Testamos o Chat GPT para tradução – aqui estão os dados


Todo mundo está falando sobre como a IA está transformando a tradução — mas será que ela consegue realmente lidar com as nuances da linguagem humana?
Pesquisas recentes da Bureau Works colocaram isso à prova, comparando o GPT-3 com os principais motores de tradução de máquina do Google, Amazon e Microsoft. O estudo se concentrou em um dos desafios mais difíceis da localização: expressões idiomáticas. Por quê? Porque traduções literais não funcionam quando você está lidando com frases como “The CAT’s out of the bag” ou “Let’s call it a day.”
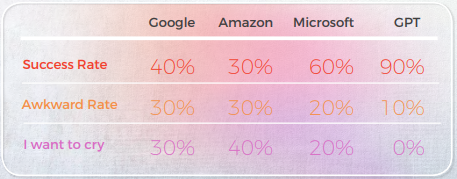
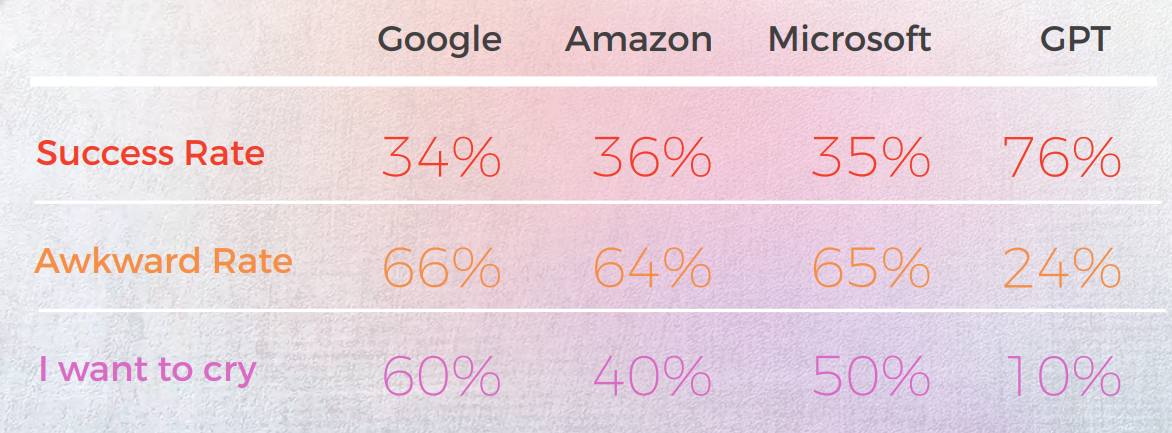
Os resultados foram surpreendentes. O GPT-3 forneceu traduções precisas e com som natural em até 90% das vezes, enquanto os motores tradicionais oscilavam entre 20% e 50% — e muitas vezes produziam resultados constrangedores classificados como "Quero chorar" por linguistas nativos.
Em um mundo onde as nuances linguísticas podem fazer ou quebrar sua mensagem, essas descobertas destacam tanto a promessa quanto as limitações atuais da IA na tradução profissional.
Aqui está um resumo de nossas principais descobertas:
- O GPT-3 superou consistentemente os mecanismos tradicionais de MT (Google, Amazon, Microsoft) no tratamento de expressões idiomáticas — atingindo até 90% de precisão em idiomas como português e chinês.
- Os motores tradicionais tinham dificuldades com metáforas e linguagem figurativa, muitas vezes entregando traduções literais que eram gramaticalmente corretas, mas semanticamente incorretas — algumas até recebendo classificações de "eu quero chorar" de revisores nativos.
- A Microsoft assumiu mais riscos, oferecendo traduções mais ousadas que às vezes se desviavam do original, mas pareciam mais naturais – embora o GPT tivesse mais dificuldade em avaliar essas escolhas criativas.
- A análise qualitativa do GPT foi forte, mas teve dificuldade para atribuir pontuações numéricas consistentes, especialmente ao diferenciar entre classificações intermediárias como 3 vs. 4.
- Em quase todos os idiomas, a segunda iteração do GPT — quando solicitada a uma versão mais figurativa — melhorou a clareza, o tom e o ajuste cultural.
- O coreano foi o idioma mais desafiador, tanto para MTs tradicionais quanto para o GPT-3, mostrando um desempenho significativamente menor em todos os aspectos.
- O GPT-3 provou ser valioso não apenas como tradutor, mas também como ferramenta de avaliação e revisão, ajudando a sinalizar frases estranhas ou imprecisas e oferecendo alternativas.
O GPT alcançou 90% de precisão em expressões idiomáticas chinesas - MTs tiveram dificuldades
A análise a seguir foi escrita por nosso linguista inglês/chinês James Hou.

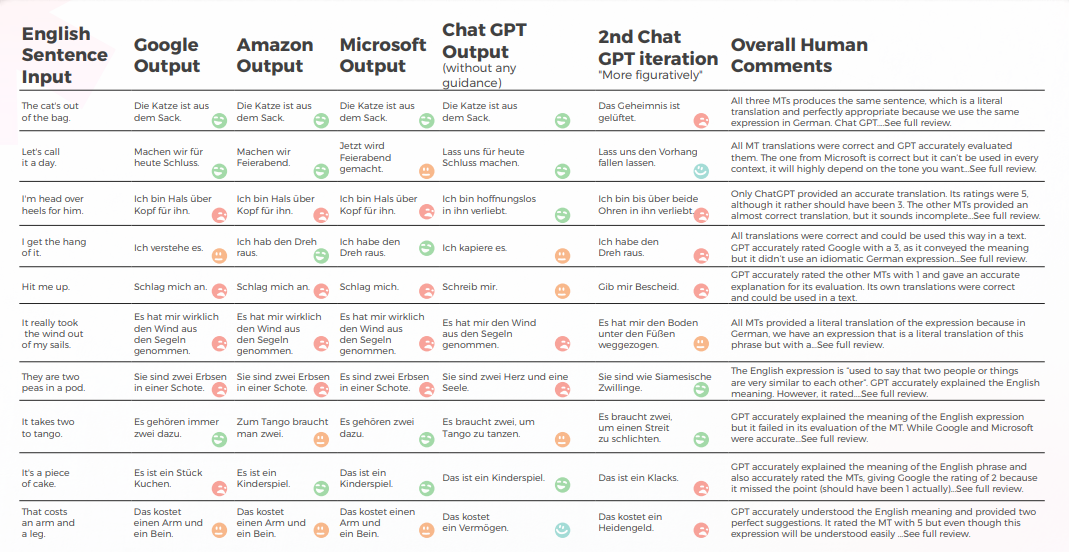
No geral, todos os motores tiveram dificuldades com a natureza metafórica da linguagem, muitas vezes errando na literalidade excessiva. Por exemplo, a tradução "Vamos chamar isso de um dia."" é uma tradução mais literal e um tanto estranha de "Vamos encerrar o dia". Ele transmite o significado da frase original, mas a redação é um pouco estranha e pode não ser tão fácil para os falantes nativos de chinês entenderem.
Embora transmita com precisão o significado da frase original, a redação é um pouco estranha e pode ser menos clara para falantes nativos.
Saída de uma perspectiva qualitativa
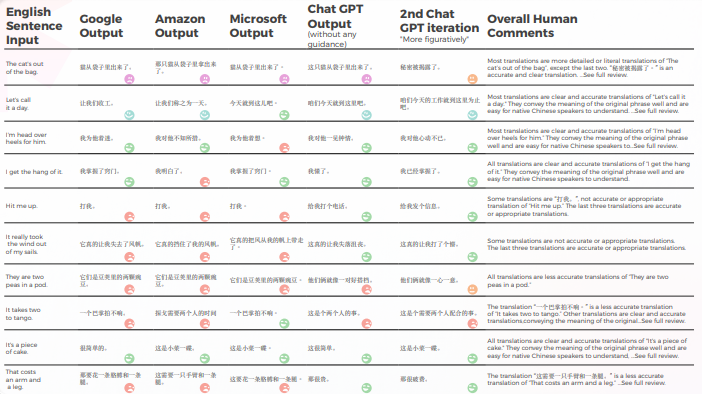
A tabela abaixo apresenta uma análise sintética de 10 frases idiomáticas em inglês traduzidas para o chinês, conduzida por nossa equipe de linguistas.
No que diz respeito à qualidade da tradução, o GPT fez um ótimo trabalho com contextualização. Por exemplo, "o segredo foi revelado"."é uma tradução precisa e clara para 'The CAT’s out of the bag'." Em 9 de 10 frases, o conteúdo foi bem adaptado, inteligível e transmitiu o significado adequado. Ao contrário dos três motores de tradução de máquina, o GPT não cometeu erros embaraçosos de "quero chorar".
A tabela abaixo contém a análise de dados brutos.
Avaliação da Avaliação dos GPTs
Análise e Principais Descobertas
- Google e Amazon tiveram resultados extremamente semelhantes, apenas ligeiramente se desviando um do outro, refletindo os erros e escolhas metafóricas um do outro. Por exemplo, a tradução "打我"." não é uma tradução precisa ou apropriada de "Hit me up". A frase "Hit me up" significa entrar em contato com alguém, normalmente por telefone ou mensagem de texto. A frase chinesa "打我" significa "me acerte" e não transmite o significado da frase original.
- A Microsoft fez escolhas mais ousadas quando se trata da adaptação linguística das expressões idiomáticas.
- O GPT teve mais dificuldade em avaliar as escolhas metafóricas da Microsoft à medida que se afastavam mais.
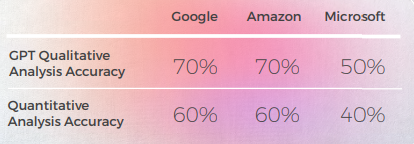
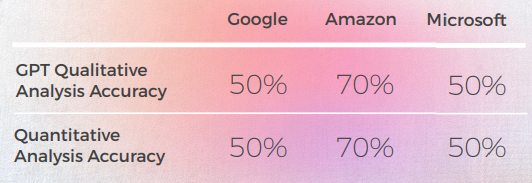
- O GPT-3 teve mais facilidade com a Análise Qualitativa, produzindo uma análise textual convincente (embora com apenas 70% de precisão).
- Embora inteligível, a análise do GPT não conseguiu identificar em 30% dos casos. Isso coincidiu com escolhas metafóricas que eram literais e compreensíveis, mas se desviavam do discurso cotidiano.
- O GPT-3 teve mais dificuldade em traduzir a análise qualitativa em uma pontuação. Embora as pontuações em termos gerais fossem 60% precisas, era difícil diferenciar entre pontuações semelhantes, como 3 vs. 4.
- A divergência extrema de pontuação de 1 a 5 foi mais fácil de entender e mais compatível com os comentários gerais sugerindo que:
- Talvez os critérios de pontuação não tenham sido suficientemente calibrados com o GPT-3
- Talvez a pontuação binária possa ser mais relevante do que a pontuação de gradiente
- • Embora quantitativamente a Microsoft tenha tido um desempenho semelhante ao Google e à Amazon, quando você entra nos detalhes da linguagem, a Microsoft fez escolhas mais ousadas e forneceu melhores resultados de uma perspectiva qualitativa, mas ainda estava muito atrás do GPT-3 quando se tratava de precisão e adaptação cultural. Por exemplo, a tradução "Eu peguei o jeito."" é uma tradução clara e precisa de "Eu pego o jeito". Ele transmite bem o significado da frase original e é fácil para os falantes nativos de chinês entenderem. É também uma maneira mais figurativa e idiomática de expressar o conceito de entender ou dominar algo em comparação com outras possíveis traduções.
Aplicações práticas e limitações
Nesta análise, o GPT-3 forneceu contextualização e adaptação superiores em comparação com modelos anteriores de tradução de máquina.
Embora nenhum dos mecanismos seja confiável o suficiente para substituir os humanos (pelo menos no contexto deste estudo), o GPT-3 mostra uma capacidade clara de auxiliar tradutores e revisores humanos no processo de tradução e avaliação da linguagem.
Francês: Os mecanismos de MT falharam em 60% das expressões idiomáticas - o GPT se destacou
A análise a seguir foi escrita por nossa linguista de inglês/francês Laurène Bérard.

No geral, todos os motores tiveram dificuldades com a natureza metafórica da linguagem, muitas vezes errando na literalidade excessiva.
Saída de uma perspectiva qualitativa
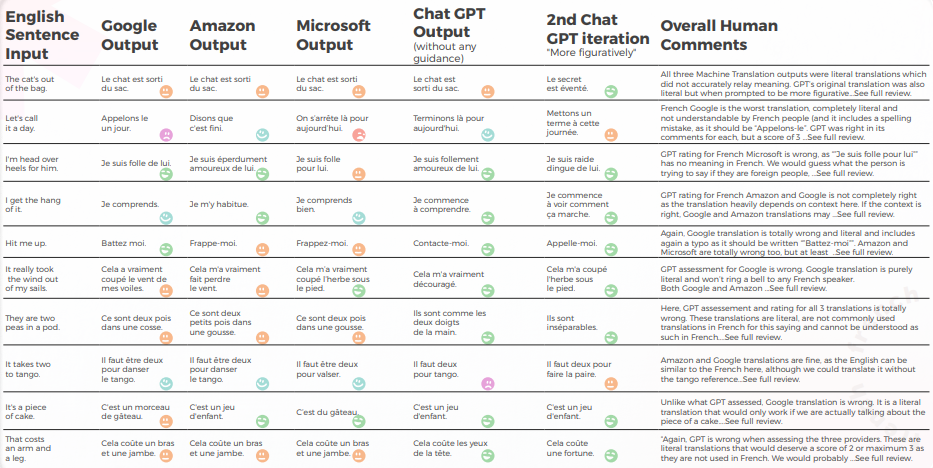
A tabela abaixo apresenta uma análise sintética de 10 frases idiomáticas em inglês traduzidas para o francês, conduzida por nossa equipe de linguistas.

No que diz respeito à qualidade da tradução, o GPT fez um ótimo trabalho com contextualização. Sem qualquer orientação, o GPT estava totalmente errado para “The CAT’s out of the bag”, mas estava certo com mais orientação, e suas 3 traduções estavam gramaticalmente incompletas, portanto, bastante difíceis de entender para “It takes two to tango”.
O conteúdo foi geralmente bem adaptado, inteligível e transmitiu o significado apropriado. Os três motores de tradução de máquina tiveram uma alta taxa de "quero chorar", enquanto mesmo sem contexto um tradutor teria adivinhado que não era para ser interpretado literalmente (por exemplo, "Vamos encerrar o dia", o que é bastante óbvio, mas foi totalmente mal interpretado pelo mecanismo do Google).
A tabela abaixo contém a análise de dados brutos.
Avaliação da Avaliação dos GPTs
Análise e Principais Descobertas
- Apesar de traduzir corretamente 8 em cada 10 vezes, a análise dos 3 mecanismos pelo GPT estava frequentemente errada, pois quase 50% dos casos afirmavam que sua tradução estava boa, enquanto não estava.
- Embora a análise inteligível do GPT não tenha identificado problemas em 30 a 50% dos casos, isso coincidiu com escolhas que eram literais e teriam sido corretas se não lidassem com expressões idiomáticas.
- O GPT não conseguiu identificar os dois problemas de ortografia do Google ("Appelons le" e "Battez moi").
- As análises qualitativas e quantitativas do GPT foram globalmente consistentes entre si.
- O GPT teve mais dificuldade em avaliar as traduções da Microsoft e do Google.
- A Microsoft fez escolhas melhores quando se trata da adaptação linguística das expressões idiomáticas.
- O Google e a Amazon tiveram resultados muito semelhantes, apenas ligeiramente divergentes entre si. A Microsoft se destacou dos dois.
- Em um caso (a expressão tango), o GPT avaliou uma boa tradução da Microsoft como errada (pontuação de 2), embora fosse compreensível e tão boa quanto as traduções do Google e da Amazon, que o GPT avaliou positivamente (pontuação de 5). Isso pode ser explicado pelo fato de que a Microsoft não foi tão literal quanto os outros dois mecanismos, pois escolheu mencionar valsa em vez de tango.
- A Microsoft fez escolhas mais ousadas e forneceu melhores resultados do ponto de vista qualitativo, mas ainda estava muito atrás do GPT quando se tratava de precisão e adaptação cultural.
Aplicações práticas e limitações
Nesta análise, o GPT forneceu uma contextualização e adaptação muito melhores do que os motores de tradução de máquina da Amazon, Google e Microsoft. Embora não seja conveniente substituir modelos tradicionais de tradução de máquina por modelos maiores, como o GPT-3, devido aos altos custos computacionais e aos ganhos marginais decrescentes quando se trata de discurso não metafórico, o GPT-3 pode ser um poderoso aliado humano ao fornecer sugestões e identificar possíveis erros, bem como oportunidades de melhoria.
Mesmo que os motores de tradução de máquina estejam "quase" lá, esse "quase" se torna progressivamente mais difícil de lidar, como provado pelo GPT aqui.
Embora nenhum dos mecanismos seja confiável o suficiente para substituir os humanos (pelo menos no contexto deste estudo), o GPT mostra uma capacidade clara de auxiliar tradutores e revisores humanos no processo de tradução e avaliação do idioma.
O GPT superou todos os mecanismos de MT em expressões idiomáticas alemãs em 30%
A análise a seguir foi escrita por nossa linguista de inglês/alemão Olga Schneider.

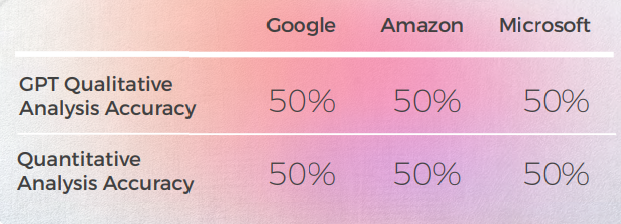
No geral, o GPT produziu a tradução mais precisa. Sempre analisava a sentença em inglês com precisão e geralmente conseguia dizer se uma tradução de máquina era literal ou idiomática, mas falhava em detectar uma tradução incorreta 50% das vezes.
Saída de uma perspectiva qualitativa
A tabela abaixo apresenta uma análise sintética de 10 frases idiomáticas em inglês traduzidas para o alemão, conforme conduzido por nossa equipe de linguistas.

O GPT produz bons resultados 8 em cada 10 vezes na primeira tentativa e 7 em cada 10 vezes na segunda tentativa. Por exemplo, apenas o GPT foi capaz de fornecer traduções idiomáticas precisas para "Estou perdidamente apaixonada por ele" e "Me chama".
A última e mais figurativa saída produziu 4 boas frases, com as outras sendo tudo bem ou "Eu quero chorar". No geral, a Amazon e a Microsoft produziram traduções ligeiramente melhores do que o Google.
A tabela abaixo contém a análise de dados brutos.
Avaliação da Avaliação dos GPTs
Análise e Principais Descobertas
- GPT tem um conhecimento bastante bom de expressões idiomáticas alemãs, mesmo aquelas que não correspondiam exatamente à frase em inglês eram expressões idiomáticas de uma categoria semelhante. Por exemplo: "Vamos puxar o plugue" e "Vamos baixar a cortina" para "Vamos encerrar o dia". Ele entende o significado geral dessas frases relacionadas ao "final" e pode ser uma fonte útil de inspiração.
- Quando se trata de expressões criativas, o GPT parece se inspirar em frases em inglês, sugerindo a tradução literal em alemão de "Estou apaixonado por ele da cabeça aos pés" como uma alternativa criativa para "Estou perdidamente apaixonado por ele".As classificações de tradução dos GPTs foram inconsistentes e se mostraram pouco confiáveis. Em um caso, avaliou uma tradução do Google como 2, e não ficou claro por que não era o 1 que deveria ter sido.
- O alemão e o inglês compartilham muitas expressões idiomáticas, o que facilita a tradução. Mas expressões que são estranhas ao alemão (por exemplo, "São duas ervilhas em uma vagem" ou "É moleza") acabam sendo traduzidos literalmente. No caso das ervilhas, ao contrário dos motores de tradução, o GPT entendeu que precisava fornecer expressões sobre "pares". No entanto, as expressões que forneceu - embora precisas e comumente usadas - não transmitiam o significado correto.
Aplicações práticas e limitações
GPT forneceu traduções melhores do que Google, Amazon e Microsoft. Embora não seja 100% confiável, pode fornecer um ponto de partida melhor para a edição de tradução de máquina do que os outros três motores. Embora expressões idiomáticas sejam importantes, há outro problema frequentemente encontrado na tradução de máquina de texto em inglês para alemão: uma estrutura de sentença complicada que é muito próxima do texto original. Seria importante ver como o GPT resolve esse problema.
Quando se trata de avaliação, o GPT não é uma boa ferramenta, pois sua avaliação das traduções para o alemão é apenas 50% precisa.
Mais três coisas teriam sido interessantes de ver:
- O GPT pode competir com o DeepL para o alemão? Embora o GPT possa fornecer boas traduções, o DeepL produz boas traduções para o alemão e também oferece uma variedade de recursos que simplificam o processo de tradução (termos do glossário traduzidos corretamente com o plural e o caso corretos, edição com um clique, preenchimento automático de frases após digitar uma ou duas palavras para acelerar a reformulação). A tradução do GPT precisa ser significativamente melhor do que a do DeepL para compensar a falta de recursos.
- A precisão do GPT poderia ser melhorada com mais contexto, como um parágrafo contendo a frase?
- Se o Google for capaz de reconhecer texto gerado por IA, como ele lidará com as traduções GPT com o mínimo ou nenhuma edição? Ele consegue detectar o "estilo GPT" e penalizar um texto em seus resultados de pesquisa?
Em resumo, em seu estado atual, o GPT pode ser uma fonte de inspiração para nossos cérebros humanos limitados. Ele pode fornecer traduções decentes. Mais do que isso, pode nos ajudar a reformular expressões usadas em excesso, encontrar metáforas e pensar fora da caixa.
Italiano: A MT Engines retornou traduções literais em 70% dos casos
A análise a seguir foi escrita por nossa linguista inglesa/italiana Elvira Bianco.

No geral, todos os motores tiveram dificuldades com a natureza metafórica da linguagem, muitas vezes errando na literalidade excessiva.
Saída de uma perspectiva qualitativa
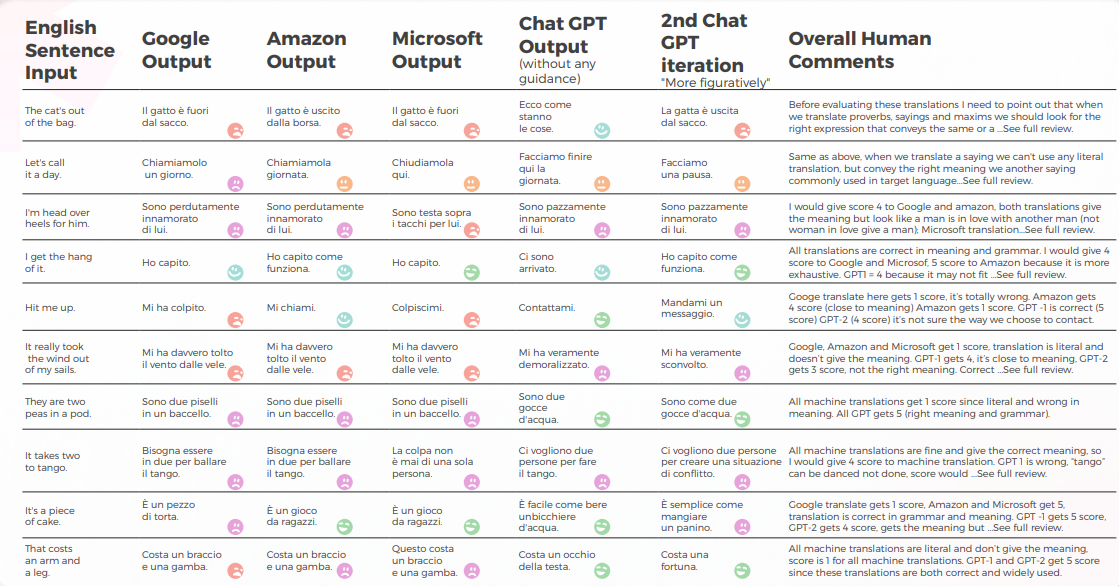
A tabela abaixo apresenta uma análise sintética de 10 frases idiomáticas em inglês traduzidas para o italiano, conforme conduzido por nossa equipe de linguistas.
A tradução de máquina deu uma tradução literal muito distante do significado correto. O GPT transmitiu o significado e a expressão corretos em 70%, enquanto nos 30% restantes usou expressões aceitáveis que não são amplamente usadas ou percebidas como a fala nativa natural.
A tabela abaixo contém a análise de dados brutos.
Avaliação da Avaliação dos GPTs

Análise e Principais Descobertas
- O Google Tradutor obtém apenas uma tradução correta e chega perto do significado em 2 frases.
- A Amazon deu 50% de significado correto, mesmo que não use a maneira mais comum de transmitir o ditado em inglês na língua italiana.
- A Microsoft deu 3 respostas corretas, aproximando-se de ditados semelhantes italianos.
- Embora o 1º Chat GPT geralmente aprove traduções de máquina, o 2º e o 3º Chat GPT geralmente fornecem o significado correto e adicionam sugestões valiosas de tradução.
Aplicações práticas e limitações
Conforme definido por https://it.wiktionary.org/wiki/espressione_idiomatica, uma expressão idiomática típica de uma língua geralmente não pode ser traduzida literalmente para outras línguas, exceto recorrendo a expressões idiomáticas da língua para a qual é traduzida, com significados semelhantes às expressões idiomáticas da língua da qual é traduzida. Claramente, a tradução mecânica produzida pelas máquinas de tradução mais usadas hoje (Google, Amazon, Microsoft) não era confiável, no entanto, o GPT-3 provou ser capaz em 70% de dar o significado correto e fornecer boas sugestões na adaptação de conteúdo.
Não é improvável que, em um futuro próximo, as máquinas também memorizem expressões idiomáticas, mas agora precisamos que os humanos traduzam transmitindo o mesmo significado de um idioma para outro.
As línguas estão cheias de nuances, duplos sentidos, alusões, expressões idiomáticas, metáforas que só um humano pode perceber.
O coreano teve a menor precisão em todos os mecanismos testados
A análise a seguir foi escrita por nosso linguista inglês/coreano Sun Min Kim.

Saída de uma perspectiva qualitativa
A tabela abaixo apresenta uma análise sintética de 10 frases idiomáticas em inglês traduzidas para o coreano, conduzida por nossa equipe de linguistas.
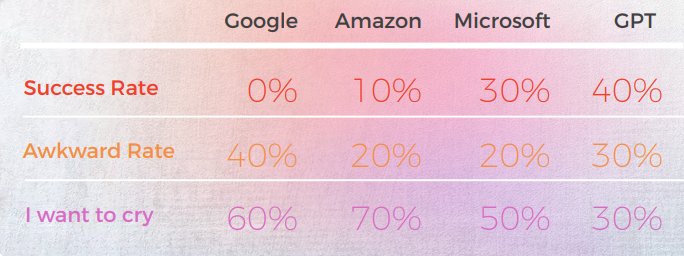
A maioria dos motores traduz literalmente as expressões idiomáticas, enquanto o GPT tenta traduzir de forma mais descritiva possível, sem usar metáforas (por exemplo, pedaço de bolo = fácil, enquanto na Coreia, temos uma expressão idiomática semelhante que transmite o mesmo significado que a Microsoft fez.
As três traduções do GPT não são consistentes. Alguns estão piorando com a iteração.
A tabela abaixo contém a análise de dados brutos.
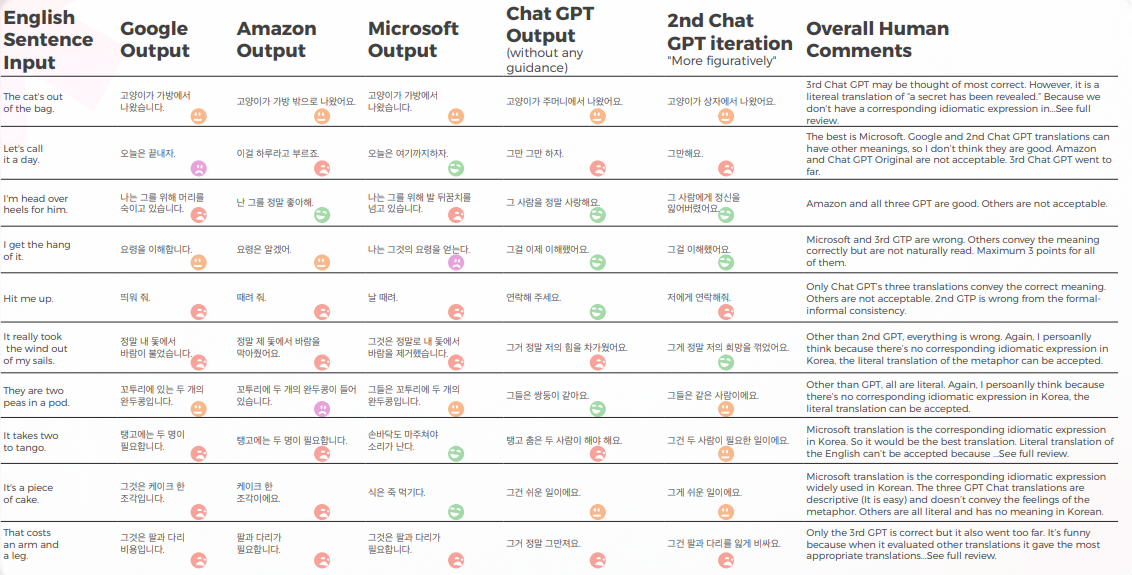
O GPT conhece os problemas quando as traduções dão errado. Mas não é considerado correto ao julgar o melhor.
O próprio GPT tem problemas com o tratamento formal – informal e assim por diante) e pode avaliar esse problema.
Avaliação da Avaliação dos GPTs

Análise e Principais Descobertas
Como os originais em inglês neste estudo são expressões idiomáticas, é um pouco complicado porque você precisa escolher entre a metáfora ou a descrição direta. Mas para algumas expressões idiomáticas em que o idioma coreano tem uma expressão idiomática semelhante que transmite o mesmo significado, a maioria dos mecanismos não conseguiu encontrar essas expressões, com apenas algumas exceções (consulte a planilha e encontre aquelas com a pontuação de 5 por mim).
Para outras, meu pensamento pessoal é que, se a própria metáfora pode transmitir o significado, a tradução literal dela pode ser considerada e talvez seja melhor usar uma palavra descritiva. Claro, se a metáfora não tem contexto cultural na Coreia, ela não deve ser traduzida literalmente. Mas é uma questão sutil e talvez dependa da preferência ou das emoções humanas do tradutor. Eu não acho que nenhum motor tenha esse nível de pensamento semelhante ao humano ainda.
Aplicações práticas e limitações
Acho que a maioria dos mecanismos pode ser usada para fins de pré-tradução. Mas, considerando a qualidade, deve ser principalmente apenas para fins de eficiência (ou seja, não digitando do zero). Para textos mais descritivos, como manuais, vejo que o MTPE é muito mais avançado do que essas expressões idiomáticas. Portanto, ainda há espaço para melhorar.
GPT atingiu 90% de taxa de sucesso em expressões idiomáticas do português brasileiro
A análise a seguir foi escrita por nosso linguista de inglês/português Gabriel Fairman.

No geral, todos os motores tiveram dificuldades com a natureza metafórica da linguagem, muitas vezes errando na literalidade excessiva.
Saída de uma perspectiva qualitativa
A tabela abaixo apresenta uma análise sintética de 10 frases idiomáticas em inglês traduzidas para o português, conduzida por nossa equipe de linguistas.
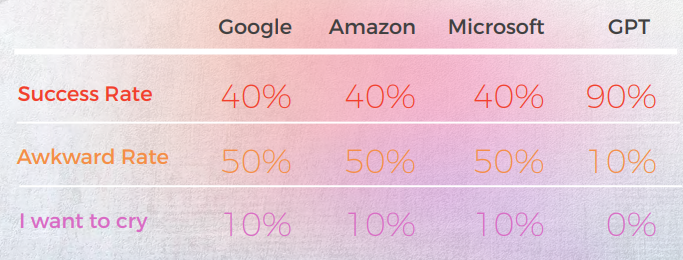
A maioria dos motores traduz literalmente as expressões idiomáticas, enquanto o GPT tenta traduzir de forma mais descritiva possível, sem usar metáforas (por exemplo, pedaço de bolo = fácil, enquanto na Coreia, temos uma expressão idiomática semelhante que transmite o mesmo significado que a Microsoft fez.
As três traduções do GPT não são consistentes. Alguns estão piorando com a iteração.
A tabela abaixo contém a análise de dados brutos.
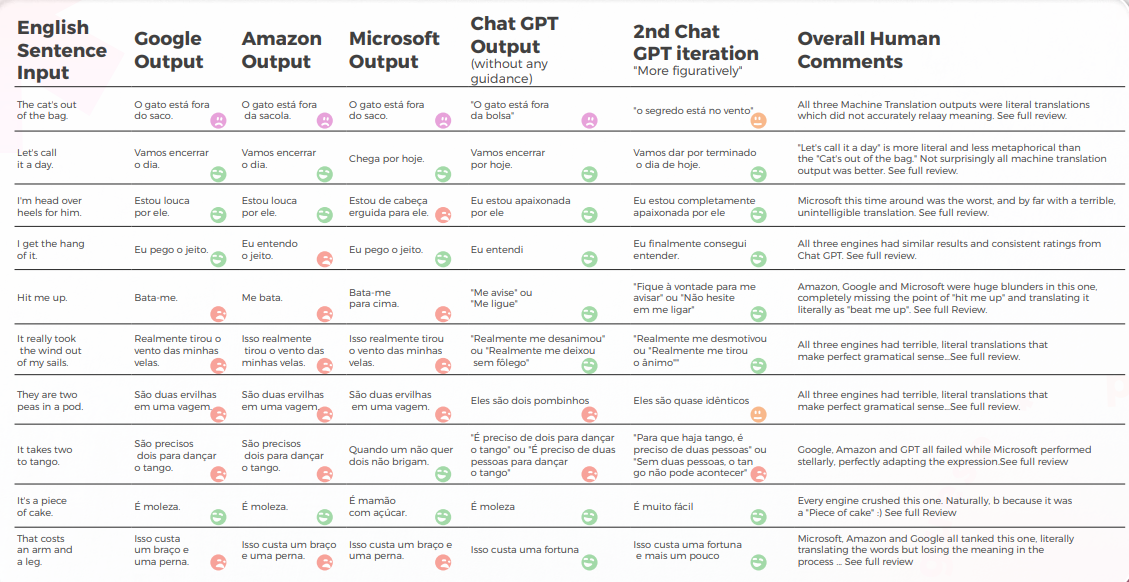
No que diz respeito à qualidade da tradução, o GPT fez um ótimo trabalho com contextualização. Em 9 de 10 frases, o conteúdo foi bem adaptado, inteligível e transmitiu o significado adequado. Ao contrário dos três motores de tradução de máquina, o GPT não cometeu erros embaraçosos de "quero chorar".
A hipótese inicial era de que haveria uma grande diferença de qualidade entre a primeira e a segunda iterações do GPT, mas a qualidade da tradução era semelhante em ambas.
Avaliação de GPTs Avaliação
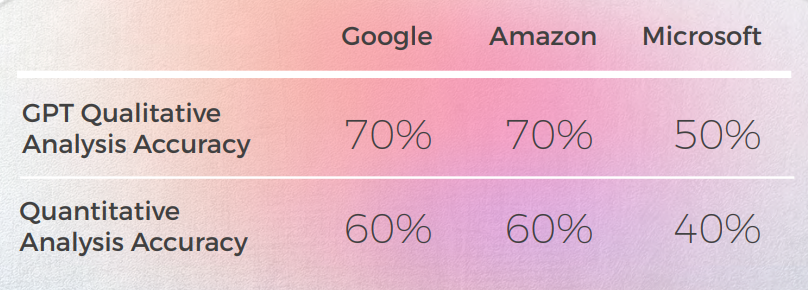
Análise e Principais Descobertas
- A Microsoft fez escolhas mais ousadas quando se trata da adaptação linguística das expressões idiomáticas.
- O GPT teve mais dificuldade em avaliar as escolhas metafóricas da Microsoft à medida que se afastavam mais.
- O Google e a Amazon tiveram resultados extremamente semelhantes, apenas ligeiramente se desviando um do outro, espelhando os erros e as escolhas metafóricas um do outro. A Microsoft claramente se destacou dos dois.
- O GPT-3 teve mais facilidade com a Análise Qualitativa, produzindo uma análise textual convincente (embora com apenas 70% de precisão).
- Embora inteligível, a análise do GPT não conseguiu identificar em 30% dos casos. Isso coincidiu com escolhas metafóricas que eram literais e compreensíveis, mas se desviavam do discurso cotidiano.
- O GPT-3 teve mais dificuldade em traduzir a análise qualitativa em uma pontuação.
- Embora as pontuações em termos gerais fossem 60% precisas, era difícil diferenciar entre pontuações semelhantes, como 3 vs. 4.
- A divergência extrema de pontuação de 1 a 5 foi mais fácil de entender e mais compatível com os comentários gerais sugerindo que:
- Talvez os critérios de pontuação não tenham sido suficientemente calibrados com o GPT-3
- Talvez a pontuação binária possa ser mais relevante do que a pontuação de gradiente. Em um caso anômalo, o Chat GPT-3 avaliou duas traduções semelhantes de maneiras radicalmente diferentes, dando a uma um 1 e à outra um 5, quando ambas deveriam ter sido 1.
- Embora quantitativamente a Microsoft tenha tido um desempenho semelhante ao do Google e da Amazon, quando você entra no âmago da questão da linguagem, a Microsoft fez escolhas mais ousadas e forneceu melhores resultados de uma perspectiva qualitativa, mas ainda estava muito atrás do GPT-3 quando se tratava de precisão e adaptação cultural.
Aplicações práticas e limitações
Nesta análise, o GPT-3 forneceu contextualização e adaptação superiores em comparação com os modelos anteriores de
tradução de máquina em português brasileiro. Embora não seja conveniente substituir modelos tradicionais de tradução de máquina por modelos maiores, como o GPT-3, devido aos altos custos computacionais e aos ganhos marginais decrescentes quando se trata de discurso não metafórico, o GPT-3 pode ser um poderoso aliado humano ao fornecer sugestões e identificar possíveis erros, bem como oportunidades de melhoria.
Os casos extremos linguísticos são surpreendentes porque ilustram claramente o quanto resta em tão pouco quando se trata de modelos de linguagem. Mesmo que eles estejam "quase" lá, esse "quase" se torna progressivamente mais difícil de lidar e, se não for mais difícil, definitivamente mais caro do ponto de vista computacional.
Embora nenhum dos mecanismos seja confiável o suficiente para substituir os humanos (pelo menos no contexto deste estudo), o GPT-3 mostra uma capacidade clara de auxiliar tradutores e revisores humanos no processo de tradução e avaliação da linguagem.
Os MTs espanhóis pontuaram abaixo de 30% - GPT foi o vencedor claro
A análise a seguir foi escrita por nosso linguista de inglês/espanhol Nicolas Davila.

No geral, todos os motores tiveram dificuldades com a natureza metafórica da linguagem, muitas vezes errando na literalidade excessiva.
Saída de uma perspectiva qualitativa
A tabela abaixo apresenta uma análise sintética de 10 frases idiomáticas em inglês traduzidas para o espanhol, conduzida por nossa equipe de linguistas.

No que diz respeito à qualidade da tradução, o GPT fez um trabalho aceitável e melhor do que os outros com contextualização. Em 7 de 10 frases, o conteúdo era inteligível, bem formado e transmitia o significado adequado, com baixo nível de estranheza e taxas de "quero chorar".
Embora a hipótese inicial fosse de que haveria uma grande diferença de qualidade entre a primeira iteração e as subsequentes do GPT, a qualidade da tradução é semelhante em todas elas, a 2ª e a 3ª iterações às vezes adicionam coisas desnecessárias, aumentando um pouco a taxa de estranheza.
A tabela abaixo contém a análise de dados brutos.
Avaliação de GPTs Avaliação

Análise e Principais Descobertas
- As traduções de MT eram muito literais, sendo a Amazon e o Google muito semelhantes em termos gerais, e a Microsoft sendo a pior.
- O Google e a Amazon tiveram resultados extremamente semelhantes, apenas ligeiramente se desviando um do outro, espelhando os erros e as escolhas metafóricas um do outro. A Microsoft teve um desempenho ruim, às vezes produzindo frases mal formadas e faltando algumas partes da construção gramatical.
- O GPT-3 teve mais facilidade com a Análise Qualitativa, produzindo uma análise textual coerente, embora com apenas 50% de precisão.
- Frequentemente, a análise qualitativa do GPT-3 era muito geral e mais restrita ao significado principal e literal da frase, sem considerar detalhes sutis de construção e mudança de significado. Parece que o GPT não é capaz de captar essas diferenças e traduzi-las em pontuações quantitativas.
- Além disso, o GPT frequentemente atribuía a mesma análise qualitativa e alta pontuação quantitativa a frases que eram gramaticalmente mal construídas, o que parece ser uma limitação do modelo do GPT.
- O GPT-3 teve mais dificuldade em traduzir a análise qualitativa em uma pontuação.
- Sendo apenas 50% preciso para Google e Amazon e apenas 30% preciso para a Microsoft. Parece que o GPT estava apenas medindo se a frase transmitia o significado, mas sem diferenças na construção ou na formação adequada.
- A divergência de pontuação de 1 a 5 foi mais fácil de entender e mais compatível com os comentários gerais que sugerem que: Talvez os critérios de pontuação não tenham sido suficientemente calibrados para o GPT-3. Talvez a pontuação binária possa ser mais relevante do que a pontuação de gradiente. Talvez os critérios de pontuação ou o modelo GPT não estivessem considerando questões gramaticais, mas apenas transmitindo significado.
Aplicações práticas e limitações
Nesta análise, o GPT-3 forneceu contextualização e adaptação superiores em comparação com modelos anteriores de tradução de máquina no espanhol da América Latina.
O GPT-3 pode ser uma ferramenta poderosa para ajudar os humanos a melhorar as traduções quando se trata de fornecer sugestões úteis e oportunidades de melhoria. Mas, até onde posso ver, ainda tem certas limitações.
Embora modelos maiores, como o GPT-3, possam ser úteis, não é conveniente substituí-los pelos modelos tradicionais de tradução de máquina, devido aos custos computacionais mais altos, já que, quando se trata de texto não metafórico, isso pode diminuir os ganhos marginais.
Embora o GPT-3 demonstre uma capacidade clara de auxiliar tradutores e revisores humanos no processo de tradução e avaliação da linguagem, considerações de custo devem ser incluídas ao avaliar seu uso para textos não metafóricos.
Conclusões
Embora o desempenho do ChatGPT possa variar dependendo do prompt e do idioma específico, nosso estudo sugere que o ChatGPT tem potencial para produzir traduções de maior qualidade do que os mecanismos tradicionais de MT, especialmente quando se trata de lidar com expressões idiomáticas e uso de linguagem diferenciada.
No entanto, é importante notar que o ChatGPT está longe de não cometer erros e ainda tem imenso espaço para melhorias, especialmente quando se trata de prompts ou domínios de linguagem mais complexos.
Como tradutor, o ChatGPT teve mais sucesso do que todos os motores de tradução de máquina testados. Embora os idiomas tenham mostrado resultados diferentes, o coreano foi claramente o outlier, com a qualidade MT e a qualidade GPT significativamente menores do que outros idiomas.
Em todos os idiomas, exceto coreano, o ChatGPT teve pelo menos uma taxa de sucesso de 70% e, no máximo, uma taxa de sucesso de 90%, apresentando um desempenho melhor do que o MT tradicional. E mesmo em coreano, embora as pontuações fossem baixas, elas ainda eram melhores do que a saída do motor de tradução automática.
Ao contrário da tradução de máquina, com um LLM, iterações do mesmo conteúdo podem melhorar a qualidade do resultado. Isso é fundamental quando se pensa em integrações, porque enquanto com o MT tradicional sua saída será sempre a mesma da sua entrada (a menos que o mecanismo obtenha mais dados ou treinamento), com um LLM pode-se explorar várias interações via API para otimizar a qualidade do feed.
Uma vantagem do ChatGPT sobre os mecanismos tradicionais de MT é sua capacidade de aprender e melhorar com o tempo, mesmo sem dados de treinamento adicionais. Isso se deve à natureza dos LLMs, que são projetados para refinar continuamente seus modelos de linguagem com base em novas entradas. Como tal, o ChatGPT pode oferecer recursos de tradução mais adaptáveis e dinâmicos, o que pode ser especialmente útil em cenários em que o idioma ou o conteúdo está em constante evolução ou mudança.
Outra vantagem do ChatGPT é sua baixa taxa de constrangimento, que é uma melhoria significativa em relação aos mecanismos tradicionais de MT que frequentemente produzem traduções estranhas ou inadequadas. Isso pode tornar o ChatGPT mais aceitável e fácil de usar para usuários não especialistas que podem não ter o mesmo nível de conhecimento linguístico ou cultural que os tradutores profissionais.
No entanto, é importante observar que o ChatGPT não substitui os tradutores humanos e há uma infinidade de casos em que a experiência e o julgamento de um tradutor humano são necessários. Mas as taxas de constrangimento significativamente mais baixas do ChatGPT abrem caminho para uma adoção mais ampla de traduções feitas por não humanos.
Como avaliador, o desempenho do ChatGPT foi mais misto, com taxas de precisão variando de 30% a 70%. Embora isso sugira que o ChatGPT pode não ser tão eficaz na avaliação de outros mecanismos de tradução quanto na sugestão de traduções, é possível que isso se deva à complexidade e qualidade dos prompts de avaliação, que podem exigir conhecimento mais especializado ou contextual do que o ChatGPT possui atualmente. Mais pesquisas são necessárias para explorar o potencial do ChatGPT como avaliador, bem como suas limitações e desafios.
No geral, nosso estudo sugere que o ChatGPT possui capacidades de tradução promissoras que valem a pena explorar mais. Embora possa não ser capaz de substituir ou ignorar totalmente os tradutores humanos, pode oferecer benefícios significativos como uma ferramenta de auxílio ou pré-tradução, especialmente em cenários em que o tempo, os recursos ou a experiência são limitados.
Como acontece com qualquer tecnologia emergente, ainda existem muitos desafios e oportunidades de melhoria, e mais pesquisas e experimentações serão necessárias para liberar totalmente seu potencial.
Metodologia
Para explorar como modelos de linguagem como o GPT-3 lidam com tradução idiomática em comparação com motores tradicionais de tradução de máquina, conduzimos um experimento focado em casos extremos linguísticos envolvendo metáforas e expressões idiomáticas.
Seleção de Expressões Idiomáticas
Selecionamos 10 expressões idiomáticas em inglês comumente usadas, como “Let’s call it a day,” “Hit me up,” e “The CAT’s out of the bag.” Essas expressões são bem conhecidas por desafiar os sistemas de tradução, pois exigem adaptação cultural e contextual em vez de equivalência literal.
Mecanismos e modelos de tradução testados
Cada idioma foi traduzido usando:
- Google Tradutor
- Amazon Translate
- Microsoft Translator
- GPT-3 (ChatGPT) – usando duas abordagens:
- Uma tradução direta sem qualquer orientação
- Uma segunda versão solicitada a ser mais figurativa e idiomática

Processo de Avaliação
Os resultados traduzidos foram revisados por linguistas nativos em sete idiomas de destino: Português do Brasil, Espanhol, Francês, Alemão, Italiano, Chinês e Coreano. Para cada frase, os revisores avaliaram:
- Se o significado da expressão original foi preservado
- A naturalidade da expressão no idioma de destino
- Gramática, sintaxe e precisão semântica
Cada tradução foi classificada em uma escala de 1 a 5:
- 5: Significado correto e linguagem que soa natural
- 1: Tradução incorreta, confusa ou não natural (nível "I want to cry")
Além disso, pedimos ao ChatGPT que avaliasse as traduções dos outros mecanismos, fornecendo feedback textual qualitativo e pontuações numéricas. Isso nos permitiu avaliar sua capacidade como avaliador, não apenas como gerador de tradução.
Limitações do estudo
É importante notar que este foi um estudo exploratório:
- A amostra foi limitada a 10 idiomas com um revisor humano por idioma.
- Todas as avaliações carregam um grau de subjetividade e preferência individual.
- O desempenho do GPT-3 reflete uma versão específica do modelo e pode evoluir com atualizações.
Apesar dessas restrições, as descobertas fornecem informações valiosas sobre as capacidades e limitações dos modelos atuais, especialmente em cenários com nuances linguísticas e culturalmente dependentes.
Isenções de responsabilidade
(Isenções de responsabilidade de pesquisa real não devem ser tomadas de ânimo leve)
Embora nosso objetivo fosse explorar o potencial das capacidades linguísticas do ChatGPT, é importante observar que este estudo avaliou apenas um aspecto da tradução, ou seja, a capacidade de lidar com casos extremos linguísticos idiomáticos altamente metafóricos. Outros aspectos da tradução, como a compreensão cultural e contextual, podem exigir diferentes métodos e critérios de avaliação.
O tamanho da amostra deste estudo é limitado a 10 expressões idiomáticas e um revisor por idioma, o que pode não ser representativo de toda a gama de expressões idiomáticas na língua inglesa, ou da variedade de perspectivas e conhecimentos de tradutores profissionais. Como tal, os resultados deste estudo devem ser interpretados com cautela e não podem ser generalizados para outros contextos ou domínios.
Além disso, as opiniões e avaliações do revisor único por idioma são subjetivas e podem ser influenciadas por preconceitos, experiências ou preferências pessoais. Como em qualquer avaliação subjetiva, há um grau de variabilidade e incerteza nos resultados. Para aumentar a confiabilidade e a validade de nossos achados, estudos futuros podem envolver vários revisores, avaliações cegas ou medidas de confiabilidade entre avaliadores.
Também é importante notar que os recursos de linguagem do ChatGPT não são estáticos e podem mudar com o tempo, à medida que o modelo é treinado e ajustado. Portanto, os resultados deste estudo devem ser considerados como um instantâneo do desempenho do modelo em um ponto específico no tempo e podem não refletir suas capacidades atuais ou futuras.
Por fim, este estudo não se destina a fazer afirmações definitivas ou categóricas sobre a utilidade ou limitações do ChatGPT para tradução. Em vez disso, destina-se a servir como uma investigação preliminar e ponto de partida para futuras pesquisas e desenvolvimento no campo do processamento de linguagem natural e tradução de máquina. Como acontece com qualquer tecnologia emergente, ainda existem muitos desafios e oportunidades de melhoria, e mais experimentação e colaboração serão necessárias para explorar totalmente seu potencial.
Desbloqueie o poder da glocalização com nosso Sistema de Gerenciamento de Tradução.
Desbloqueie o poder da
com nosso Sistema de Gerenciamento de Tradução.








