
Translate twice as fast impeccably
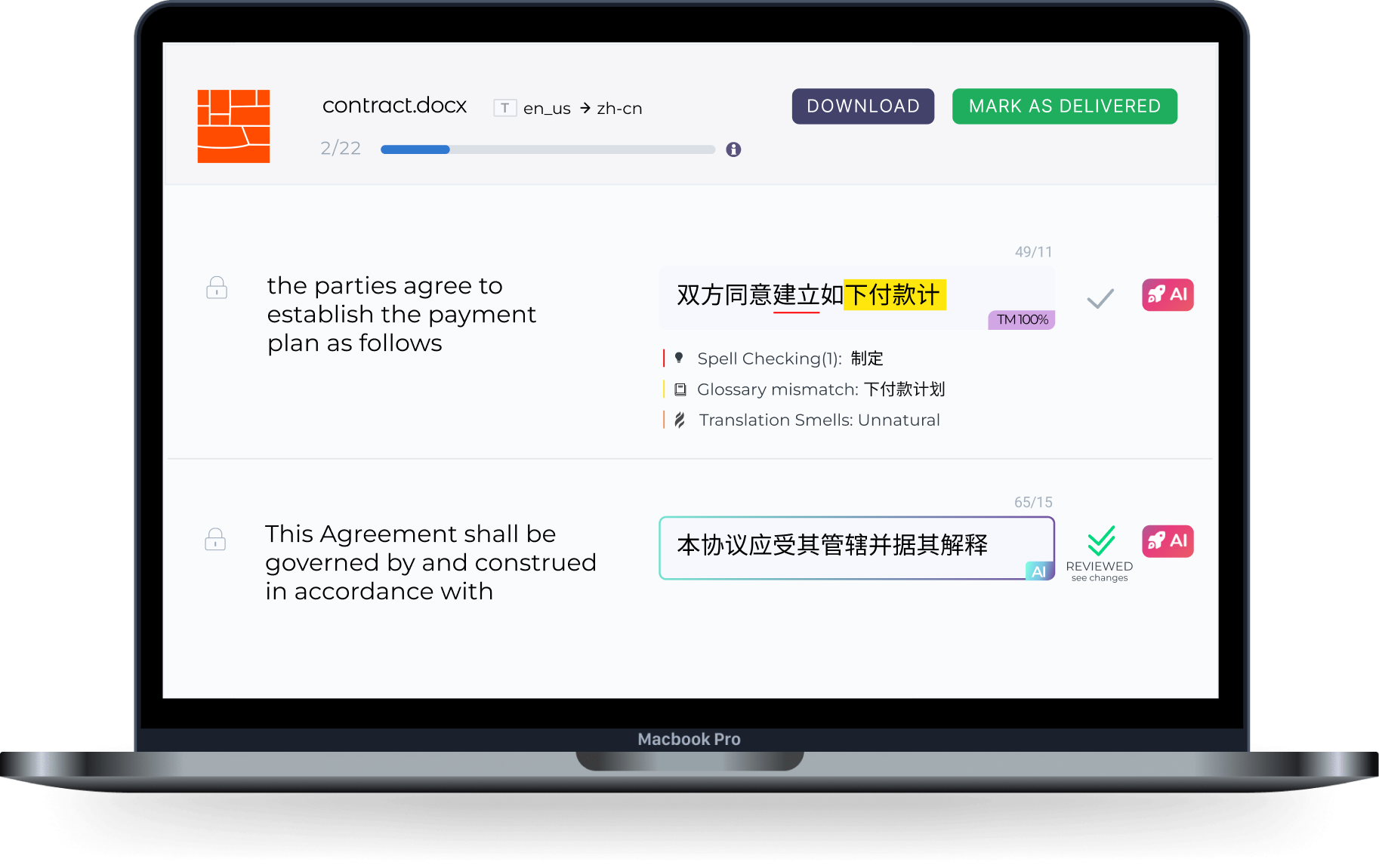
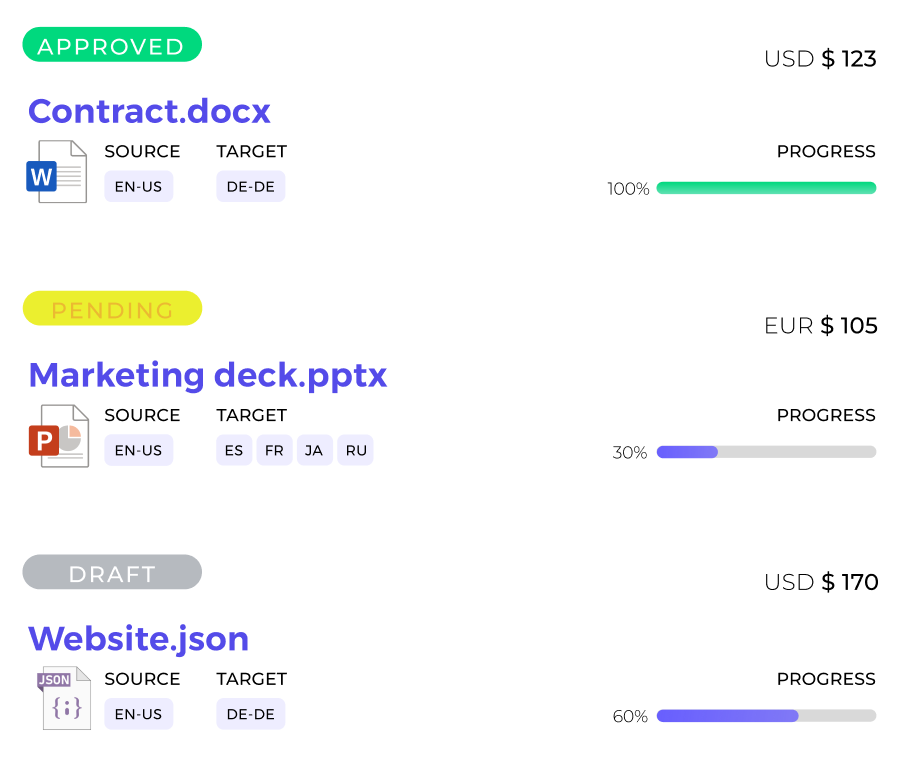
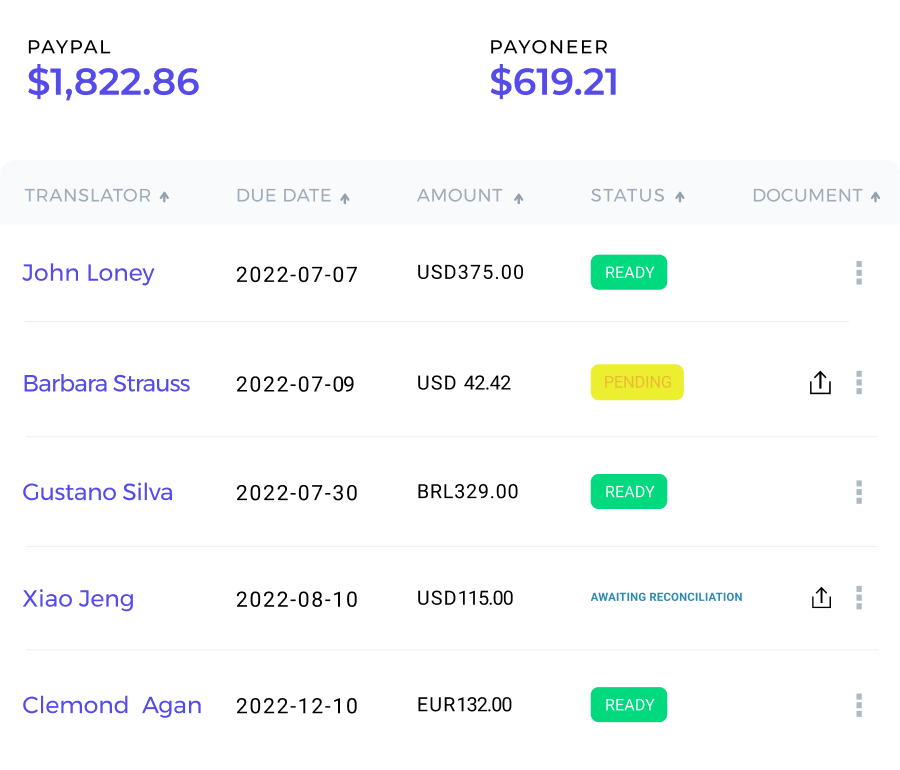
Our tech allows you to translate faster and better than ever before through the best of machine learning. It's the most sophisticated Post-AI editing environment. We enable you to automate and integrate all fundamental concepts of translation and localization. Simple, inexpensive and amazing.

.png)
.png)
.png)












.png)

%20(1).png)











.png)





