 대체할 만큼 신뢰할 수 없지만(적어도 이 연구의 맥락에서는), GPT는 인간 번역가와 검토자가 언어를 번역하고 평가하는 과정에서 도움을 줄 수 있는 명확한 능력을 보여줍니다.
GPT는 독일어 관용구에서 모든 MT 엔진을 30% 능가했습니다
다음 분석은 저희 영어/독일어 언어학자 Olga Schneider에 의해 작성되었습니다.

전반적으로 GPT는 가장 정확한 번역을 생성했습니다. 항상 영어 문장을 정확하게 분석하고 기계 번역이 직역인지 관용적인지 보통 알 수 있었지만, 오역을 50%의 확률로 감지하지 못했습니다.
정성적 관점에서의 출력
아래 표는 우리 언어학자 팀이 수행한 10개의 영어 관용구 문장을 독일어로 번역한 합성 분석을 보여줍니다.

GPT는 첫 번째 시도에서 10번 중 8번, 두 번째 시도에서 10번 중 7번에서 좋은 결과를 생성합니다. 예를 들어, GPT만이 "I'm head over heels for him"과 "Hit me up"에 대한 정확한 관용적 번역을 제공할 수 있었습니다.
마지막으로, 가장 비유적인 출력은 4개의 좋은 문장을 생성했으며, 나머지는 적합하거나 "나는 울고 싶다"였습니다. 전반적으로 Amazon과 Microsoft는 Google보다 약간 더 나은 번역을 제공했습니다.
아래 표에는 원시 데이터 분석이 포함되어 있습니다.
GPTs 평가
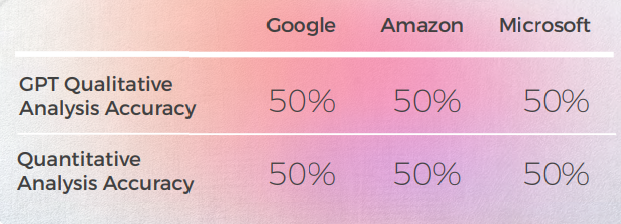
분석 및 키 찾기
- GPT는 독일어 관용구에 대해 상당히 좋은 지식을 가지고 있으며, 영어 문장과 완전히 일치하지 않는 것들도 유사한 범주의 관용구였습니다. 예를 들어: "플러그를 뽑자"와 "커튼을 내리자"를 "오늘은 여기까지 하자"로. "끝"과 관련된 이러한 문구의 일반적인 의미를 이해하고 유용한 영감의 원천이 될 수 있습니다.
- 창의적인 표현에 관해서, GPT는 영어 구문에서 영감을 얻는 것처럼 보이며, "I'm head over heels for him"에 대한 창의적인 대안으로 "I am in love with him from head to toe"의 독일어 직역을 제안합니다.
- GPT의 번역 등급은 적중하거나 빗나갔고 신뢰할 수 없는 것으로 판명되었습니다. 한 경우에는 Google 번역을 2로 평가했는데, 왜 1이 아니었는지 명확하지 않았습니다.
- 독일어와 영어는 많은 관용적 표현을 공유하므로 번역이 더 쉽습니다. 그러나 독일어에 이질적인 표현(예: "그들은 한 몸과 같은 존재" 또는 "식은 죽 먹기"라는 표현은 결국 문자 그대로 번역됩니다. 완두콩의 경우 번역 엔진과 달리 GPT는 "쌍"에 대한 표현을 제공해야 한다는 것을 이해했습니다. 그러나 그것이 제공한 표현은 정확하고 일반적으로 사용되지만 올바른 의미를 전달하지 못했습니다.
실용적인 적용 및 제한 사항
GPT는 Google, Amazon 및 Microsoft보다 더 나은 번역을 제공했습니다. 비록 100% 신뢰할 수는 없지만, 다른 세 엔진보다 기계 번역 편집을 위한 더 나은 시작점을 제공할 수 있습니다. 관용 표현이 중요하지만, 영어에서 독일어로의 기계 번역에서 자주 접하는 또 다른 문제는 원문에 너무 가까운 번거로운 문장 구조입니다. GPT가 이 문제를 어떻게 해결하는지 확인하는 것이 중요합니다.
평가와 관련하여, GPT는 독일어 번역 평가의 정확도가 50%에 불과하기 때문에 좋은 도구가 아닙니다.
세 가지 더 흥미로운 점이 있었을 것입니다.
- GPT는 독일어에서 DeepL과 경쟁할 수 있습니까? GPT가 좋은 번역을 제공할 수 있지만, DeepL은 좋은 독일어 번역을 제공하며 번역 과정을 단순화하는 다양한 기능을 제공합니다 (용어집 항목이 올바른 복수형과 격으로 번역되고, 한 번의 클릭으로 편집 가능하며, 한두 단어 입력 후 문장을 자동 완성하여 문장 재구성을 빠르게 할 수 있습니다). GPT의 번역은 기능 부족을 보완하기 위해 DeepL의 번역보다 훨씬 더 나아야 합니다.
- GPT의 정확도는 문구가 포함된 단락과 같은 더 많은 컨텍스트를 통해 향상될 수 있습니까?
- Google이 AI가 생성한 텍스트를 인식할 수 있다면, 최소한의 편집 또는 전혀 편집하지 않은 GPT 번역을 어떻게 처리할까요? "GPT 스타일"을 감지하고 검색 결과에서 텍스트에 불이익을 줄 수 있습니까?
요약하면, 현재 상태에서 GPT는 제한된 인간의 뇌에 영감의 원천이 될 수 있습니다. 괜찮은 번역을 제공할 수 있습니다. 그것보다 더, 그것은 우리가 남용된 표현을 바꾸고, 은유를 찾고, 고정관념을 깨는 데 도움을 줄 수 있습니다.
이탈리아어: 기계 번역 엔진은 70%의 경우에 직역을 반환했습니다
다음 분석은 저희 영어/이탈리아어 언어학자 엘비라 비앙코가 작성했습니다.

전반적으로 모든 엔진은 언어의 은유적 특성과 씨름했으며 종종 과도한 문자 그대로의 오류를 범했습니다.
정성적 관점에서의 출력
아래 표는 우리 언어학자 팀이 수행한 10개의 영어 관용구 문장을 이탈리아어로 번역한 합성 분석을 보여줍니다.
기계 번역은 올바른 의미와는 거리가 먼 직역을 제공했습니다. GPT는 70%에서 올바른 의미와 표현을 전달했으며, 나머지 30%는 널리 사용되지 않거나 자연스러운 원어민처럼 인식되지 않는 허용 가능한 표현을 사용했습니다.
아래 표에는 원시 데이터 분석이 포함되어 있습니다.
GPTs 평가

분석 및 키 발견
- Google Translate는 적합한 번역을 하나만 찾고 2개의 문장에서 의미에 근접합니다.
- Amazon은 이탈리아어로 영어 표현을 전달하는 가장 일반적인 방법을 사용하지 않더라도 50%의 적합한 의미를 제공했습니다.
- Microsoft는 이탈리아의 유사한 속담에 더 가까워지며 3개의 적합한 답변을 제공했습니다.
- 1st Chat GPT는 보통 기계 번역을 승인하지만, 2nd와 3rd Chat GPT는 보통 올바른 의미를 제공하고 가치 있는 번역 제안을 추가합니다.
실제 적용 및 제한 사항
https://it.wiktionary.org/wiki/espressione_idiomatica에 의해 정의된 대로, 언어의 전형적인 관용적 표현은 번역되는 언어의 관용적 표현과 유사한 의미로 번역되는 경우를 제외하고는 일반적으로 문자 그대로 다른 언어로 번역할 수 없습니다. 오늘날 가장 많이 사용되는 번역 기계(구글, 아마존, 마이크로소프트)에 의해 생성된 기계 번역은 명백히 신뢰할 수 없었지만, GPT-3는 70%의 확률로 적합한 의미를 제공하고 콘텐츠 적응에 좋은 제안을 제공할 수 있음을 입증했습니다.
가까운 미래에 기계가 관용구도 기억할 가능성이 없지 않지만, 적합 지금은 한 언어에서 다른 언어로 동일한 의미를 전달하기 위해 인간이 번역해야 합니다.
언어는 뉘앙스, 이중 의미, 암시, 관용구, 은유로 가득 차 있으며 인간만이 인식할 수 있습니다.
모든 엔진 테스트에서 한국어의 정확도가 가장 낮았습니다
다음 분석은 저희 영어/한국어 언어학자 김선민이 작성했습니다.

질적 관점에서의 결과
아래 표는 우리 언어학자 팀이 수행한 10개의 영어 관용구 문장을 한국어로 번역한 종합 분석을 보여줍니다.
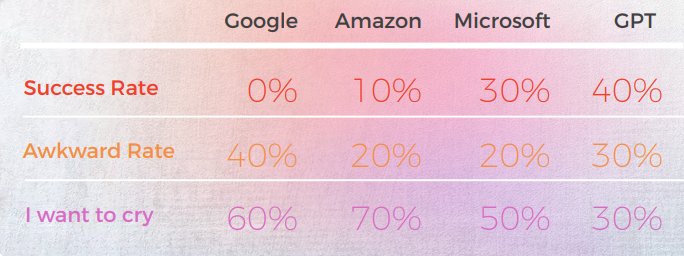
대부분의 엔진은 관용구를 문자 그대로 번역하는 반면, GPT는 은유 없이 가능한 한 설명적으로 번역하려고 합니다(예: piece of cake = easy). 한국에서는 Microsoft와 동일한 의미를 전달하는 유사한 관용적 표현이 있습니다.
GPT의 세 가지 번역은 일관성이 없습니다. 일부는 반복할수록 악화되고 있습니다.
아래 표에는 원시 데이터 분석이 포함되어 있습니다.
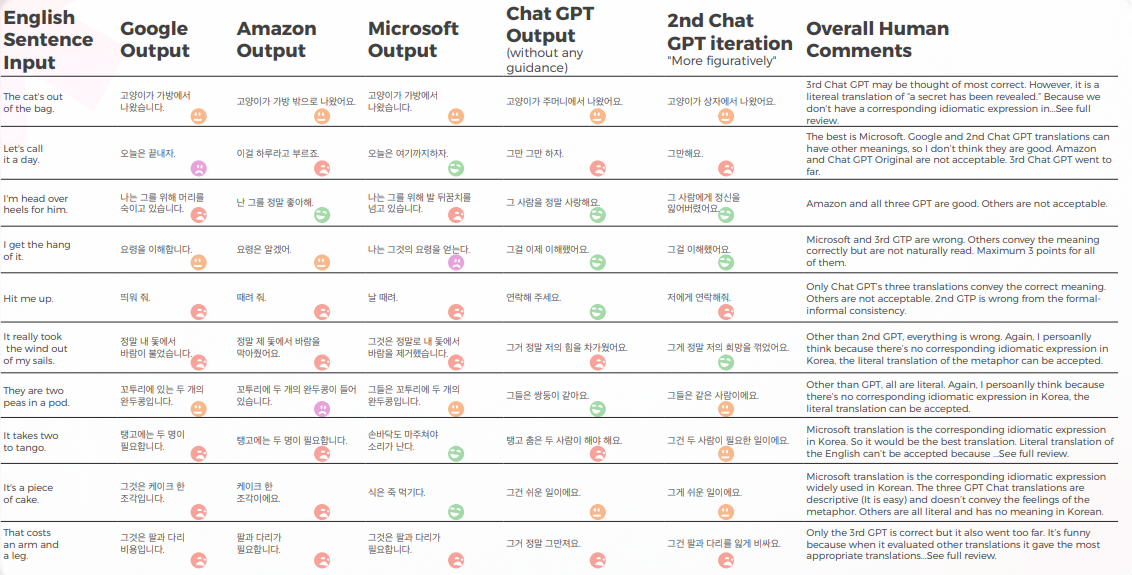
GPT는 번역이 잘못되었을 때 발생하는 문제를 알고 있습니다. 그러나 가장 좋은 것을 판단하는 데 있어 옳다고 간주되지 않습니다.
GPT 자체는 공식적 - 비공식적 대우 등과 관련된 문제를 가지고 있으며, 이 문제를 평가할 수 있습니다.
GPTs 평가의 평가

분석 및 키 찾기
이 연구의 영어 원문은 관용적 표현이기 때문에, 은유와 직접적인 설명 중에서 선택해야 하므로 약간 까다롭습니다. 하지만 한국어에 동일한 의미를 전달하는 유사한 관용 표현이 있는 경우를 제외하고, 대부분의 엔진은 그러한 표현을 찾기 못했습니다. 몇 가지 예외를 제외하고는 말이죠 (워크시트를 참조하고 제가 5점을 준 것들을 찾기 바랍니다). 다른 경우에는, 제 개인적인 생각으로는 은유 자체가 의미를 전달할 수 있다면, 그것을 직역하는 것이 고려될 수 있으며, 아마도 설명적인 단어를 사용하는 것이 더 나을 수 있습니다. 물론, 그 은유가 한국에서 문화적 맥락을 가지고 있지 않다면, 그것을 문자 그대로 번역해서는 안 된다. 하지만 그것은 미묘한 문제이며 아마도 번역가의 선호나 인간의 감정에 달려 있을 수 있습니다. 아직 어떤 엔진도 인간과 같은 수준의 사고를 가지고 있지 않다고 생각합니다.
실제 적용 및 제한 사항
대부분의 엔진은 번역 전 목적으로 사용할 수 있다고 생각합니다. 하지만 품질을 고려할 때, 이는 주로 효율성을 위한 목적으로만 사용되어야 합니다 (즉, 처음부터 타이핑하지 않는다는 의미입니다). 매뉴얼과 같은 더 설명적인 텍스트의 경우, MTPE가 이러한 관용적 표현보다 훨씬 더 발전했다고 봅니다. 따라서 여전히 개선의 여지가 있습니다.
GPT는 브라질 포르투갈어 관용구에서 90%의 성공률을 기록했습니다
다음 분석은 저희 영어/포르투갈어 언어학자 Gabriel Fairman에 의해 작성되었습니다.

전반적으로 모든 엔진은 언어의 은유적 특성과 씨름했으며 종종 과도한 문자 그대로의 오류를 범했습니다.
질적 관점에서의 출력
아래 표는 우리 언어학자 팀이 수행한 10개의 영어 관용구 문장을 포르투갈어로 번역한 종합 분석을 보여줍니다.
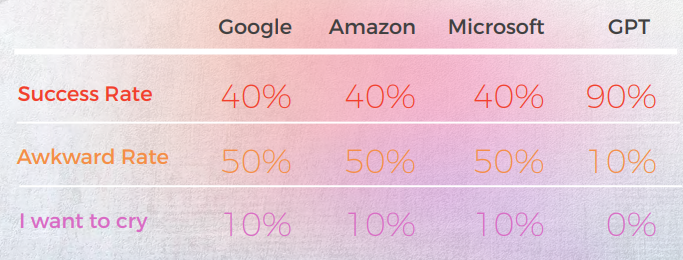
대부분의 엔진은 관용구를 문자 그대로 번역하는 반면, GPT는 은유 없이 가능한 한 설명적으로 번역하려고 합니다(예: piece of cake = easy). 한국에서는 Microsoft와 동일한 의미를 전달하는 유사한 관용적 표현이 있습니다.
GPT의 세 가지 번역은 일관성이 없습니다. 일부는 반복할수록 악화되고 있습니다.
아래 표에는 원시 데이터 분석이 포함되어 있습니다.
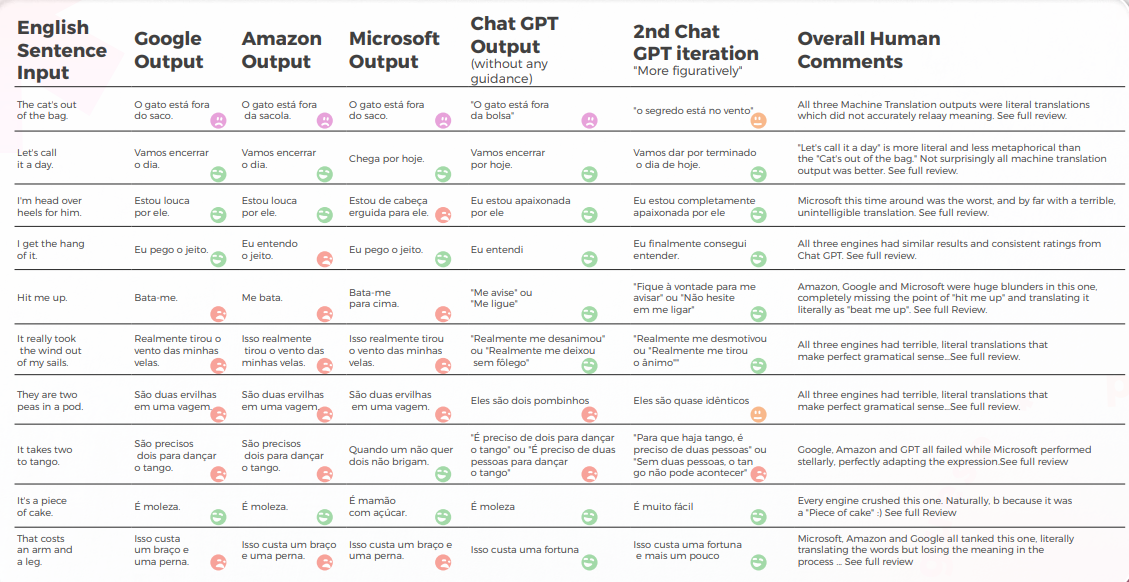
번역 품질에 관해서는, GPT가 맥락화에서 훌륭한 작업을 했습니다. 10개의 문장 중 9개에서, 콘텐츠는 잘 적응되었고, 이해 가능하며, 적절한 의미를 전달했습니다. 세 개의 기계 번역 엔진과 달리, GPT는 당황스러운 "I want to cry" 실수를 하지 않았습니다.
초기 가설은 GPT의 첫 번째와 두 번째 반복 사이에 품질의 큰 차이가 있을 것이라는 것이었지만, 번역 품질은 둘 다 비슷했습니다.
GPTs 평가의 평가
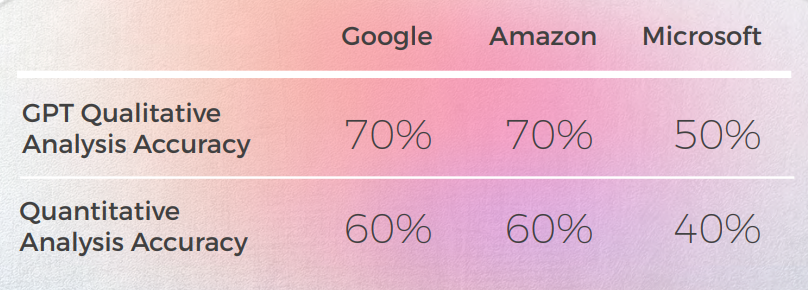
분석 및 키 발견
- Microsoft는 관용구의 언어적 적응에 있어 더 대담한 선택을 했습니다.
- GPT는 Microsoft의 은유적 선택이 더 많이 벗어남에 따라 평가하기가 더 어려웠습니다.
- 구글과 아마존은 매우 유사한 결과를 보였으며, 서로의 실수와 은유적 선택을 반영하여 약간만 벗어났습니다. Microsoft는 분명히 둘 중에서 두드러졌습니다.
- GPT-3는 정성적 분석을 통해 설득력 있는 텍스트 분석을 생성하는 데 더 수월했습니다(정확도가 70%에 불과함).
- GPT의 분석은 이해할 수 있지만 사례의 30%에서 식별에 실패했습니다. 이것은 문자 그대로이고 이해할 수 있지만 일상적인 담론에서 벗어난 은유적 선택과 일치했습니다.
- GPT-3는 정성적 분석을 점수로 변환하는 데 어려움을 겪었습니다.
- 대체로 점수의 정확도는 60%였지만 3점과 4점과 같은 유사한 점수를 구별하기가 어려웠습니다.
- 1에서 5까지의 극단적인 점수 차이는 이해하기 쉬웠고 다음을 제안하는 전반적인 의견과 더 잘 맞았습니다.
- 아마도 채점 기준이 GPT-3으로 충분히 보정되지 않았을 수 있습니다
- 아마도 이진 채점이 그라디언트 채점보다 더 관련성이 있을 수 있습니다. 한 가지 변칙적인 사례에서 Cchat GPT-3은 두 개의 유사한 번역을 근본적으로 다른 방식으로 평가하여, 둘 다 1이어야 할 때 하나는 1로, 다른 하나는 5로 평가했습니다.
- 양적으로 Microsoft는 Google 및 Amazon과 유사한 성능을 보였지만, 언어의 세부 사항으로 들어가면 Microsoft는 더 대담한 선택을 하고 질적 관점에서 더 나은 결과를 제공했지만, 정확성과 문화적 적응 측면에서는 여전히 GPT-3에 비해 많이 뒤처져 있었습니다.
실용적인 응용 및 한계
이 분석에서 GPT-3는 이전의 브라질 포르투갈어
기계 번역 모델보다 우수한 맥락화 및 적응을 제공했습니다. 전통적인 기계 번역 모델을 GPT-3와 같은 더 큰 모델로 대체하는 것은 높은 계산 비용과 비유적이지 않은 담론에서의 한계 수익 감소 때문에 편리하지 않지만, GPT-3는 제안 제공, 잠재적 실수 식별 및 개선 기회 발견에 있어 강력한 인간의 동반자가 될 수 있습니다.
언어의 극단적인 사례들은 언어 모델에 관해서 얼마나 많은 것이 적은 것에 남아 있는지를 매우 명확하게 보여주기 때문에 놀랍습니다. 비록 그것들이 "거의" 거기에 있다 하더라도, 이 "거의"는 점점 더 다루기 어려워지고, 더 어렵지 않더라도 계산적인 관점에서 확실히 더 비용이 많이 듭니다.
어떤 엔진도 인간을 대체할 만큼 신뢰할 수 있는 것은 아니지만 (적어도 이 연구의 맥락에서는), GPT-3는 인간 번역가와 검토자가 언어를 번역하고 평가하는 과정에서 도움을 줄 수 있는 명확한 능력을 보여줍니다.
스페인어 MTs 30% 미만 점수—GPT가 명백한 승자
다음 분석은 영어/스페인어 언어학자 Nicolas Davila에 의해 작성되었습니다.

전반적으로 모든 엔진은 언어의 은유적 특성과 씨름했으며 종종 과도한 문자 그대로의 오류를 범했습니다.
정성적 관점에서의 출력
아래 표는 우리 언어학자 팀이 수행한 10개의 영어 관용구 문장을 스페인어로 번역한 합성 분석을 보여줍니다.

번역 품질에 관해서는, GPT가 수용할 만한 작업을 했으며 맥락화 측면에서 다른 것들보다 더 나았습니다. 10개의 문장 중 7개에서 콘텐츠는 이해하기 쉽고 잘 구성되어 있으며 적절한 의미를 전달했으며, 어색함과 "울고 싶다" 비율이 낮았습니다.
초기 가설은 GPT의 첫 번째와 이후 반복 간에 품질에 큰 차이가 있을 것이라는 것이었지만, 번역 품질은 모두 유사합니다. 2번째와 3번째 반복은 때때로 불필요한 것을 추가하여 어색한 비율을 약간 높입니다.
아래 표에는 원시 데이터 분석이 포함되어 있습니다.
GPTs 평가

분석 및 키 찾기
- MT 번역은 너무 직역적이었으며, 아마존과 구글은 일반적으로 매우 유사하고 마이크로소프트는 가장 나빴습니다.
- 구글과 아마존은 매우 유사한 결과를 보였으며, 서로의 실수와 은유적 선택을 반영하여 약간만 벗어났습니다. Microsoft는 저조한 성능을 보였으며 때로는 잘못 형성된 문장을 생성하고 문법 구성의 일부를 누락했습니다.
- GPT-3는 정확도가 50%에 불과함에도 불구하고 일관된 텍스트 분석을 생성하는 정성적 분석을 더 쉽게 수행할 수 있었습니다.
- GPT-3의 정성적 분석은 종종 너무 일반적이고 문장의 주요 및 문자 그대로의 의미에 더 국한되어, 구성의 미묘한 세부 사항과 의미의 변화를 고려하지 않았습니다. GPT는 이러한 차이를 포착하여 정량적 점수로 변환할 수 없는 것 같습니다.
- 또한 GPT는 문법적으로 잘못 구성된 문장에 동일한 정성적 분석과 높은 정량적 점수를 자주 할당했는데, 이는 GPT 모델의 한계인 것 같습니다.
- GPT-3는 정성적 분석을 점수로 변환하는 데 어려움을 겪었습니다.
- Google과 Amazon의 경우 50%만 정확하고 Microsoft의 경우 30%만 정확합니다. GPT는 문장이 의미를 전달하는지 여부만 측정한 것 같지만, 문장 구조나 형성에는 차이가 없었습니다.
- 1에서 5까지의 점수 차이는 이해하기 쉬웠고 다음을 제안하는 전반적인 의견과 더 잘 맞았습니다. 아마도 채점 기준이 GPT-3에 대해 충분히 보정되지 않았을 수 있습니다. 아마도 이진 채점이 그라디언트 채점보다 더 관련성이 있을 수 있습니다. 어쩌면 채점 기준이나 GPT 모델은 문법적 문제를 고려하지 않고 의미 전달에만 중점을 두었을 수 있습니다.
실용적인 응용 및 한계
이 분석에서 GPT-3는 Latam 스페인어에서 이전 기계 번역 모델보다 우수한 맥락화 및 적응을 제공했습니다.
GPT-3는 유용한 제안과 개선 기회를 제공할 때 번역을 개선하는 데 있어 인간을 돕는 강력한 도구가 될 수 있습니다. 그러나 내가 볼 수 있는 한, 여전히 특정 제한 사항이 있습니다.
GPT-3와 같은 더 큰 모델이 도움이 될 수 있지만, 기계 번역 모델을 전통적인 모델로 대체하는 것은 비유적이지 않은 텍스트의 경우 한계 이익을 감소시킬 수 있기 때문에 더 높은 계산 비용으로 인해 편리하지 않습니다.
GPT-3는 번역가와 검토자가 언어를 번역하고 평가하는 과정에서 도움을 줄 수 있는 명확한 능력을 보여주지만, 비유적이지 않은 텍스트에 대한 사용을 평가할 때 비용 고려 사항이 포함되어야 합니다.
결론
ChatGPT의 성능은 프롬프트와 특정 언어에 따라 달라질 수 있지만, 우리의 연구는 ChatGPT가 특히 관용적 표현과 미묘한 언어 사용을 처리할 때 전통적인 MT 엔진보다 더 높은 품질의 번역을 생성할 가능성이 있음을 시사합니다.
그러나 ChatGPT는 실수를 하지 않는 것과는 거리가 멀고, 특히 더 복잡한 프롬프트나 언어 영역과 관련하여 여전히 개선의 여지가 많다는 점에 유의하는 것이 중요합니다.
번역가로서 ChatGPT는 테스트된 모든 기계 번역 엔진보다 더 성공적이었습니다. 언어마다 다른 결과를 보였지만, 한국어는 MT 품질과 GPT 품질이 다른 언어들보다 현저히 낮아 명백한 아웃라이어였습니다.
한국어를 제외한 모든 언어에서 ChatGPT는 최소 70%에서 최대 90%의 성공률을 기록하며, 기존 기계 번역보다 더 나은 성능을 보였습니다. 한국어에서도 점수는 낮았지만, 여전히 MT 엔진 출력물보다는 더 나았습니다.
기계 번역과 달리, LLM을 사용하면 동일한 콘텐츠의 반복이 출력 품질을 향상시킬 수 있습니다. 통합을 생각할 때 이것은 키입니다. 전통적인 MT의 경우 출력이 항상 입력과 동일하지만(엔진이 추가 데이터나 훈련을 받지 않는 한), LLM을 사용하면 API를 통해 여러 상호작용을 탐색하여 피드 품질을 최적화할 수 있습니다.
기존 MT 엔진에 비해 ChatGPT의 장점 중 하나는 추가 학습 데이터 없이도 시간이 지남에 따라 학습하고 개선할 수 있다는 것입니다. 이는 새로운 입력을 기반으로 언어 모델을 지속적으로 개선하도록 설계된 LLM의 특성 때문입니다. 이와 같이, ChatGPT는 잠재적으로 더 적응적이고 역동적인 번역 기능을 제공할 수 있으며, 이는 언어나 콘텐츠가 지속적으로 발전하거나 변화하는 시나리오에서 특히 유용할 수 있습니다.
ChatGPT의 또 다른 장점은 낮은 움찔거림률로, 이는 종종 어색하거나 부적절한 번역을 생성하는 기존 MT 엔진에 비해 크게 개선된 것입니다. 이것은 비전문 사용자에게 ChatGPT를 더 수용 가능하고 사용자 친화적으로 만들 수 있습니다. 이들은 전문 번역가와 같은 수준의 언어적 또는 문화적 지식을 가지고 있지 않을 수 있습니다.
그러나 ChatGPT는 인간 번역가를 대체할 수 없으며, 인간 번역가의 전문성과 판단이 필요한 수많은 경우가 있다는 점을 주목하는 것이 중요합니다. 그러나 ChatGPT의 현저히 낮은 소름 끼치는 비율은 비인간 주도 번역의 광범위한 채택을 위한 문을 열어줍니다.
평가자로서 ChatGPT의 성능은 정확도가 30%에서 70% 사이로 더 엇갈렸습니다. 이것은 ChatGPT가 번역을 제안하는 데 비해 다른 번역 엔진을 평가하는 데 그다지 효과적이지 않을 수 있음을 시사하지만, 이는 평가 프롬프트의 복잡성과 품질 때문일 수 있으며, 이는 ChatGPT가 현재 보유한 것보다 더 전문적이거나 맥락적인 지식을 필요로 할 수 있습니다. ChatGPT의 평가자로서의 잠재력과 그 한계 및 도전 과제를 탐구하기 위해 추가 연구가 필요합니다.전반적으로 우리의 연구는 ChatGPT가 더 탐구할 가치가 있는 유망한 번역 기능을 가지고 있음을 시사합니다. 비록 인간 번역가를 전체적으로 대체하거나 우회할 수는 없지만, 특히 시간, 자원 또는 전문 지식이 제한된 상황에서 보조 도구나 사전 번역 도구로서 상당한 이점을 제공할 수 있습니다.
모든 신기술과 마찬가지로 여전히 많은 도전과 개선의 기회가 있으며, 잠재력을 완전히 발휘하기 위해서는 추가적인 연구와 실험이 필요할 것입니다.
방법론
GPT-3와 같은 언어 모델이 전통적인 기계 번역 엔진과 비교하여 관용적 번역을 어떻게 처리하는지 탐구하기 위해, 우리는 은유와 관용 표현을 포함한 언어학적 극단 사례에 초점을 맞춘 실험을 수행했습니다.
관용 표현 선택
“Let’s call it a day,” “Hit me up,” “The CAT’s out of the bag.”와 같은 일반적으로 사용되는 영어 관용구 10개를 선택했습니다. 이러한 표현들은 번역 시스템에 도전적인 것으로 잘 알려져 있으며, 이는 문자 그대로의 동등성보다는 문화적 및 맥락적 적응을 필요로 하기 때문입니다.
테스트된 번역 엔진 및 모델
각 관용구는 다음을 사용하여 번역되었습니다.
- Google Translate
- Amazon Translate
- Microsoft 번역가
- GPT-3 (ChatGPT) – 두 가지 접근 방식 사용:
- 어떠한 지침 없이 직접 번역
- 더 비유적이고 관용적으로 번역된 두 번째 버전

평가 과정
번역된 결과물은 7개의 대상 언어에 걸쳐 원어민 언어학자들에 의해 검토되었습니다: 포르투갈어(브라질), 스페인어, 프랑스어, 독일어, 이탈리아어, 중국어, 한국어. 각 문장에 대해 검토자들은 평가했습니다.
- 원래 관용구의 의미가 보존되었는지 여부
- 대상 언어 표현의 자연스러움
- 문법, 구문 및 의미론적 정확성
각 번역은 1에서 5까지의 척도로 평가되었습니다:
- 5: 올바른 의미와 자연스럽게 들리는 언어
- 1: 부정확하거나 혼란스럽거나 부자연스러운 번역("울고 싶어" 수준)
또한 ChatGPT에 질적 텍스트 피드백과 수치 점수를 제공하여 다른 엔진의 번역을 평가하도록 요청했습니다. 이를 통해 번역 생성기로서뿐만 아니라 평가자로서의 능력을 평가할 수 있었습니다.
연구의 한계
이 연구는 탐색적 연구였다는 점에 유의하는 것이 중요합니다.
- 샘플은 10개의 관용구로 제한되었으며 언어당 한 명의 인간 검토자가 있었습니다.
- 모든 평가에는 어느 정도의 주관성과 개인 선호도가 있습니다.
- GPT-3의 성능은 모델의 특정 버전을 반영하며 업데이트와 함께 발전할 수 있습니다.
이러한 제약에도 불구하고, 이 발견은 특히 언어적으로 미묘하고 문화적으로 의존적인 시나리오에서 현재 모델의 능력과 한계에 대한 귀중한 통찰력을 제공합니다.
면책 조항
(실제 연구 면책 조항은 가볍게 받아들이지 마세요)
ChatGPT의 언어 능력의 잠재력을 탐구하려고 했지만, 이 연구는 번역의 한 측면, 즉 언어학적 관용적이고 매우 은유적인 극단적인 사례를 처리하는 능력만을 평가했다는 점을 유의하는 것이 중요합니다. 번역의 다른 측면, 예를 들어 문화적 및 맥락적 이해는 다른 평가 방법과 기준이 필요할 수 있습니다.
이 연구의 표본 크기는 10개의 관용구와 언어당 한 명의 리뷰어로 제한되어 있으며, 이는 영어의 전체 관용 표현 범위나 전문 번역가의 다양한 관점과 전문성을 대표하지 않을 수 있습니다. 따라서 본 연구의 결과는 신중하게 해석되어야 하며 다른 맥락이나 영역으로 일반화되어서는 안 된다.
또한 언어별 단일 검토자의 의견과 평가는 주관적이며 개인적인 편견, 경험 또는 선호도의 영향을 받을 수 있습니다. 모든 주관적 평가와 마찬가지로 결과에는 어느 정도의 변동성과 불확실성이 있습니다. 우리의 발견의 신뢰성과 타당성을 높이기 위해, 향후 연구에서는 여러 검토자, 블라인드 평가 또는 평가자 간 신뢰도 측정을 포함할 수 있습니다.
ChatGPT의 언어 기능은 정적이지 않으며, 모델이 추가로 훈련되고 미세 조정됨에 따라 시간이 지남에 따라 변경될 수 있다는 점도 주목할 가치가 있습니다. 따라서 이 연구의 결과는 특정 시점의 모델 성능에 대한 스냅샷으로 간주되어야 하며 현재 또는 미래의 기능을 반영하지 않을 수 있습니다.
마지막으로, 이 연구는 번역을 위한 ChatGPT의 유용성 또는 한계에 대해 확정적이거나 범주적인 주장을 하려는 것이 아닙니다. 오히려, 이는 자연어 처리 및 기계 번역 분야에서의 향후 연구 및 개발을 위한 예비 조사 및 출발점으로 사용되기 위한 것입니다. 모든 신기술과 마찬가지로, 여전히 많은 도전과 개선의 기회가 있으며, 그 잠재력을 완전히 탐구하기 위해서는 추가적인 실험과 협업이 필요합니다.








