

Kontextbewusste Übersetzung mit großen Sprachmodellen


Die traditionelle maschinelle Übersetzung war schon lange Zeit problematisch, selbst mit der Einführung der neuronalen maschinellen Übersetzung und großer Trainingsdatensätze. Obwohl sie interessante Ergebnisse liefern kann, wenn sie fein abgestimmt und für einen bestimmten Bereich mit vorhersehbarer und einfacher Sprache trainiert wird, ist sie im Allgemeinen unzuverlässig und unberechenbar, wenn sie auf verschiedene Bereiche, Sprachen und Umstände angewendet wird.
Viele angesehene Übersetzer mögen maschinelle Übersetzung immer noch nicht und lehnen es ab, sie als ersten Entwurf zu verwenden oder die Feeds vollständig neu zu schreiben. Dies unterstreicht die Kluft zwischen Maschinen und Menschen, selbst mit der immensen Entwicklung der maschinellen Übersetzung in den letzten Jahren. Basierend auf unserer Umfrage betrachtet nur ein kleiner Prozentsatz der Übersetzer maschinelle Übersetzung als wertvollen Verbündeten.
Traditionelle maschinelle Übersetzung ist entweder zu allgemein und unzuverlässig oder zu spezifisch und erfordert bestimmte Umstände, um effektiv zu sein, wie zum Beispiel große Mengen an Inhalten mit einfacher sprachlicher Struktur oder Domänentrennung wie technische Handbücher, Produktwissensdatenbanken und Support-Literatur. Basierend auf unseren Umfragen betrachtet nur ein kleiner Prozentsatz der Übersetzer die maschinelle Übersetzung als wertvollen Verbündeten. Die traditionelle maschinelle Übersetzung ist entweder zu allgemein und unzuverlässig oder zu spezifisch und erfordert bestimmte Umstände, um effektiv zu sein, wie zum Beispiel große Mengen an Inhalten mit einfacher sprachlicher Struktur oder Domänentrennung wie technische Handbücher, Produktwissensdatenbanken und Support-Literatur. Selbst geschulte Engines haben Schwierigkeiten, Inkonsistenzen und Unterschiede zwischen Term-Basen, Übersetzungsspeichern und linguistischen Korpus-Trainings zu bewältigen. Dazu gehören aktualisierte Glossare von Unternehmensprüfern oder Übersetzern nach dem Schulungsprozess, Unterschiede zwischen Glossaren und Trainingskorpus, die Notwendigkeit, spezifische Engines für maximale Qualität zu erstellen und zu pflegen, Abweichungen von der geschulten Korpus in Übersetzungsspeichern und dumme Fehler wie die Übersetzung von Entitäten oder anderen Eigennamen sowie mangelnde kulturelle oder sprachliche Sensibilität.
Dazu gehören aktualisierte Glossare von Unternehmensprüfern oder Übersetzern nach dem Schulungsprozess, Unterschiede zwischen Glossaren und Trainingskorpus, die Notwendigkeit, spezifische Maschinen für maximale Qualität zu erstellen und zu pflegen, Übersetzungsspeicher Abweichungen vom geschulten Korpus und dumme Fehler wie die Übersetzung von Entitäten oder anderen Eigennamen sowie mangelnde kulturelle oder sprachliche Sensibilität.
Diese Beispiele führen zu unzuverlässigen Ergebnissen und einem anspruchsvollen Überprüfungsprozess für Übersetzer. Darüber hinaus erfordert die Verwaltung von abgestimmten und trainierten maschinellen Übersetzung Modellen in der Regel einen oder mehrere spezialisierte Lokalisierungsingenieure, was den meisten kleinen und mittelgroßen Übersetzungsagenturen und Lokalisierungsprogrammen nicht möglich ist.
Context-aware translation mit Large Language Models ändert dies jedoch. Der Kontext bezieht sich auf alle Informationen, die nicht der Text selbst sind, aber dem Motor helfen, den Text zu verstehen und zu verarbeiten. Beispiele für Kontext sind Glossare, Übersetzungserinnerungen, früheres Feedback und Absprungrate, aber Kontext kann jede Information sein. Mit großen Sprachmodellen, die von Natur aus Milliarden von Parametern berücksichtigen können, gibt es wirklich keine Begrenzung dafür, wie viel Kontext Sie verwenden möchten.
Hier ist ein Beispiel, wie der Kontext berücksichtigt wird:

Beachten Sie, wie es einen 89% Translation Memory-Feed und einen maschinelle Übersetzung-Feed gibt. Der TM-Feed bezeichnet unseren "Engine" als "Motor" auf Portugiesisch, während der MT den Motor als "Mechanismus" auf Portugiesisch bezeichnet. Das Glossar gibt jedoch an, dass "Engine" als "Engine" beibehalten werden soll. Wenn unser Modell durch BWX Translate verarbeitet wird, berücksichtigt es diese Präferenz (zusammen mit anderen):
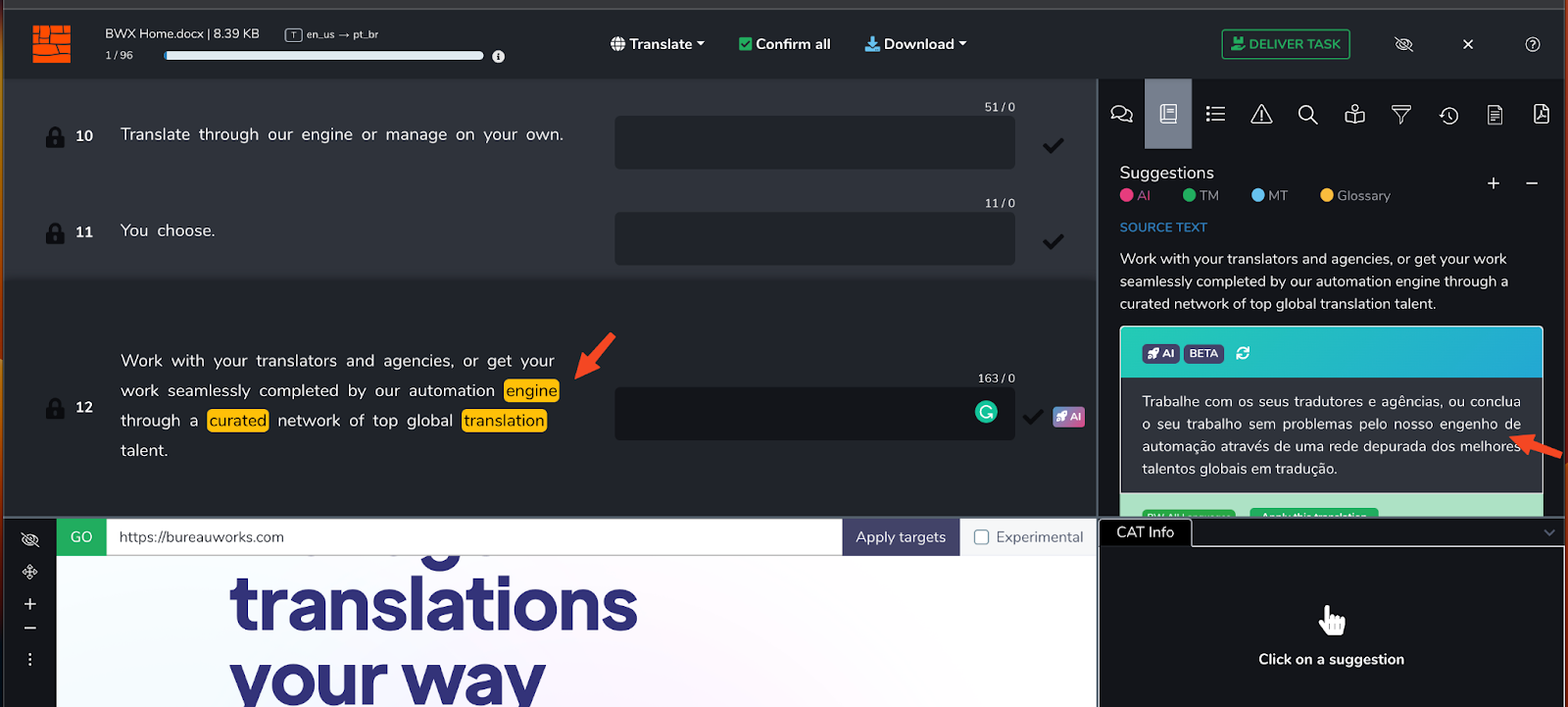
BWX Translate fügt nicht nur den korrekten Begriff gemäß der neuesten Glossarversion ein, sondern nimmt auch alle erforderlichen Änderungen am Text vor, damit er in der Zielsprache gut lesbar ist und berücksichtigt dabei den sprachlichen Kontext, der durch das Translation Memory geboten wird.
Mit BWX Translate können große Sprachmodelle wie ChatGPT ihre eigenen Trainingsdatensätze, spezifische Übersetzungsspeicher, Glossare und andere relevante Kontextinformationen berücksichtigen, um Übersetzern eine nuancierte, kontextualisierte und aufmerksame Übersetzungsunterstützung in einem bestimmten Projekt zu bieten. Wir können die neuesten Aktualisierungen von Glossaren und Übersetzungsspeichern in Echtzeit berücksichtigen, was bedeutet, dass es nicht notwendig ist, aktualisierte Glossare und Übersetzungen wiederholt an trainierte und abgestimmte maschinelle Übersetzungsserver zu senden, in der Hoffnung, dass sie die sprachlichen Vorlieben berücksichtigen.
Mit BWX Translate können Sie sofort trainieren und übersetzen, und jedes Übersetzungsprojekt, jeder beliebige Übersetzungsspeicher und jedes beliebige Glossar kann von seinen textuellen Zusammenführungs- und sprachlichen Wahrscheinlichkeitsfähigkeiten profitieren. Es gibt keine Einrichtungszeit und keine Notwendigkeit, vorher zu trainieren.
Basierend auf unserer anfänglichen Forschung kann eine solche Engine Übersetzern Feeds liefern, die den langjährigen Widerstand gegen die Nutzung von maschineller Ausgabe durchbrechen. Unser Motor öffnet auch die Tür zu einem Gespräch zwischen dem Übersetzer und dem Motor. Es macht mehr Sinn, ein Glossar zu bereichern, wenn man sofort davon profitiert, und es ist einfacher, einer Maschine zu vertrauen, wenn man aus Erfahrung weiß, dass zumindest etwas Ähnliches wie kritisches und anpassungsfähiges Denken vorhanden ist.
Neben der kontextbewussten Übersetzung haben wir auch die Tür für Übersetzer geöffnet, um mit Sprachmodellen zu interagieren, damit sie eine zweite Meinung zu ihren Entscheidungen, alternative Vorschläge und sogar eine Unterhaltung starten können, wenn nötig.
Kontextbewusste Übersetzung mit großen Sprachmodellen ist mehr als ein verbessertes Vorübersetzungsverfahren. Es ist ein fester Schritt hin zu einer Zusammenarbeit von Menschen und Maschinen, um bessere Inhalte mit weniger Aufwand und in kürzerer Zeit zu produzieren.
In Zukunft wird sich der Kontext auf bisher ungekannte Weise erweitern und wir werden in der Lage sein, mehrsprachige Texte unter Berücksichtigung des Nutzerverhaltens, der Webanalyse und einer Vielzahl anderer Informationsquellen zu erstellen, die von großen Sprachmodellen verstanden und verarbeitet werden können. Das ist erst der Anfang und es hat bereits alles verändert.


.jpg)

.jpg)








