

Traducción contextual con Modelos de Lenguaje Grandes


La traducción automática tradicional ha sido problemática durante mucho tiempo, incluso con la introducción de la traducción automática neuronal y grandes conjuntos de datos de entrenamiento. Aunque puede producir resultados interesantes cuando se ajusta y entrena finamente para un dominio específico con un lenguaje predecible y sencillo, generalmente es poco confiable y errático cuando se aplica a una variedad de dominios, idiomas y circunstancias.
Muchos traductores de renombre todavía desaprueban la traducción automática y se niegan a usarla como borrador inicial o a reescribir completamente los textos. Esto resalta la brecha entre las máquinas y los humanos, incluso con la inmensa evolución de la traducción automática en los últimos años. Basado en nuestras encuestas, solo un pequeño porcentaje de traductores considera la traducción automática como un aliado valioso.
La traducción automática tradicional es demasiado genérica e impredecible o demasiado específica, requiriendo circunstancias específicas para ser efectiva, como grandes volúmenes de contenido con una estructura lingüística simple o una segregación de dominio como manuales técnicos, bases de conocimiento de productos y literatura de soporte. Incluso los motores entrenados tienen dificultades para manejar inconsistencias y discrepancias entre bases terminológicas, memorias de traducción y entrenamiento de corpus lingüísticos.
Estos incluyen glosarios actualizados por revisores o traductores de la empresa después del proceso de entrenamiento, diferencias entre glosarios y corpus de entrenamiento, la necesidad de crear y mantener motores específicos para obtener la máxima calidad, memoria de traducción desviaciones del corpus entrenado y errores tontos como traducir entidades u otros nombres propios, y falta de sensibilidad cultural o lingüística.
Estos ejemplos resultan en flujos poco confiables y un proceso de revisión desafiante para los traductores. Además, gestionar modelos de traducción automática afinados y entrenados normalmente requiere uno o más ingenieros de localización dedicados a estos esfuerzos, algo que la mayoría de las agencias de traducción y programas de localización pequeños y medianos no tienen la capacidad para hacer.
Sin embargo, la traducción consciente del contexto con Grandes Modelos de Lenguaje cambia esto. El contexto se refiere a toda la información que no es el texto en sí, pero que ayuda al motor a entender el texto y cómo procesarlo. Ejemplos de contexto son glosarios, memorias de traducción, retroalimentación pasada y tasa de rebote, pero el contexto puede ser cualquier información. Con los Modelos de Lenguaje Grandes que pueden tener en cuenta miles de millones de parámetros por diseño, realmente no hay límite en cuanto al contexto con el que decidas trabajar.Aquí tienes un ejemplo de cómo tener en cuenta el contexto:

Observa cómo hay un 89% de Alimentación de la Memoria de Traducción y una Alimentación de Traducción Automática. La alimentación de la MT llama a nuestro "motor" un "mecanismo" en portugués, mientras que la TM lo llama un "motor" en portugués. Sin embargo, el glosario especifica que "motor" debe mantenerse como "motor". Cuando se procesa a través de BWX Translate, nuestro modelo tiene en cuenta esta preferencia (junto con otras):
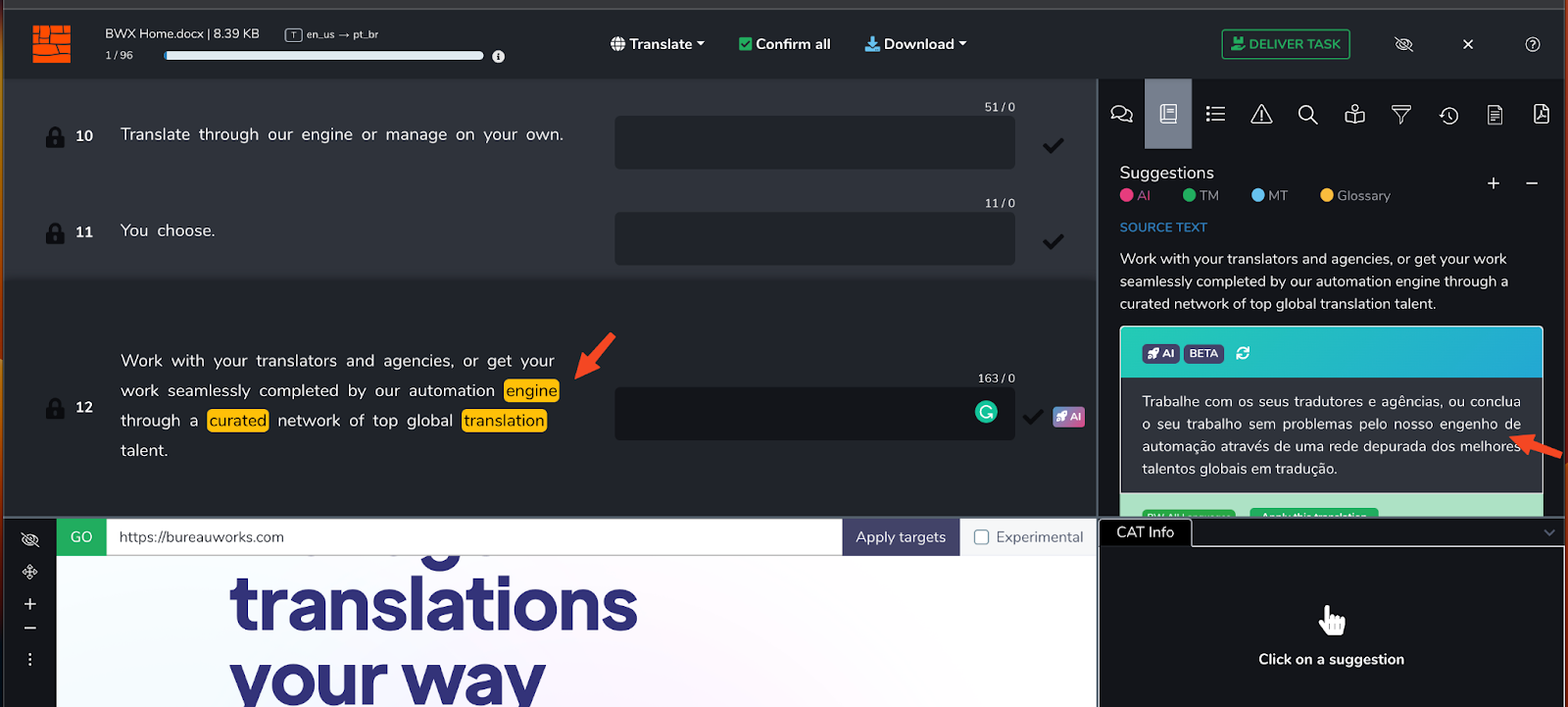
BWX Translate no solo inserta el término correcto según la última versión del glosario, sino que también realiza los cambios necesarios en el texto para que se lea bien en el idioma de destino, teniendo en cuenta el contexto lingüístico ofrecido por la Memoria de Traducción.
Con BWX Translate, los Modelos de Lenguaje Grandes como ChatGPT pueden tener en cuenta su propio conjunto de datos de entrenamiento, memorias de traducción específicas, glosarios y otros contextos relevantes para ofrecer a los traductores una alimentación de traducción matizada, contextualizada y consciente en un proyecto determinado. Podemos tener en cuenta las últimas actualizaciones de glosarios y memorias de traducción en tiempo real, lo que significa que no es necesario enviar repetidamente glosarios y traducciones actualizadas a servidores de traducción automática entrenados y ajustados para esperar que tengan en cuenta las preferencias lingüísticas.
Con BWX Translate, puedes entrenar y traducir sobre la marcha, y cualquier proyecto de traducción, cualquier tamaño de memoria de traducción y cualquier tamaño de glosario puede beneficiarse de sus capacidades de fusión textual y probabilísticas lingüísticas. Podemos tener en cuenta las últimas actualizaciones de glosarios y memorias de traducción en tiempo real, lo que significa que no es necesario enviar glosarios y traducciones actualizadas repetidamente a servidores de traducción automática entrenados y ajustados para esperar que tengan en cuenta las preferencias lingüísticas. Con BWX Translate, puedes entrenar y traducir sobre la marcha, y cualquier proyecto de traducción, cualquier memoria de traducción de cualquier tamaño y cualquier glosario de cualquier tamaño pueden beneficiarse de sus capacidades de fusión textual y probabilísticas lingüísticas. No hay tiempo de configuración y no es necesario entrenar previamente. Basado en nuestra investigación inicial, un motor como este puede proporcionar a los traductores flujos de trabajo que rompen la resistencia de larga data hacia el uso de la salida de las máquinas.
Según nuestra investigación inicial, un motor como este puede proporcionar a los traductores con información que rompa la resistencia de mucho tiempo hacia el uso de la salida de las máquinas. Nuestro motor también abre la puerta a una conversación entre el traductor y la máquina. Tiene más sentido enriquecer un glosario si se beneficia de él al instante, y es más fácil confiar en una máquina si se sabe por experiencia que al menos hay algo que se asemeja al pensamiento crítico y adaptativo.
Además de la traducción consciente del contexto, también hemos abierto la puerta para que los traductores interactúen con modelos de lenguaje para que puedan obtener una segunda opinión sobre sus elecciones, sugerencias alternativas e incluso iniciar una conversación cuando sea necesario.
La traducción consciente del contexto con Modelos de Lenguaje Grandes es más que un proceso de pretraducción mejorado. Es un paso firme hacia la colaboración entre humanos y máquinas para producir un contenido de mejor calidad con menos esfuerzo y en menos tiempo.
En el futuro, el contexto seguirá expandiéndose de formas sin precedentes y podremos redactar textos multilingües teniendo en cuenta el comportamiento del usuario, la analítica web y una gran cantidad de otras fuentes de información que pueden ser consumidas y comprendidas por los grandes modelos de lenguaje. Esto es solo el comienzo y ya ha cambiado todo.


.jpg)

.jpg)








